

本文从概念上和实践上对自然语言处理(NLP)领域的自然语言推理进行了更清晰的认识。从概念上讲,本文为NLP中的自然语言推理提供了一个明确的定义,基于哲学和NLP场景,讨论了哪些类型的任务需要推理,并介绍了推理的分类。**对自然语言推理进行了全面的文献综述,主要涵盖经典逻辑推理、自然语言推理、多跳问答和常识推理。**该文还指出了逆向推理这一多步推理的强大范式,并介绍了可废止推理是自然语言推理研究的一个重要方向。本文专注于单模态非结构化自然语言文本,不包括神经符号技术和数学推理。

1. 引言
近年来,自然语言处理(NLP)取得了重大进展,特别是transformer和预训练语言模型(PLM)的引入。然而,它们执行自然语言推理(NLR)的能力仍然远远不能令人满意。推理是基于现有知识进行推理的过程,是人类智能的一个基本方面,对于决策等复杂任务至关重要。构建具有推理能力的人工智能系统既是研究界的最终目标,也是提升复杂应用性能的必要途径。与使用形式语言进行推理相比,使用自然语言表达进行推理提供了更加自然的人机交互界面,并为研究基于形式化的符号方法所无法实现的诱导、归纳法等可废止推理打开了大门。
诸如BERT[33]和GPT[113]等PLMs自出现以来一直是NLP研究中的重要组成部分。在大规模文本语料库上进行了预训练,PLM能够进行自然语言理解。最近的进展表明,PLMs也有解决推理问题的潜力[24,137,141,154]。具体来说,PLM可以对自然语言语句[24]进行软演绎推理,利用其参数中记忆的隐性知识进行推理[141],并在模型规模足够大时通过思维链提示[76,154],仅使用少量演示或指令就可以逐步执行多步推理。最近,ChatGPT和GPT-4也为社区提供了令人印象深刻的推理能力[4,15]。
**然而,尽管推理最近引起了越来越多的关注[24,26,27,76,106,139,154],但仍然缺乏对推理的明确定义,并且“推理”一词有时会被错误使用,这可能会影响NLP社区对推理的交流和发展。**例如,虽然它属于“常识推理”,但很少有人会认为讲述一个共同的生活经历[9],例如“说出你在酒店房间里可能忘记的东西”是推理。另一个例子是,有时“自然语言推理”被引入为自然语言理解的任务[11],但其他时候的推理为[24]。到目前为止,没有任何一个命名为"推理"的任务被认为是推理(例如常识推理),也没有所有命名为"无推理"的任务被认为是非推理(例如自然语言推理和多跳问答)。这就产生了一个问题:推理实际上是什么?如果它们的名称没有太多指示性,我们如何识别推理任务?