随着 BERT、DALL-E、GPT-3 等大规模预训练模型的出现,AI 社区正在经历一场范式转变。从计算机视觉到自然语言处理,从机器人学到推理、搜索,这些大模型已经无处不在,而且还在继续「野蛮生长」。
这种野蛮生长是大模型的有效性带来的必然结果。在 BERT 出现(2018 年)之前,语言模型的自监督学习本质上只是 NLP 的一个子领域,与其他 NLP 子领域并行发展。但在 BERT 横扫 11 项 NLP 任务之后,这种格局被打破了。2019 年之后,使用自监督学习构造语言模型俨然已经成为一种基础操作,因为使用 BERT 已经成为一种惯例。这标志着大模型时代的开始。
这一时代的重要标志是「同质化」。如今,NLP 领域几乎所有的 SOTA 模型都是少数几个基于 Transformer 的大模型进化而来。而且,这种趋势正在向图像、语音、蛋白质序列预测、强化学习等多个领域蔓延。整个 AI 社区似乎出现了一种大一统的趋势。
毋庸置疑,这种同质化是有好处的,大模型的任何一点改进就可以迅速覆盖整个社区。但同时,它也带来了一些隐患,因为大模型的缺陷也会被所有下游模型所继承。
大模型的强大能力来自巨大的参数空间的结合,这也导致它们的可解释性非常差,其能力和缺陷都存在不确定性。在这种情况下,盲目将整个研究范式向大模型转变真的可取吗?
最近,斯坦福大学的 Percy Liang、Rishi Bommasani(Percy Liang 的学生) 、李飞飞等 100 多位研究者联名发布了一篇系统探讨此问题的论文。在论文中,他们给这种大模型取了一个名字——「基础模型(foundation model)」,并系统探讨了基础模型的机遇与风险。「基础」代表至关重要,但并不完备。
