扩散模型(DMs)在不需要对抗训练的情况下展示了最先进的内容生成性能。这些模型使用两步过程进行训练。首先,前向扩散过程逐渐向数据(通常是图像)添加噪声。然后,反向扩散过程逐步去除噪声,将其转化为被建模目标分布的样本。DMs的灵感来源于非平衡态热力学,具有固有的高计算复杂度。由于在高维空间中频繁的函数计算和梯度计算,这些模型在训练和推理阶段都会产生大量的计算开销。这不仅阻碍了扩散模型的民主化,而且阻碍了扩散模型在实际应用中的适应性。更不用说,由于过度的能源消耗和对环境的担忧,计算模型的效率正在迅速成为一个重要的问题。这些因素导致了文献中对设计计算高效的DM的多项贡献。在这篇综述中,我们介绍了视觉扩散模型的最新进展,特别关注影响DMs计算效率的重要设计方面。我们特别强调最近提出的设计选择,这些设计选择导致了更高效的DM。不像最近的其他评论,从广泛的角度讨论扩散模型,本综述旨在通过强调文献中的设计策略,推动这一研究方向向前发展,为更广泛的研究社区带来了可实施的模型。从计算效率的角度展望了视觉中扩散模型的发展前景。深度生成模型(DGMs)——已经成为人工智能中最令人兴奋的模型之一,它挑战了人类的创造力[1]。变分自编码器、生成对抗神经网络、归一化流和扩散模型的发展在人工创造力方面引起了轰动,特别是在图像嵌入任务方面。图像合成和文本到图像的生成。由于生成对抗网络(GANs)输出的高质量,近年来受到了广泛关注。然而,扩散模型最近成为最强大的生成模型,在生成质量[2]、[3]、[4]方面挑战了GANs的统治地位。扩散模型正变得越来越受欢迎,因为它们提供训练稳定性以及高质量的图像和音频生成结果。这些模型试图解决GANs的固有局限性,如由于梯度消失而导致的生成器训练可能失败、对抗性学习的开销以及其收敛失败[5]。另一方面,扩散模型使用了一种不同的策略,它涉及到用高斯噪声污染训练数据,然后学习通过反转这个噪声过程来恢复数据。扩散模型提供了额外的可伸缩性和并行性的特性,这增加了它们的吸引力。此外,随着讨论模型经过去噪的迭代和迭代,偏离现实太远的可能性也就更小。生成步骤经过每个检查点,在每个步骤中,可以向图像添加越来越多的细节。因此,最近所有超级强大的图像模型,如DALLE、Imagen或Midjourney和stable Diffusion都是基于扩散模型[6]、[7]的。
