在蓬勃发展的大型语言模型(LLMs)领域,开发一种健全的安全机制,也就是俗称的“保护措施”或“护栏”,已成为确保LLMs在规定范围内伦理使用的当务之急。本文对这一关键机制的当前状态进行了系统的文献综述。文章讨论了其主要挑战,并探讨了如何将其增强为一个全面的机制,以应对各种情境下的伦理问题。首先,本文阐明了主要LLM服务提供商和开源社区所采用的现有保护机制的现状。接着,本文介绍了评估、分析和增强护栏可能需要执行的一些(不)理想属性的技术,例如幻觉、公平性、隐私等。在此基础上,我们回顾了绕过这些控制(即攻击)、防御攻击以及强化护栏的技术。尽管上述技术代表了当前的状态和活跃的研究趋势,我们还讨论了一些不能轻易用这些方法处理的挑战,并提出了我们对如何通过充分考虑多学科方法、神经-符号方法和系统开发生命周期来实现全面护栏的愿景。
近年来,生成式人工智能(GenAI)显著加快了人类迈向智能时代的步伐。像ChatGPT和Sora [1]这样的技术已经成为推动新一代产业转型的关键力量。然而,大型语言模型(LLMs)的快速部署和整合引发了关于其风险的重大关注,包括但不限于伦理使用、数据偏见、隐私和鲁棒性 [2]。在社会背景下,担忧还包括恶意行为者通过传播虚假信息或协助犯罪活动等方式的潜在滥用 [3]。在科学背景下,LLMs可以在专业领域使用,并需要专门考虑科学研究中的伦理问题和风险 [4]。
为了解决这些问题,模型开发者实施了各种安全协议,以将这些模型的行为限制在更安全的功能范围内。LLMs的复杂性,包括复杂的网络和众多参数,以及闭源性质(如ChatGPT),都带来了巨大的挑战。这些复杂性需要不同于前LLM时代的策略,当时主要关注白盒技术,通过各种正则化和架构调整来增强模型训练。因此,除了从人类反馈中进行强化学习(RLHF)和其他训练技能如上下文训练外,社区还倾向于采用黑盒、事后策略,特别是护栏 [5], [6],它们监控和过滤训练后的LLMs的输入和输出。护栏是一种算法,它将一组对象(例如LLMs的输入和输出)作为输入,并确定是否以及如何采取某些强制措施来减少对象中嵌入的风险。如果输入与儿童剥削有关,护栏可能会阻止输入或调整输出以变得无害 [7]。换句话说,护栏用于在查询阶段识别潜在的滥用,并防止模型提供不应给出的答案。
构建护栏的难点往往在于确定其要求。不同国家的AI法规可能不同,在公司背景下,数据隐私可能不如公共领域那么严格。然而,LLMs的护栏可能包括一个或多个类别的要求:幻觉、公平性、隐私、鲁棒性、毒性、合法性、分布外、不确定性等。本文不包括典型的要求,即准确性,因为它们是LLMs的基准,严格来说不是护栏的责任。也就是说,LLMs和护栏之间在责任(尤其是鲁棒性)方面可能没有明确的界限,两者应协作以实现共同的目标。然而,对于具体应用,需要精确定义要求及其相应的度量标准,并需要采用多学科方法。缓解给定的要求(如幻觉、毒性、公平性、偏见等)已经很复杂,如第5节所讨论的那样。当涉及多个要求时,这种复杂性更加严重,特别是当一些要求可能相互冲突时。这样的复杂性需要复杂的解决方案设计方法来管理。在护栏设计方面,虽然可能没有“一统天下”的方法,但一种可行的护栏设计是神经-符号的,学习代理和符号代理在处理LLMs的输入和输出方面协作。多种类型的神经-符号代理 [8]。然而,现有的护栏解决方案,如Llama Guard [9]、Nvidia NeMo [10]和Guardrails AI [11]使用的是最简单、松散耦合的解决方案。鉴于护栏的复杂性,探讨其他更深度耦合的神经-符号解决方案设计将是有趣的。