尽管许多研究[24,57,163,169]从哲学和逻辑上给出了推理的定义,但该定义并不能很好地捕捉NLP中的推理。例如,虽然推理在哲学上被定义为“使用证据和逻辑得出结论”[57],但它未能明确隐含常识是否可以作为证据以及推理的结论类型,如命名实体消歧。
为了促进自然语言处理中推理的研究,本文试图从概念上和实践上对自然语言处理推理提出一个更清晰的认识。从概念上讲,本文从哲学和NLP场景出发,提出了NLP推理的定义,讨论了哪些类型的任务需要推理,并介绍了推理的分类。在实践中,基于明确的定义,对自然语言处理中的自然语言推理进行了全面的文献综述,主要涵盖经典逻辑推理、自然语言推理、多跳问答和常识推理。**本文回顾各种规模的PLMs论文,我们捕捉到可以应用于不同模型规模的一般方法:端到端推理、正向推理和反向推理。**最后,讨论了推理的局限性和未来的发展方向。除了推理的定义之外,该调查与其他调查有两个重要区别[57,108]3。识别并看待反向推理,这是除正向推理外的另一种强大的多步推理范式。虽然正向推理,如思维链提示,最近在LLM中很流行,但反向推理值得进行更多的探索。由于搜索空间更小[71],向后推理在概念和经验上都比前向推理更有效,因此有可能推广到步骤更长的复杂推理。其次,介绍了可废止推理(即非演绎推理),认为这是最重要的未来方向之一。哲学认为,人类日常生活中的推理大多是非演绎的。然而,这在NLP研究中仍然存在很大的差距,而ChatGPT[4]也更具挑战性。更重要的是,当演绎推理可以用符号推理机(如Prolog编程)精确求解时,可废止推理仍然缺乏有效的解决方案。
本文主要关注单模态非结构化自然语言文本(没有知识三元组、表格和中间形式语言)和自然语言推理(而不是符号推理和数学推理)。本文对利用基于transformer的PLM的相关工作进行了回顾,故意排除了神经符号技术。对收集到的论文进行了整理,对自然语言推理方法进行了分类。总结了近年来该领域的研究进展和趋势。论文分为五个部分(如图1所示)。我们收集了近年来与推理或PLMs相关的200多篇论文。从2019年到2022年,我们在顶级会议上搜索了inference、reasoning、infer、reason、multi-step和multi-hop等关键字,包括ACL、EMNLP、NAACL、ICML、ICLR和NeurIPS。我们还从收集的论文中找到了一些相关的工作。