论文链接:https://www.zhuanzhi.ai/paper/517a2584ebd7b4fb30e94d5d96a15e5e
论文正文分为四个部分,分别阐述了基础模型的能力、应用、相关技术和社会影响,其具体内容如下:
- 能力:语言、视觉、机器人学、推理、交互、理解等;
- 应用:医疗、法律、教育等;
- 技术:建模、训练、适应、评估、系统、数据、安全与隐私、稳健性、理论、可解释性等;
- 社会影响:不平等、滥用、环境、法规、经济、伦理等。

这篇论文的问世将为负责任地发展、部署基础模型提供一些借鉴。
此外,斯坦福大学的师生、研究人员还成立了一个「基础模型研究中心(CRFM)」,这是斯坦福 HAI 的一个新的跨学科项目。8 月 23 日到 24 日,这两个组织将发起一场关于基础模型的 workshop,讨论基础模型的机遇、挑战、限制和社会影响。
workshop 链接:https://crfm.stanford.edu/workshop.html?sf149081997=1
以下是论文各个章节的介绍。
第二章 基础模型的能力
基础模型拥有的能力有时是在学习过程中出现的,这些能力往往能为下游应用提供动力。关于基础模型能力的推理影响了具有基本能力 AI 系统的创建。该论文的第二章就主要探讨了基础模型的能力及影响,具体包括以下几部分内容:
2.1 语言
该论文首先以自然语言的属性展开,并分析了 NLP 领域基础模型的影响。然后又进一步探讨了语言变体和多语种的问题,最后论文这部分阐述了 NLP 基础模型从人类语言中获得的灵感。
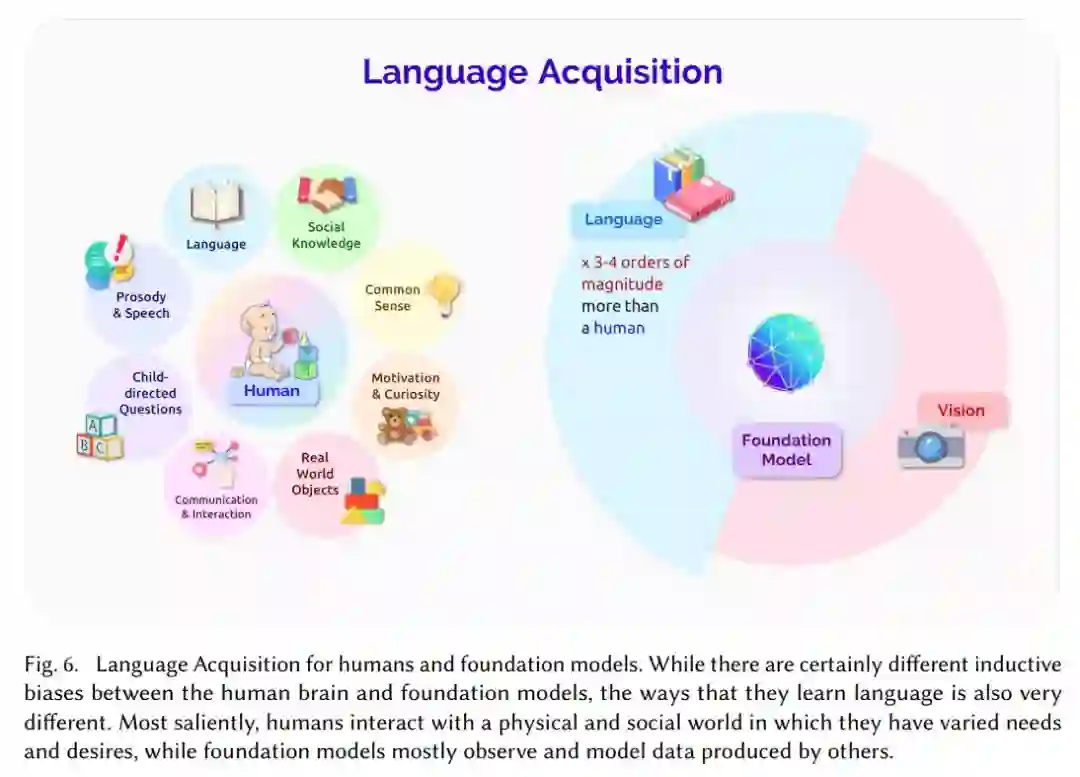