像安全关键软件一样,需要一个系统化的过程来涵盖开发周期(从规范、设计、实施、集成、验证、确认到生产发布),以谨慎地构建护栏,如ISO-26262和DO-178B/C等工业标准所示。本综述从第2节的一些背景介绍开始。目标是(1)了解现有的护栏框架,这些框架用于控制LLM服务中的模型输出,以及评估、分析和增强护栏以应对特定理想属性的技术(第3节);(2)了解用于克服这些护栏的技术,以及防御攻击和强化护栏的技术(第4节);然后讨论如何实现完整的护栏解决方案,包括为特定应用背景设计护栏的一些系统化设计问题(第5节)。
大型语言模型的背景
大型语言模型(LLMs)主要基于Transformer架构 [12],由多个Transformer块组成的深度神经网络构成。每个块集成了一个自注意力层和一个通过残差连接的前馈层。特定的自注意力机制使模型在分析特定词元时能够专注于邻近词元。最初,Transformer架构是专为机器翻译开发的。新开发的利用Transformer架构的语言模型可以进行微调,从而无需针对特定任务的专用架构 [13]。通常,这些网络包含数千亿(或更多)的参数,并在大规模文本语料库上进行训练。示例包括ChatGPT-3 [14]、ChatGPT-4 [1]、LLaMA [15]和PaLM [16]。
LLMs被用于各种复杂任务,如对话式AI [17]、翻译 [18]和故事生成 [19]。当前的LLMs利用的架构和训练目标类似于较小语言模型,如Transformer架构和以语言建模为中心的任务。然而,LLMs在模型尺寸、数据量、应用范围的广度和计算成本等方面显著扩大。构建离线模型包括三个主要阶段 [2]:预训练、适应性调优和使用改进。通常,预训练阶段类似于传统的机器学习训练,包括数据收集、选择架构和进行训练。适应性调优包括指令调优 [20]和对齐调优 [21],以从任务特定指令中学习并遵循人类价值观。最后,使用改进可以增强用户交互,包括上下文学习 [14]和思维链学习 [22]。
在训练完LLM后,其性能是否符合预期非常重要。此评估通常包括三个维度:评估基本性能,进行安全分析以了解实际应用中的潜在后果,以及利用公开可用的基准数据集。主要的性能评审集中在语言生成和复杂推理等基本能力上。安全分析深入研究LLM与人类价值观的对齐、与外部环境的交互以及整合到更广泛应用中的情况,如搜索引擎。此外,基准数据集和可访问工具支持这一综合评估。评估结果决定了LLM是否符合预定标准并准备部署。如果不符合,则回到早期训练阶段之一,以解决发现的问题。在部署阶段,LLM可以在网页平台上用于直接用户交互,如ChatGPT,或整合到搜索引擎中,如新Bing。无论应用如何,标准做法是在LLM和用户之间的交互中实施护栏,以确保遵守AI法规。
**护栏的设计与实施技术 **
本节介绍了由LLM服务提供商或开源社区提出的几种现有护栏技术。然后,我们回顾了根据期望的理想属性评估、分析和增强LLMs的方法。