扩散模型有各种各样的应用,包括图像去噪、图像生成、时间序列生成、语义分割、图像超分辨率、大工作台机器学习、图像嵌入、决策和图像间翻译[4]。因此,自降噪扩散概率模型[8]引入以来,关于该主题的研究论文数量持续上升,每天都有新的模型被提出。然而,最近的热潮是在稳定扩散(Diffusion)引入后兴起的,这是一种机器学习、文本到图像模型,可以从自然语言描述生成数字图像。图1提供了关于扩散模型的文献的统计数据和时间轴概述,以显示它们最近在视觉界的流行程度。DMs属于概率模型的范畴,需要过多的计算资源来建模未观察到的数据细节。他们训练和评估模型,需要迭代估计(和梯度计算)的RGB图像在高维空间[9]。例如,最强大的DM训练通常需要数百个GPU天(例如150-1000 V100天),重新估计输入空间的噪声版本可能导致昂贵的推断,因此每个模型生成50,000个样本大约需要5天A100 GPU。这对研究界和一般用户有两个影响:第一,训练这样的模型需要大量的计算资源,只适用于领域的一小部分,并留下巨大的碳足迹。其次,评估一个已经训练好的模型在时间和内存方面也很昂贵,因为相同的模型架构需要连续运行大量的步骤(例如25 - 1000步)[10]。早期关于扩散模型的工作只关注于高质量的样本生成,而不考虑计算成本[8],[11],[12]。然而,在达到这一里程碑后,最近的工作集中在效率上。因此,为了解决生成过程缓慢的真正缺点,新的趋势是许多增强的工作集中于效率的提高。我们称这些模型的增强类别为有效扩散模型。在这篇综述文章中,我们基于效率的标准来评价现有的方法,而不牺牲样本的高质量。此外,我们讨论了模型速度和采样质量之间的权衡。扩散模型依赖于扩散步骤的长马尔可夫链来生成样本,因此在时间和计算方面可能相当昂贵。已经提出了新的方法,使该过程大大加快,但采样速度仍慢于GAN[13],[14]。
为什么模型效率如此重要?人工智能是能量密集型的,对人工智能的需求越高,我们使用的能源就越多。训练一个复杂的AI模型需要时间、金钱和高质量的数据[15],[16]。它也消耗能量。当我们使用能源时,它会产生二氧化碳。二氧化碳等温室气体将地球表面附近的热量困在大气中,导致全球气温升高,破坏脆弱的生态系统。OpenAI在45 tb的数据上训练了GPT-3模型[17]。英伟达使用512 V100 gpu对MegatronLM的最终版本进行了9天的训练,MegatronLM是一种与GPT-3相当但小于GPT-3的语言模型。单个V100 GPU的功耗可能高达300瓦。如果我们估计功耗为250瓦,512 V100 gpu使用128000瓦或128千瓦[18]。