人类和基础模型的语言获取。
2.2 视觉
视觉是生物体理解其生存环境的主要模式之一。视觉能够为智能体带来稳定广泛的密集信号收集能力。论文的 2.2 部分首先概述了计算机视觉领域的关键能力和方法,其中阐明了计算机视觉领域的几大关键任务,包括:
语义理解任务;
含有几何、运动等元素的三维任务;
多模态集成任务,例如视觉问答等。
然后 2.2 部分还探讨了当下计算机视觉领域面临的研究挑战,主要面向几个重点应用领域:
- 面向医疗保健和家庭环境的外围( ambient )智能领域;
- 移动和消费领域;
- 具体化的、可互动的智能体中领域。
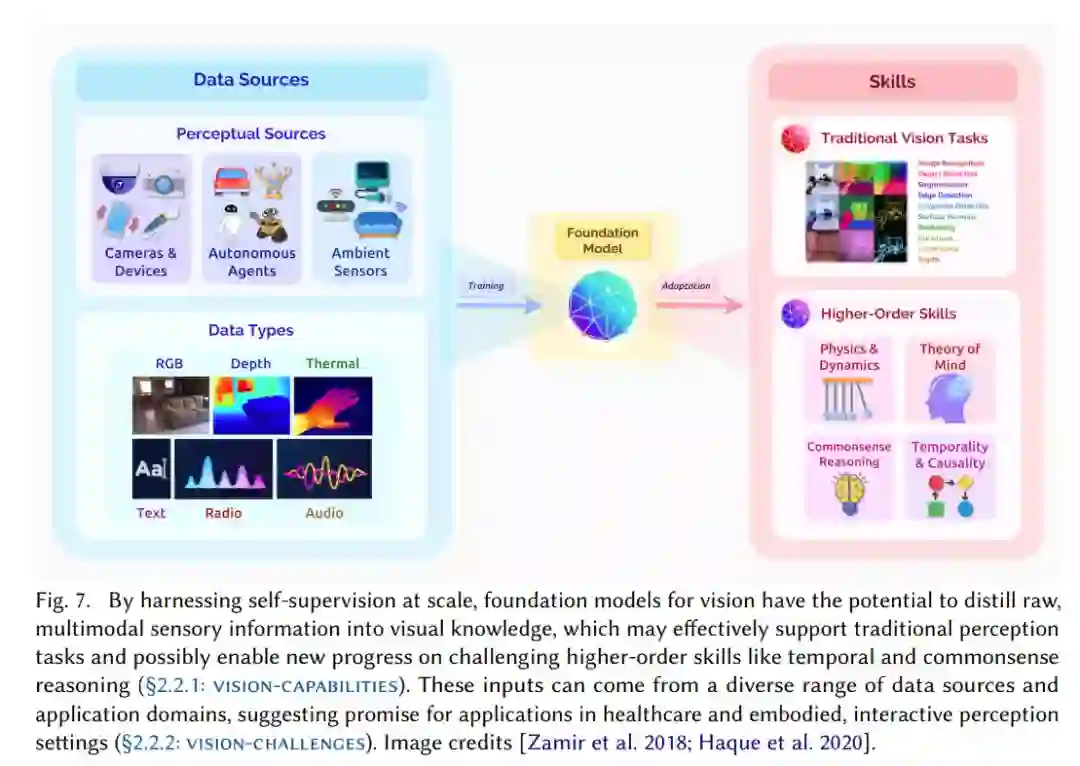
通过大规模利用自监督,视觉基础模型具备一种潜力,即提取原始多模态感知信息并转化为视觉知识,可有效支持传统感知任务,并能够在具有挑战性的高阶技能方面取得新进展。
视觉的基础模型目前处于早期阶段,但已在传统计算机视觉任务取得了一些改进(特别是在泛化方面),并预计近期的进展将延续这一趋势。然而,从长远来看,基础模型在减少对显式注释的依赖方面的潜力可能会带来智能体基本认知能力(例如,常识推理)的进步。同样该论文也探讨了用于下游应用的基础模型的潜在影响,以及推动领域发展必须面临的核心挑战。
2.3 机器人
机器人研究领域的一个长期挑战是让机器人具备处理无数现实难题的能力。该论文的 2.3 部分讨论了基础模型如何助力产生「通用型」机器人,并从机遇和挑战风险多个方面展开。
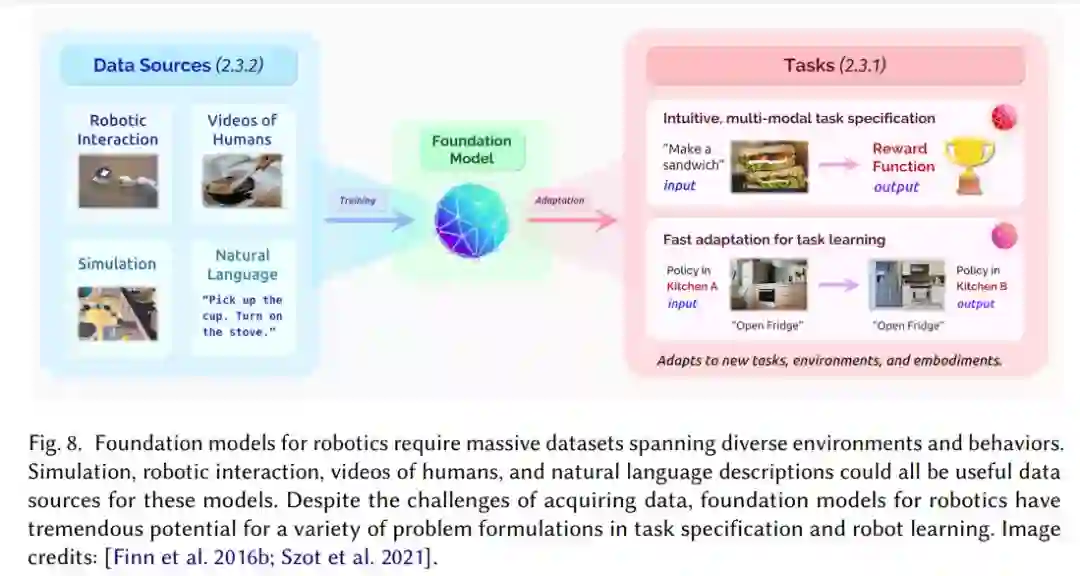
