

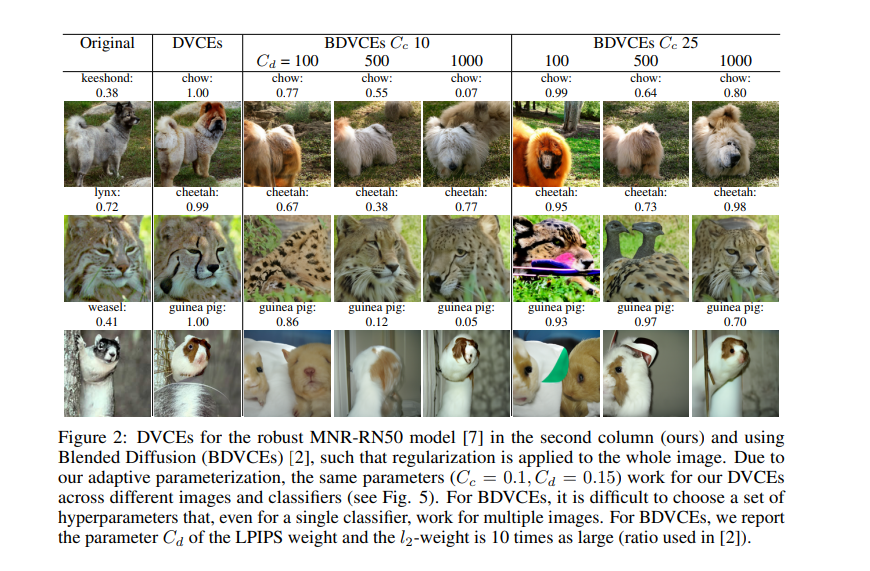
视觉反事实解释(VCEs)是理解图像分类器决策的重要工具。它们是“小”但“现实”的图像语义变化,改变了分类器的决策。当前生成VCEs的方法局限于对抗鲁棒模型,通常包含非现实的人工制品,或者局限于类别较少的图像分类问题。在本文中,我们通过扩散过程为任意ImageNet分类器生成扩散视觉反事实解释(DVCEs)来克服这一问题。对扩散过程的两个修改是我们的DVCEs的关键:首先,自适应参数化,其超参数在所有图像和模型中都具有泛化性,再加上距离正则化和扩散过程的后期开始,使我们能够生成对原始图像具有最小语义变化但分类不同的图像。其次,我们通过对抗鲁棒模型的锥正则化确保扩散过程不会收敛到琐细的非语义变化,而是生成目标类的真实图像,分类器获得了高可信度。代码可在https://github.com/valentyn1boreiko/DVCEs下获得。
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2022年12月6日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年12月6日