对MegatronLM来说,9天的跑步训练是27648千瓦时。根据美国能源情报署(US Energy Information Administration)的数据,普通家庭每年的耗电量为10649千瓦时。因此,训练最终版本的MegatronLM所需的能源几乎相当于三个房子一年的消耗。数据中心对环境的影响是最大的。
这篇综述的动机是深入探索扩散方法的设计,并强调设计选择可以提供对修正模型效率的洞察。与以往对扩散模型进行一般分类的工作不同,本文将对导致有效扩散模型和无效扩散模型的设计选择进行精确分类。这将指导未来计算机视觉任务计算效率扩散模型的研究。论文的其余部分组织如下:第二节提供了扩散模型的概述,简要说明了三个代表性的架构,第三节提供了设计选择的描述,并讨论了这些选择如何导致计算效率的设计,第四节比较了代表性的作品w.r.t质量和效率权衡。第五部分讨论了未来的工作方向,然后是结论和参考文献。
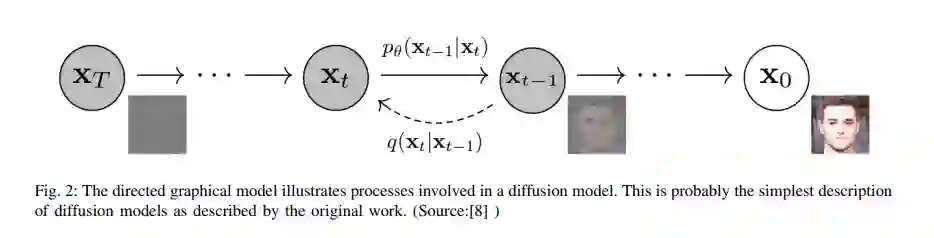
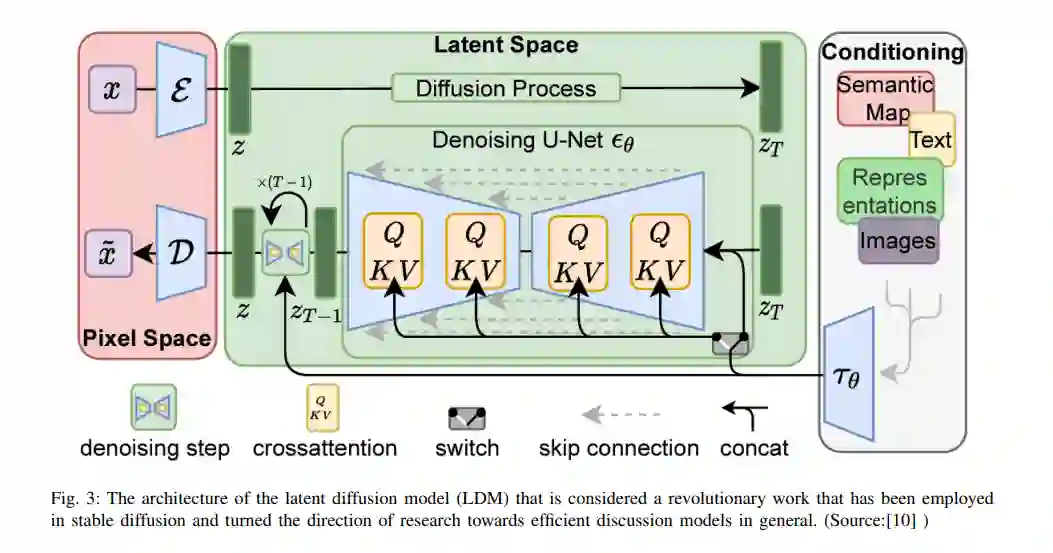
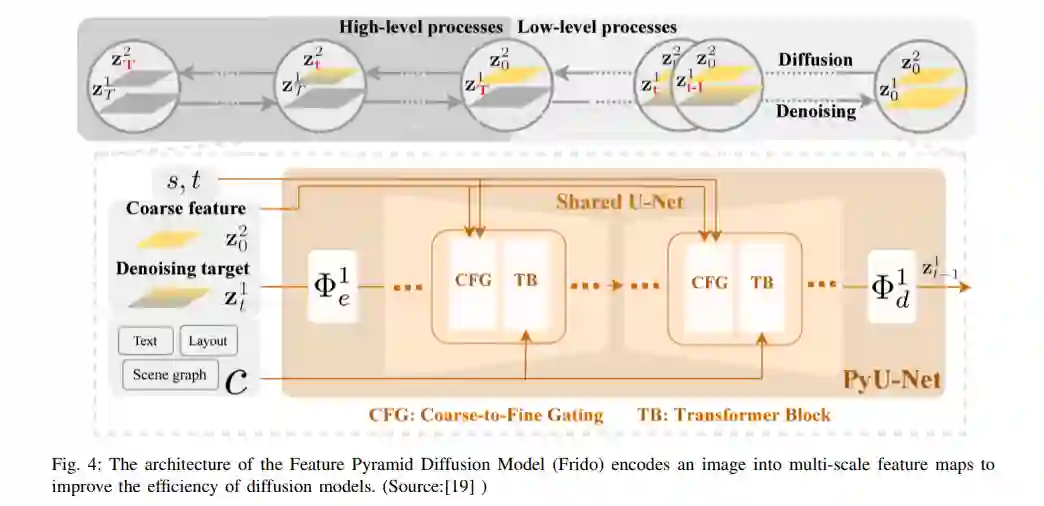
**扩散模型概述 **概率扩散模型的原始思想是从随机噪声中模拟特定的分布。因此,生成的样本的分布应该接近原始样本的分布。它包括一个正向过程(或扩散过程),其中复杂数据(通常是图像)被逐步噪声化,和一个反向过程(或反向扩散过程),其中噪声从目标分布转换回样本。在这里,由于它们对有效扩散体系结构的影响,我们特别描述了三个模型。它包括去噪扩散概率模型(DDPM)[8]、潜在扩散模型(LDM)[10]和特征金字塔潜在扩散模型[19]。
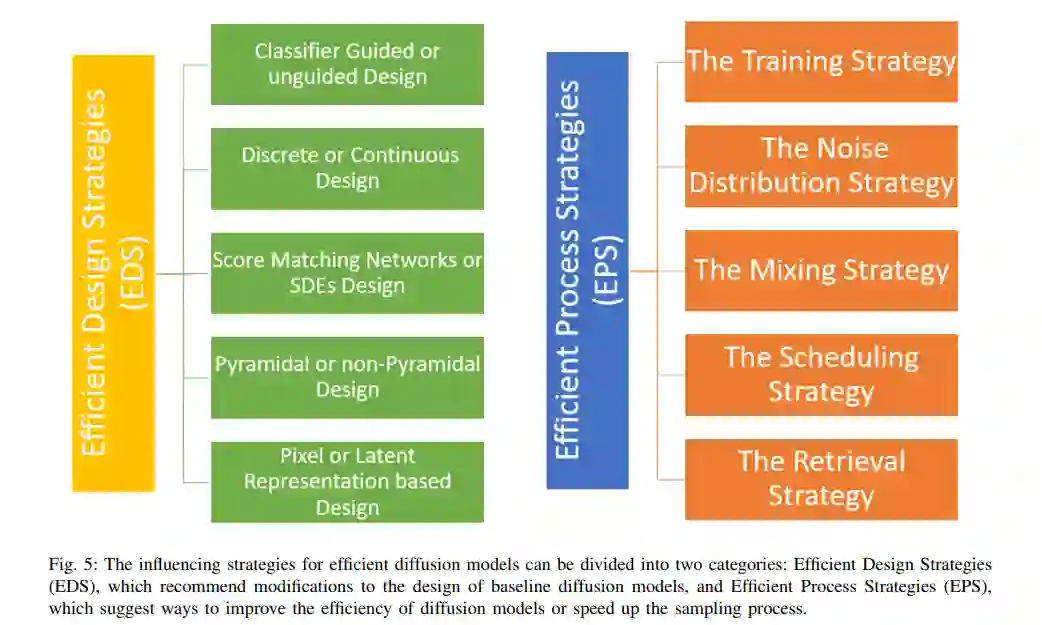
有效扩散模型的有效策略
扩散模型需要重构需要采样的数据分布。有效扩散模型的主要障碍是采样过程的低效,因为从DDPM生成样本非常慢。扩散模型依赖于扩散步骤的长马尔可夫链来生成样本,因此在时间和计算方面可能相当昂贵。近年来,为加快抽样程序作出了重大努力。我们将这些影响策略分为两类:有效设计策略(EDS)和有效过程策略(EPS),前者建议对基线扩散模型的设计进行修改,后者建议如何提高扩散模型的效率或加快采样过程。然而,这些策略是通过修改文献推断出来的,未来的工作可能会包括一些下文未提及的新策略。