从机遇的角度讲,机器人技术的基础模型应该采用多种形式,因为机器人技术中的问题往往并不符合「一刀切」的模式,不同的问题有不同的输入输出特征。
从挑战与风险上看,一方面,机器人研究必须收集足够大小和多样性的数据集;另一方面,机器人领域需要合理机制来确保能够在现实世界中安全地部署学习行为。
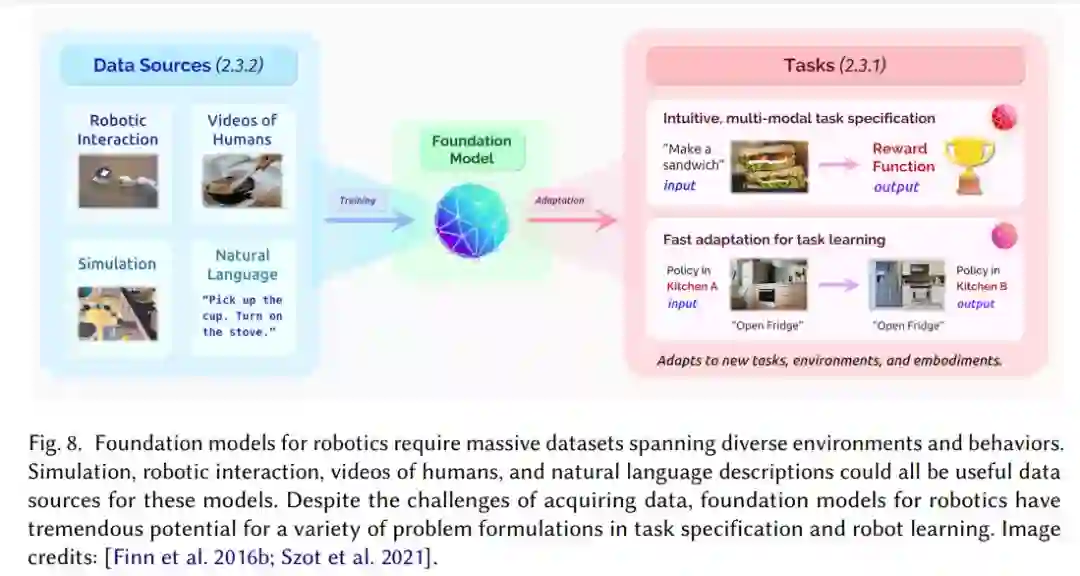
机器人基础模型需要跨多种环境和行为的海量数据集。
2.4 推理和搜索
推理和搜索一直是人工智能领域的中心主题,许多推理问题构成了无限的搜索空间。近来一些应用和研究表明:人们对应用基于学习的方法来解决推理问题的兴趣激增。论文的这部分从当前面临的任务、基础模型扮演的角色、AI 推理领域未来面临的挑战几部分展开。
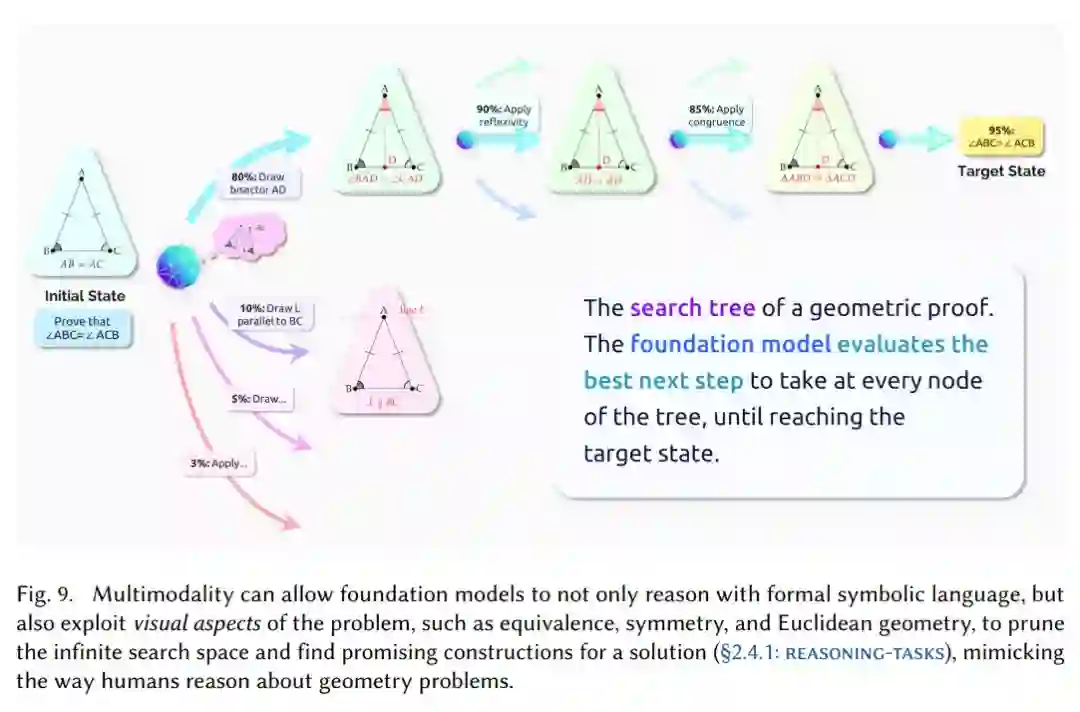
一个几何证明的搜索树例子。
2.5 交互
随着基础模型开发的成熟,模型的容量将不断扩大,它们的多功能性最终可能导致我们与 AI 交互的方式发生根本性变化。论文的这部分从两个重要利益相关者的角度讨论这些变化带来的机会,这两个利益相关者是指
- 将与基础模型交互以设计用户体验的应用程序开发人员;
- 使用由基础模型提供支持的人工智能应用程序或受其影响的终端用户。
2.6 关于理解的原理
基础模型可以了解训练数据的哪些方面?答案对于基础模型的整体能力非常有用,将为智能系统做出重要贡献。该论文主要关注自然语言领域,因为语言的使用是人类智慧的标志,也是人类体验的核心。
第三章 基础模型的应用
基础模型的能力表明了它们具备改变各行各业的潜力,论文的第三章重点从三个学科领域阐述了人工智能的应用,包括医疗保健、法律和教育,这些都是人类社会的基础。这一章节每一部分都探讨了基础模型为该领域带来的挑战和机会。
