
机器学习在许多部署的决策系统中发挥着作用,其方式通常是人类利益相关者难以理解或不可能理解的。以一种人类可以理解的方式解释机器学习模型的输入和输出之间的关系,对于开发可信的基于机器学习的系统是至关重要的。一个新兴的研究机构试图定义机器学习的目标和解释方法。在本文中,我们试图对反事实解释的研究进行回顾和分类,这是一种特殊类型的解释,它提供了在模型输入以特定方式改变时可能发生的事情之间的联系。机器学习中反事实可解释性的现代方法与许多国家的既定法律原则相联系,这使它们吸引了金融和医疗等高影响力领域的实地系统。因此,我们设计了一个具有反事实解释算法理想性质的准则,并对目前提出的所有反事实解释算法进行了综合评价。我们的标题便于比较和理解不同方法的优缺点,并介绍了该领域的主要研究主题。我们也指出了在反事实解释空间的差距和讨论了有前途的研究方向。
机器学习作为一种在许多领域实现大规模自动化的有效工具,正日益被人们所接受。算法能够从数据中学习,以发现模式并支持决策,而不是手工设计的规则。这些决定可以并确实直接或间接地影响人类;备受关注的案例包括信贷贷款[99]、人才资源[97]、假释[102]和医疗[46]的申请。在机器学习社区中,新生的公平、责任、透明度和伦理(命运)已经成为一个多学科的研究人员和行业从业人员的团体,他们感兴趣的是开发技术来检测机器学习模型中的偏见,开发算法来抵消这种偏见,为机器决策生成人类可理解的解释,让组织为不公平的决策负责,等等。
对于机器决策,人类可以理解的解释在几个方面都有优势。例如,关注一个申请贷款的申请人的用例,好处包括:
-
对于生活受到该决定影响的申请人来说,解释是有益的。例如,它帮助申请人理解他们的哪些因素是做出决定的关键因素。
-
此外,如果申请人觉得受到了不公平待遇,例如,如果一个人的种族在决定结果时至关重要,它还可以帮助申请人对决定提出质疑。这对于组织检查其算法中的偏见也很有用。
-
在某些情况下,解释为申请人提供了反馈,他们可以根据这些反馈采取行动,在未来的时间内获得预期的结果。
-
解释可以帮助机器学习模型开发人员识别、检测和修复错误和其他性能问题。
-
解释有助于遵守与机器生产决策相关的法律,如GDPR[10]。
机器学习中的可解释性大体上是指使用固有的可解释的透明模型或为不透明模型生成事后解释。前者的例子包括线性/逻辑回归、决策树、规则集等。后者的例子包括随机森林、支持向量机(SVMs)和神经网络。
事后解释方法既可以是模型特定的,也可以是模型不可知的。特征重要性解释和模型简化是两种广泛的特定于模型的方法。与模型无关的方法可以分为视觉解释、局部解释、特性重要性和模型简化。
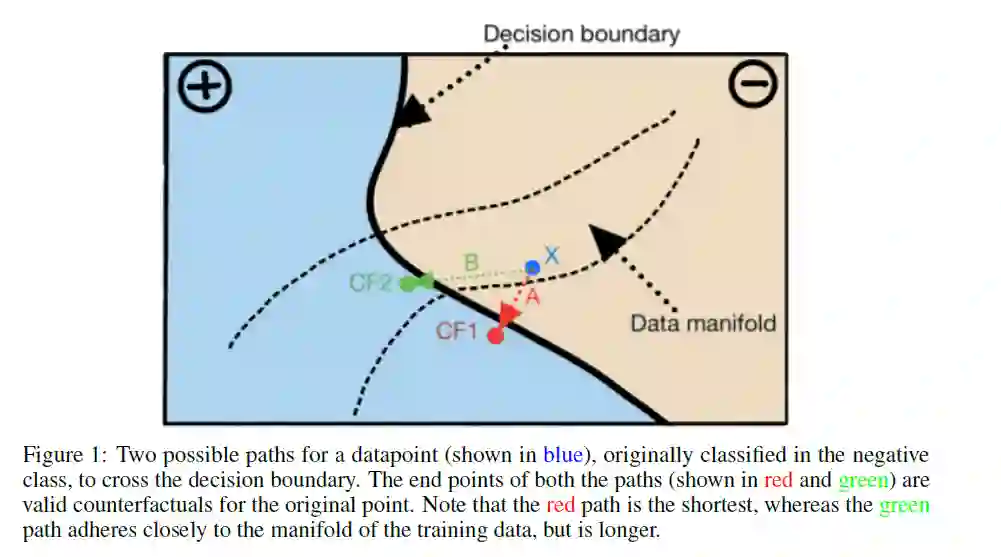
特征重要性(Feature importance)是指对模型的整体精度或某个特定决策最有影响的特征,例如SHAP[80]、QII[27]。模型简化找到了一个可解释的模型,该模型紧致地模仿了不透明模型。依存图是一种常用的直观解释,如部分依存图[51]、累积局部效应图[14]、个体条件期望图[53]。他们将模型预测的变化绘制成一个特征,或者多个特征被改变。局部解释不同于其他解释方法,因为它们只解释一个预测。局部解释可以进一步分为近似解释和基于实例的解释。近似方法在模型预测需要解释的数据点附近抽取新的数据点(以下称为explainee数据点),然后拟合线性模型(如LIME[92])或从中提取规则集(如锚[93])。基于实例的方法寻求在被解释数据点附近找到数据点。它们要么以与被解释数据点具有相同预测的数据点的形式提供解释,要么以预测与被解释数据点不同的数据点的形式提供解释。请注意,后一种数据点仍然接近于被解释的数据点,被称为“反事实解释”。
回想一下申请贷款的申请人的用例。对于贷款请求被拒绝的个人,反事实的解释为他们提供反馈,帮助他们改变自己的特征,以过渡到决策边界的理想一面,即获得贷款。这样的反馈被称为可执行的。与其他几种解释技术不同,反事实解释不能明确回答决策中的“为什么”部分;相反,他们提供建议以达到预期的结果。反事实解释也适用于黑箱模型(只有模型的预测功能是可访问的),因此不限制模型的复杂性,也不要求模型披露。它们也不一定能近似底层模型,从而产生准确的反馈。由于反事实解释具有直觉性,因此也符合法律框架的规定(见附录C)。
在这项工作中,我们收集、审查和分类了最近的39篇论文,提出了算法,以产生机器学习模型的反事实解释。这些方法大多集中在表格或基于图像的数据集上。我们在附录b中描述了我们为这项调查收集论文的方法。我们描述了这个领域最近的研究主题,并将收集的论文按照有效的反事实解释的固定需求进行分类(见表1)。
