
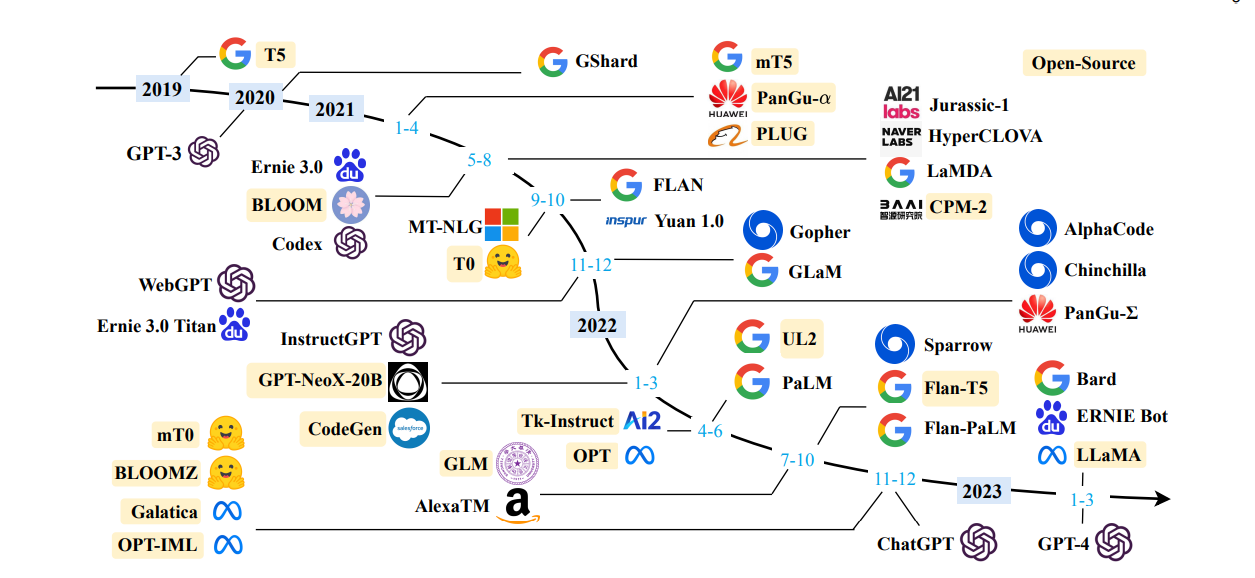
自20世纪50年代图灵测试被提出以来,人类一直在探索机器对语言智能的掌握。语言本质上是一个受语法规则支配的复杂的人类表达系统。这对开发有能力的人工智能(AI)算法来理解和掌握语言提出了重大挑战。作为一种主要的语言建模方法,在过去的二十年中,语言建模在语言理解和生成方面得到了广泛的研究,从统计语言模型发展到神经语言模型。最近,通过在大规模语料库上预训练Transformer模型,人们提出了预训练语言模型(PLM),在解决各种自然语言处理(NLP)任务方面显示出强大的能力。由于研究人员发现模型缩放可以导致性能提高,他们通过将模型大小增加到更大的尺寸来进一步研究缩放效应。有趣的是,当参数规模超过一定水平时,这些放大的语言模型不仅实现了显著的性能提升,而且显示出一些在小规模语言模型(如BERT)中不存在的特殊能力(如上下文学习)。为了区别参数规模的差异,研究界创造了大型语言模型(LLM)这个术语,用于表示规模巨大的PLM(例如,包含数百亿或千亿参数)。近年来,学术界和工业界对LLMs的研究取得了很大进展,其中最显著的进展是基于LLMs开发的ChatGPT(一个功能强大的人工智能聊天机器人)的推出,引起了社会的广泛关注。LLM的技术发展对整个AI社区产生了重要影响,这将彻底改变我们开发和使用AI算法的方式。鉴于这种快速的技术进步,本综述通过介绍背景、关键发现和主流技术,回顾了LLM的最新进展。重点关注LLM的四个主要方面,即预训练、自适应调优、利用率和能力评估。此外,还总结了开发LLM的可用资源,并讨论了剩余问题,以供未来发展方向。本综述提供了关于LLM的文献的最新综述,对于研究人员和工程师来说,这可以是一个有用的资源。
成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
Arxiv
11+阅读 · 2019年11月4日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
Arxiv
11+阅读 · 2019年11月4日