3.1 医疗保健和生物医学
医疗保健和生物医学是社会中一个巨大的应用领域。
在医疗保健领域,基础模型能够为患者改善医疗服务,提高照顾患者的效率和准确性。同时,基础模型能够减轻医护服务的负担,例如帮助查找相关案例。此外,手术机器人也是未来基础模型的一个研究方向。
在生物医学领域,科研发现需要大量的人力资源、实验时间和财务费用。基础模型可以促进生物医学研究,例如药物的发现和疾病的理解,最终转化为改进的医疗保健解决方案。使用现有数据和公开研究促进和加速生物医学发展是一个紧迫的问题。
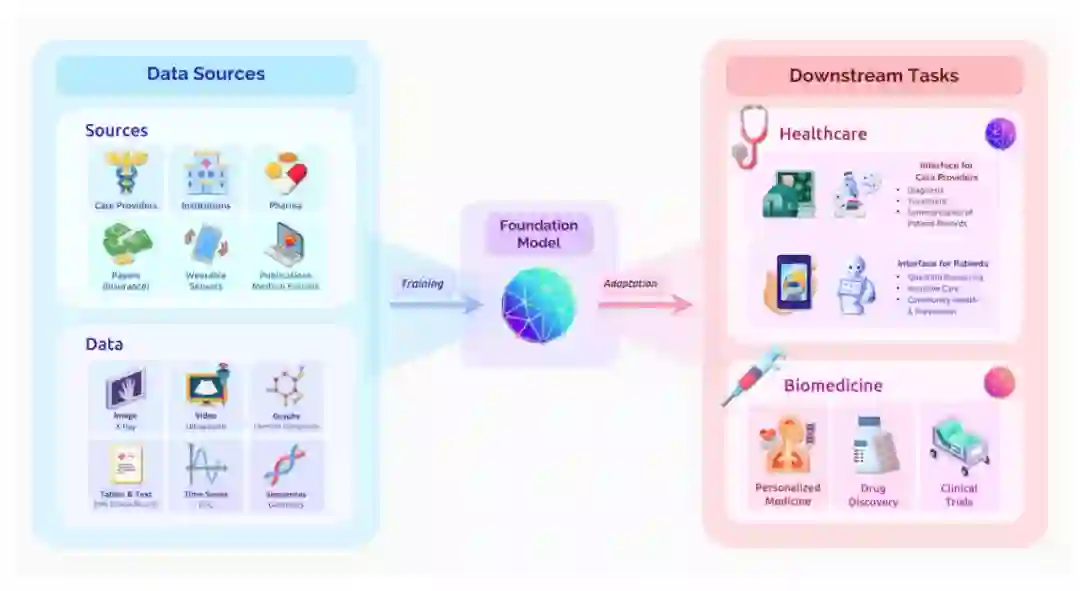
医疗保健和生物医学的基础模型。
此外,未来医疗保健和生物医学领域还面临一些挑战,包括多模态处理、可解释性、法律和道德规范。
3.2 法律
在美国,寻求律师的法律援助可能是非常昂贵的,同时律师也是一个高压职业。
基础模型未来在法律领域的应用可能包括:利用机器学习辅助基于文本的法律任务。值得注意的是,法律的严谨性对 AI 模型提出了必然的高要求,包括数据标注成本非常高,通常只有律师具备创建高质量标签的专业知识,并且各个案件的细微差别也是非常重要,不容忽视的。
3.3 教育
基础模型已经开始用于提升一些教育领域特定任务的性能,论文的 3.3 部分从两个具体任务展开了讨论:(1)理解学生对概念的误解;(2)提高学生对教学指导的理解能力。
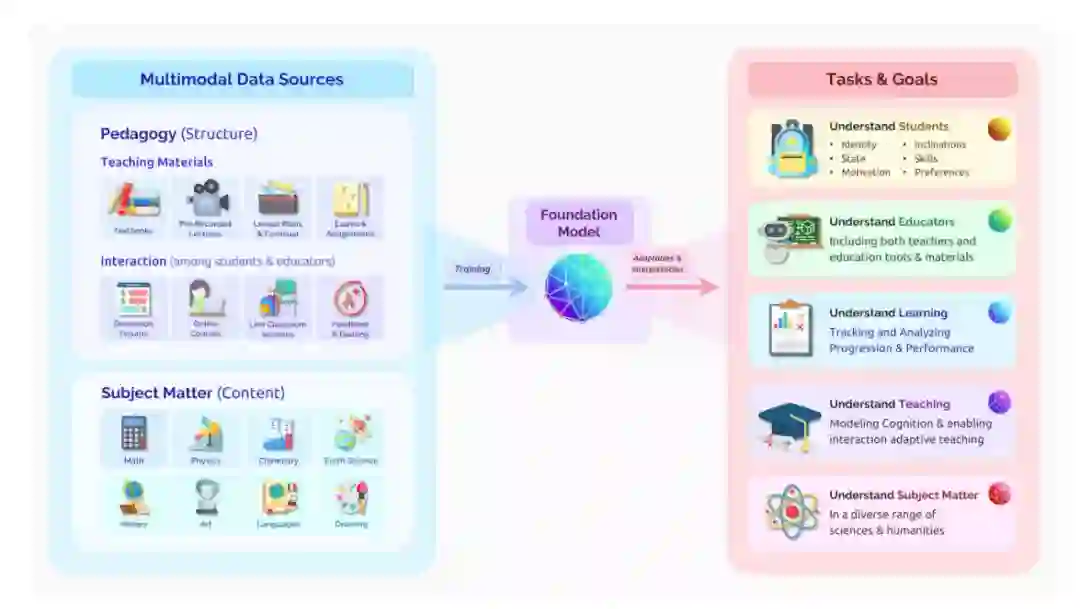
教育领域的基础模型应该在多个数据源上进行训练以学得教育所必需的能力。