**总而言之,本综述的主要贡献是: **
(1)首次为NLP中的自然语言推理提供了一个明确的定义,并讨论了一些流行的基准与推理的关系程度。 (2)首次对基于PLM的自然语言推理进行了全面的综述,涵盖了不同的NLR基准,并提供了一个全面的方法分类。我们还介绍了向后推理,它被忽略了,但有潜力。 (3)介绍了可废止推理,比较了演绎推理和可废止推理的差异,讨论了它们对NLP解决方案的影响,并回顾了现有的方法。
2. 什么是自然语言推理
目前,自然语言推理在自然语言处理领域仍缺乏明确的定义,影响了自然语言处理领域的发展和交流。为促进理解、分析和交流,本文旨在对NLP中的自然语言推理的术语和概念提出不同的定义。为了实现这一目标,我们对长期以来研究推理的两个相关领域:哲学和逻辑学进行了研究,并将相关的推理理论转化为自然语言处理。提出了一种NLP中的NLR定义,以满足NLP社区的关注(第2.1节)。然后,提供了NLR的类别,并介绍了它们之间的差异如何影响NLP解决方案(第2.2节)。最后,介绍实现NLR的潜力、挑战和要求(第2.3节)。

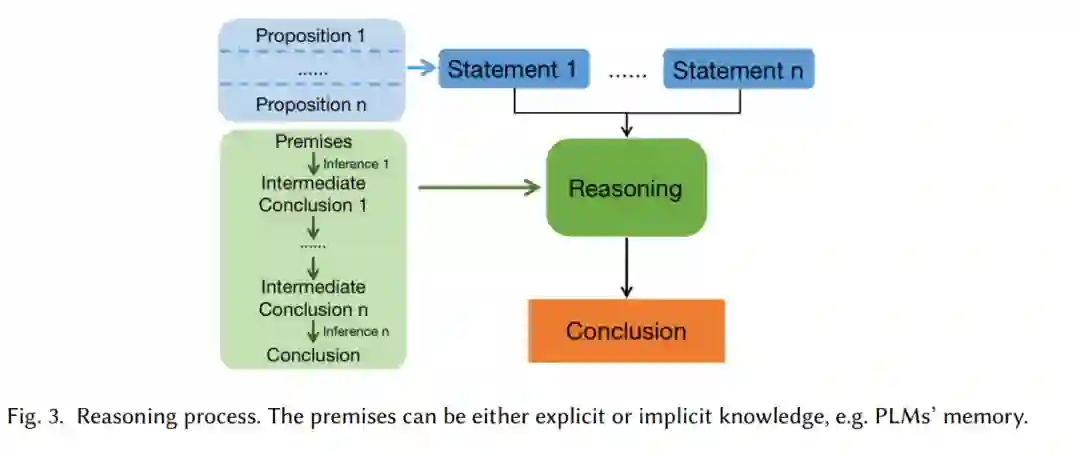
NLP中的推理近年来一直受到关注,而哲学从几千年前就开始研究推理,逻辑被视为正确推理的艺术,它研究推理的概念,使其类别系统化,并发展良好推理的原则,包括形式逻辑和非形式逻辑[8,45,62]。在本节中,我们首先包括来自哲学和逻辑学的推理理论,并将其导出为NLP推理。然后,回顾了自然语言处理中的一些自然语言推理问题;最后,本文提出了一种NLP中推理的定义,该定义结合了哲学和逻辑学中的定义以及NLP社区的关注。自然语言推理是一个整合多种知识(如百科知识和常识知识)以得出关于(现实或假设)世界的一些新结论的过程。知识可以来自显性来源,也可以来自隐性来源。结论是断言或在世界上被假定为真实的事件,或实际行动。
3. 为什么要用PLMs进行自然语言推理
预训练语言模型(PLM)基于transformer架构[149],该架构由许多注意力模块构建,并通过无监督学习技术(如预测掩码标记[33]或生成下一个标记)在大量文本数据上进行预训练[113]。自BERT[33]出现以来,预训练-再微调成为一种常见的范式,它将在预训练阶段学习到的PLMs的通用能力转移到下游任务,并进行进一步的特定任务微调。由于大型语言模型已经被发现是少样本学习[14],上下文学习已经成为一种新的流行范式,它可以在只有少量演示的情况下预测新样本,而无需微调参数。最近,零样本提示范式在LLM中也变得更加流行[76]。
4. 自然语言推理方法
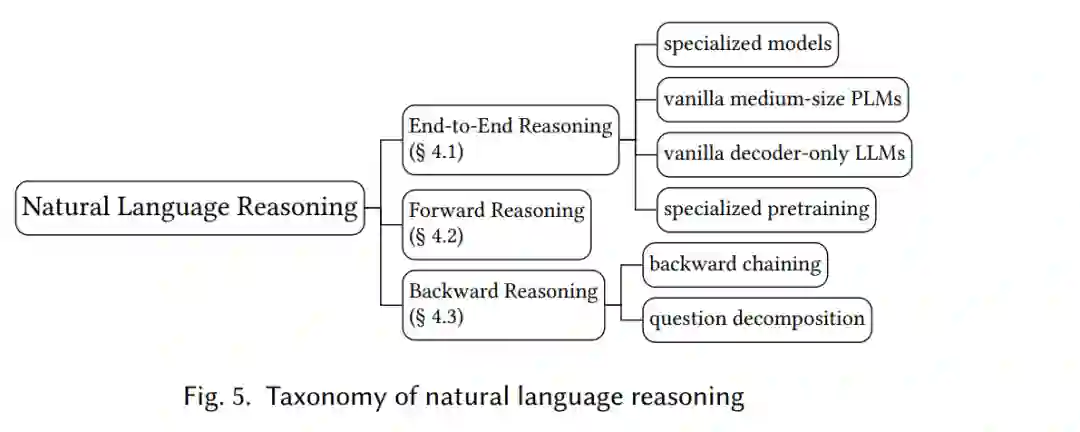
