

工程蛋白在制药、农业、特种化学品和燃料等行业和应用中发挥着越来越重要的作用。机器学习可以使蛋白质工程在治疗和工业应用方面达到前所未有的控制水平。对数百万个蛋白质序列进行预训练的大型自监督模型最近在生成蛋白质序列嵌入以预测蛋白质特性方面得到了广泛的应用。然而,蛋白质数据集除了包含序列之外,还包含可以提高模型性能的信息。本次演讲将涵盖使用序列和结构数据的预训练模型,它们在预测蛋白质的哪些部分可以被移除而保留功能方面的应用,以及一套新的蛋白质适应度基准来衡量预训练蛋白质模型的进展。

Kevin Yang是剑桥微软研究院的高级研究员,主要研究机器学习和生物学交叉领域的问题。他在加州理工学院与弗朗西斯·阿诺德(Frances Arnold)一起攻读博士学位,研究方向是将机器学习应用于蛋白质工程。在加入MSR之前,他是Generate Biomedicines的机器学习科学家,在那里他使用机器学习优化蛋白质。

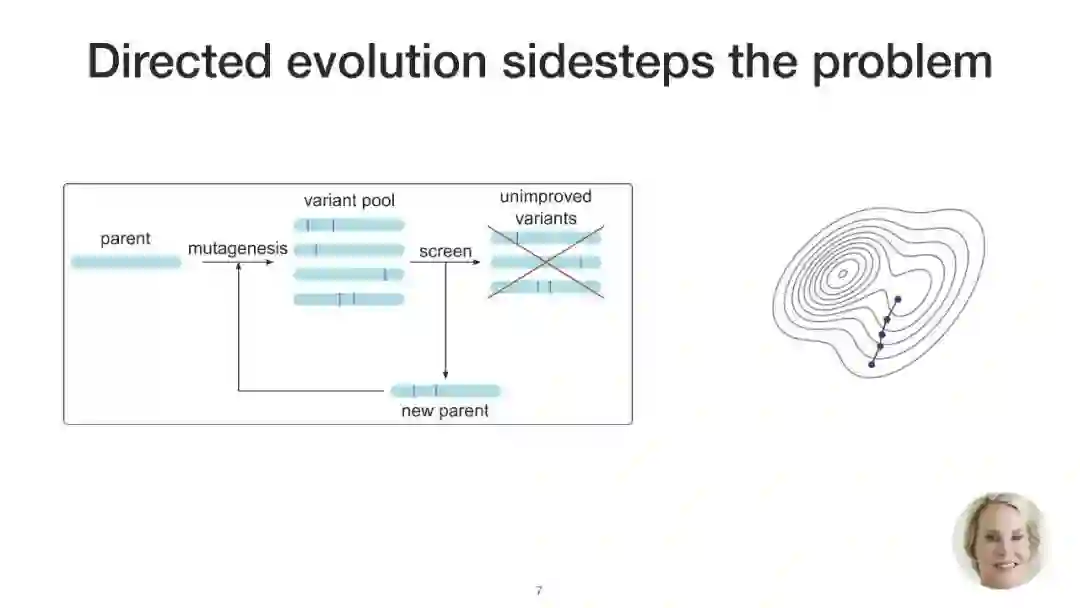
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年11月4日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月4日