了解了各种主题和不同的教学技术的基础模型可以以通用方式应用于一系列任务和目标,例如了解学生、协助教师、生成教育内容等。
此外,该论文对教育研究中基础模型涉及的伦理问题进行了阐述。尽管人工智能助力教育的未来令人兴奋,但在 AI 落地教育领域时必须要考虑隐私与安全、所需教师人数减少的影响、学生使用基础模型工具的效率等重要问题,论文中也针对这几个方面展开了讨论。
第四章 基础模型相关技术
本章主要从技术的角度进行分析。基础模型的技术基础产生了决定其潜力的能力,如第二章介绍的。为了了解在开发中使用的技术,我们需要考虑数据、模型架构、系统、模型训练以及模型的适应性这一系列因素,在研究中需要将模型和理论相结合。为了更好地理解模型,本章还讨论了如何评估和解释模型,以及模型的鲁棒性、安全性和隐私性的重要性,此外,该研究还讨论了 AI 安全领域,以确保这些模型在社会上进行部署时具有可靠性。
建模
本小节研究者讨论和确认了基础模型必不可少的 5 个属性:可跨越的表现力(spanning expressivity)、可扩展性、多模态、内存容量以及可组合性。有了这些属性,就可以有效地提取周围的大量信息,从而成功地解决下游任务。例如表现力可以灵活地捕获和吸收真实世界的信息;可扩展性可以熟练地处理大量的高维数据;多模态可以处理来自不同源和领域的内容;内存容量可以有效地存储和检索已获得的知识;可组合性可以促进对新任务、设置和环境泛化。
基础模型的五个关键属性。
训练
训练目标是描述如何将模型体系架构和大量广泛数据转换为基础模型的数学函数。该研究首先列举了训练方法需要实现的一些目标,可以考虑以下因素:利用广泛的数据、域的完整性、可扩展性和计算效率。此外还描述了当前方法中重要的设计权衡,当前模型所探索的三个重要的设计选择,最后概述了基础模型训练在未来道路上需要前进的目标。