在本节中,我们介绍三种类型的自然语言推理方法:端到端推理(第4.1节),正向推理和反向推理。整个分类法如图5所示。这三类的关键区别在于推理路径。具体来说,“端到端推理”只预测最终答案,没有任何中间文本,而后两种方法可以产生推理路径,包含一个或多个带有中间结论的步骤,展示了将前提与结论联系起来的(可能是多步)推理过程。
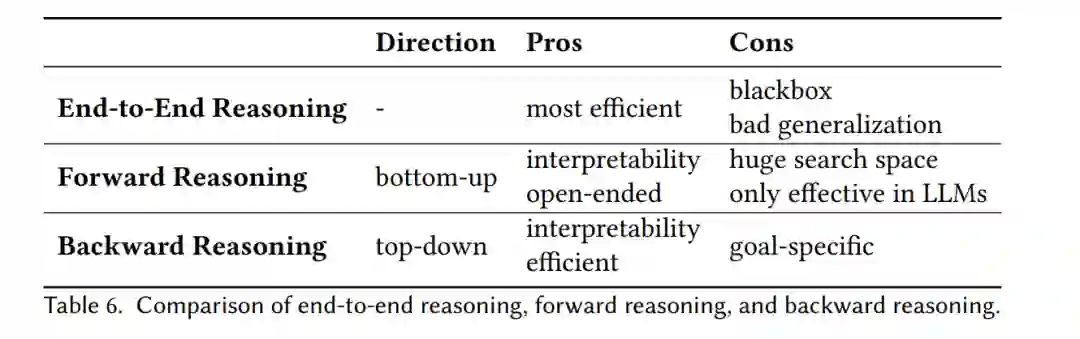
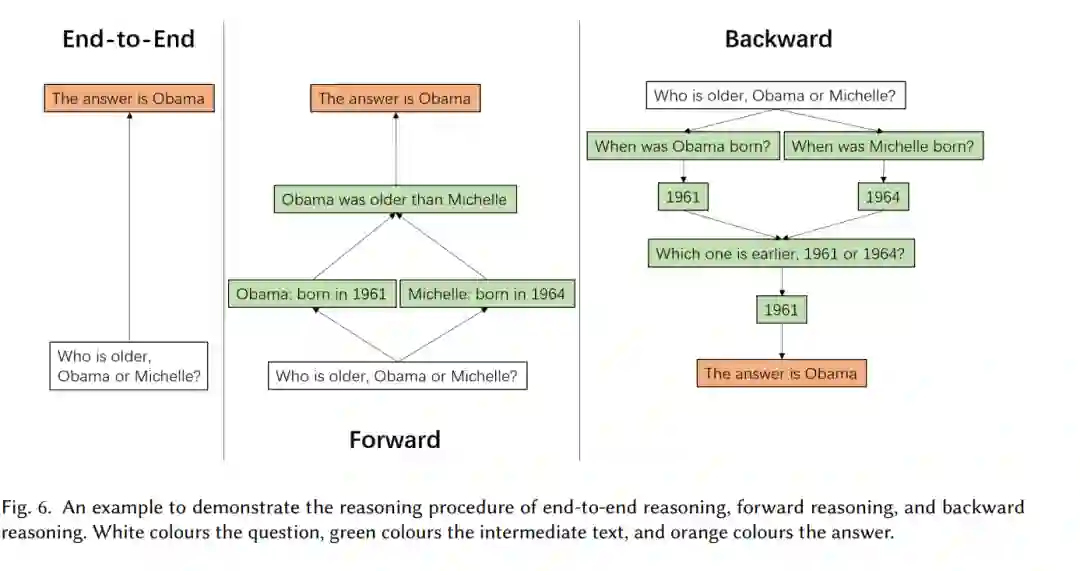
给出每个预测的推理路径可以提高系统的可解释性。特别地,严格的推理路径还可以显式地暴露每个步骤的支持知识。此外,生成推理路径已被证明有利于多步骤推理的最终性能[76,101,106,137,154]。推理有两个方向。推理的两个方向。多步推理可以通过正向[27,126,138,154]或逆向[73,82,96,106,139]进行。正向推理是一个自底向上的过程,它从已有的知识出发,反复推理以获得新的知识,直到问题被解决。反向推理是一种自上而下的过程,它从问题出发,不断地分解为子问题,直到所有子问题都可以被现有的知识所解决。逆向推理针对的是指定的问题,而正向推理可以自由地发现由现有知识所蕴含的新知识,而不需要预先指定问题。因此,在求解特定问题时,前向推理的搜索空间要比后向推理的搜索空间大得多,随着推理的进行面临组合爆炸的问题。定理证明是一个验证问题,其推理路径称为“证明”,正向推理和反向推理通常分别称为“前向链”和“后向链”。我们在表6中比较了这三种方法,并在图6中演示了一个示例。下面的小节将进一步介绍和讨论这种比较。
5. 结论
在本节中,我们提出了一些开放问题,介绍了一些局限性,并提出了一些推理的未来方向。文中还讨论了ChatGPT和GPT4的局限性。 我们对LLMs的推理能力提出了一些开放性问题。在他们的出现推理能力中有许多未解之谜。
为什么CoT提示是有效的?为什么在最终答案带来如此显著的改进之前,只需要产生推理路径,甚至可能是错误的?为什么CoT提示只对LLMs有效?当LLM被提示使用CoT但在中型PLM中失败时,LLM会发生什么? * LLM的推理能力从何而来?为什么LLM可以随着模型大小的增加而出现推理能力?“让我们一步一步思考”的魔力从何而来?他们如何学习这些能力?虽然已经研究了另一种LLM魔法——上下文学习的机制[2,29,159],但推理能力仍然更加神秘。 * 更大的模型推理能力更好吗?如果LLM可以出现可由提示引出的推理能力,那么它们是否可以在模型大小增加时学习到具有竞争力的推理能力?或者,构建更多的数据集和设计推理算法是否仍然有益?