适应性
虽然基础模型提供了一个强大的通用引擎来处理多模态信息,但在某些应用之前,适应性是一个基础模型必要的。本小节描述了适应性的现有方法,以及决定特定适应性程序是否适合特定环境的几个因素。此外,该研究还描述了基础模型适应性的多种示例,最后,该研究提出了一个长远的目标,即未来研究的基础模型适应性。
评估
对于基础模型来说,模型评估是至关重要的。本小节首先介绍了几种评估:内在评估,包括从广泛的外在评估中引入内在评估、对内在性质进行直接评估;外在评估与适应性,包括对特定任务而调整基础模型所花费的资源进行核算。此外本小节还介绍了评估设计等内容。
系统
计算机系统是开发基础模型的最大瓶颈之一,它们通常需要大量计算资源来训练,此外,这些模型可能会随着时间的推移而变得更大,训练难度将会升级。在本节中,研究者讨论了在开发和生产大规模基础模型时,计算机系统面临的挑战。主要从以下几个方面进行介绍:通过协同设计提高性能、自动优化、基础模型的产品化等。
除了上述介绍的内容之外,在第四章中还介绍了:数据方面,讨论了基础模型数据生命周期的管理,并概述了关于数据的四个需求,包括大规模数据管理、支持异构数据源、数据治理和数据质量监控;安全和隐私方面,讨论了单点故障、安全瓶颈等内容。
第五章 基础模型的社会影响
本章主要介绍了基础模型的社会影响,包括模型本身的构建和它们在开发应用程序中的作用,需要研究者仔细检查。具体而言,该研究认为基础模型具有广泛的社会影响,但同时也非常难以理解:基础模型不是直接部署的中间资源,而是作为一个基础,来进一步的进行适应性。因此,用传统方法对技术的社会影响进行推理可能很复杂:对于具有明确目的的系统来说,社会影响相对来说更容易(但仍然很难)理解。本章中,该研究讨论并开始理解基础模型社会影响的复杂性。本章讨论了不公平带来的危害和滥用的危害;基础模型对经济和环境的影响;基础模型在法律和道德方面影响。
不平等与平等:本小节主要描述了内在偏差,即间接但普遍地影响了下游基础模型的属性,此外还包括外部损害,即在特定下游应用环境中产生的损害等内容。
滥用:考虑基础模型的滥用——人们按照预期使用基础模型的情况(例如,生成语言),但是这种功能被有意地利用来对人群或个人造成伤害。本小节概述了基础模型如何使新的滥用形式成为可能,并介绍了支持滥用检测和缓解的新工具。
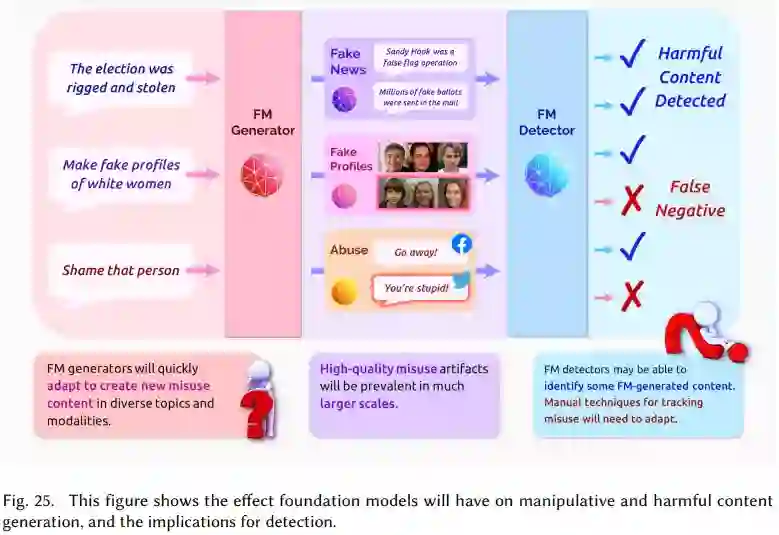
图中显示了基础模型对操控性和有害内容生成的影响,以及对检测的影响。
环境:本小节主要介绍了碳影响应该得到缓解、在使用基础模型之前应该评估成本和收益、应系统地报告基础模型对碳以及能源影响等内容。
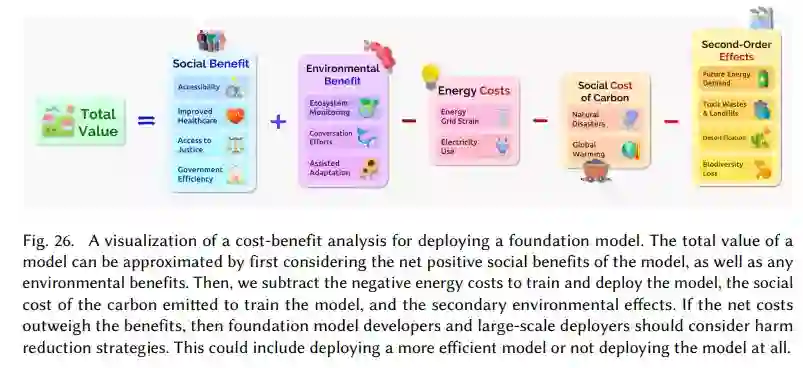
用于部署基础模型的成本效益分析的可视化。
合法性:本小节描述了美国法律如何影响、约束或促进基础模型的创建和使用。我们注意到,围绕算法工具的法律前景仍然具有不确定性。本文强调与(1)模型训练、(2)模型预测的可靠性(3)模型输出保护相关的问题。
此外,本章还介绍了经济,基础模型有潜力通过提高生产力和创新来大幅提高整体生活水平,这些模型可以用来替代人类劳动,增强人类能力,或者帮助研究者发现新的任务和机会。本节最后还介绍了道德规范相关内容。