护栏框架和支持软件包
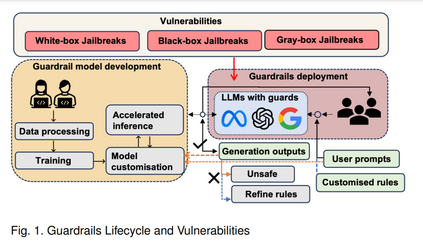
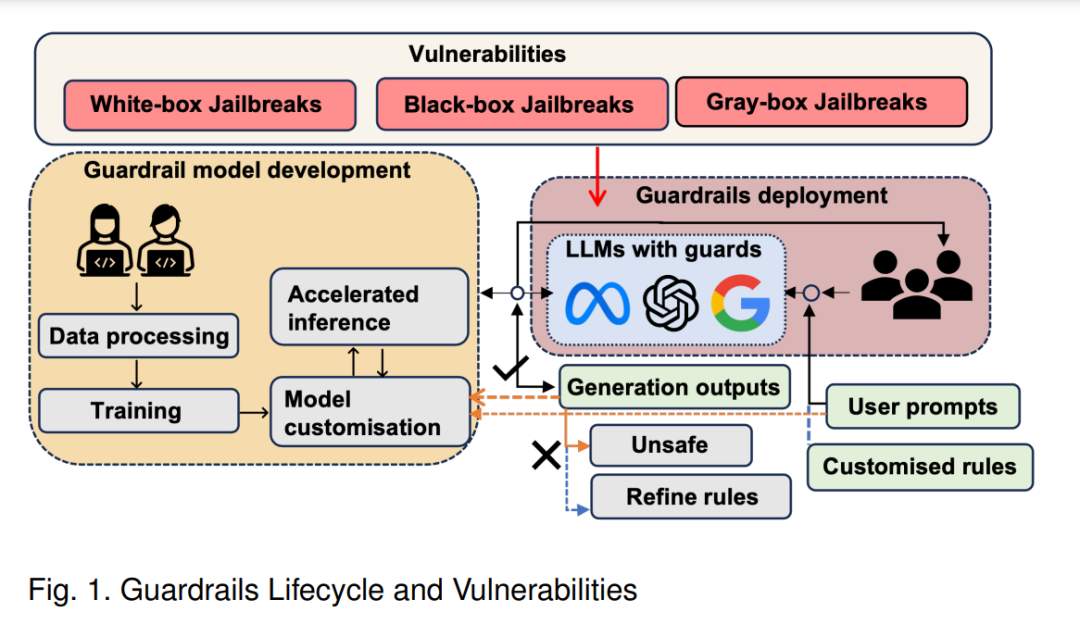
LLM护栏构成了一套旨在监督和规范用户与LLM应用交互的安全措施。这些措施是可编程的、基于规则的系统,位于用户和基础模型之间。其主要功能是确保LLM模型遵守组织的既定原则,并在规定的伦理和操作框架内运行。护栏在用户与已部署的LLMs交互阶段应用,这是LLM生命周期的最后一步。图1展示了通用护栏机制的生命周期和潜在漏洞。开发者通过数据处理、护栏模型训练和模型定制或微调(例如,Llama Guard和NeMo Guardrails)完成护栏的开发,如图1黄色区域所示。这些护栏随后部署在LLMs中,以促进与用户的交互。通常,用户预定义需要保护的内容,也称为自定义规则。随后,用户通过提示与LLMs进行交互并等待生成的响应。护栏根据预定义规则评估输出以确定其合规性。如果内容被认为不安全,护栏可能会直接阻止或向用户发出预设警告。相反,如果输出符合标准,则直接显示给用户,如图1橙色区域所示。值得注意的是,一些现有攻击方法允许不安全内容绕过护栏保护,如图1红框所示;有关这些攻击方法的详细讨论,请参阅第4节。
栏中(不)理想属性的技术
在本节中,我们讨论几种不同的属性,详细说明它们的标准定义以及如何使用护栏来保护这些属性。需要注意的是,属性的数量过于庞大,无法全面覆盖,因此我们重点关注幻觉、公平性、隐私、鲁棒性、毒性、合法性、分布外和不确定性。
克服与增强护栏
如第3节所述,实施先进的保护技术在增强LLMs的安全性和可靠性方面发挥了重要作用。然而,[125]指出,使用护栏并不能增强LLMs抵御攻击的鲁棒性。他们研究了诸如ModerationEndpoint、OpenChatKitModeration Model和Nemo等外部护栏,发现它们仅在一定程度上减少了越狱攻击的平均成功率。越狱攻击(“jailbreaks”)旨在通过操纵模型的响应来利用语言模型的固有偏见或漏洞。这些成功的攻击允许用户绕过模型的保护机制、限制和对齐,可能导致生成非常规或有害内容,或者任何由对手控制的内容。通过绕过这些约束,越狱攻击使模型能够产生超出其安全训练和对齐边界的输出。 因此,本节我们探讨了当前用于绕过LLMs护栏的方法。在表2中,我们比较了不同的越狱攻击: 1. 攻击者访问类型: 白盒、黑盒和灰盒。在白盒场景中,攻击者可以完全查看模型的参数。黑盒情况限制了攻击者观察模型的输出。在灰盒背景下,攻击者通常对部分训练数据有部分访问权限。 1. 提示级别的操控: 用户提示或系统提示。用户提示是由用户指定的输入提示,允许个性化或针对性的输入。系统提示则是由模型自动生成的,可能包括攻击者巧妙设计以欺骗或操纵系统响应的输出。 1. 核心技术: 用于攻击LLM的主要技术。 1. 隐蔽性: 高隐蔽性意味着攻击难以被人类察觉,应该是一些逻辑、语义和有意义的对话,而不是一些无意义的内容。 1. GPT-4 评估: 由于许多越狱攻击并未直接针对带有护栏的LLMs,而GPT-4有其默认护栏,因此对GPT-4的评估可以看作是比较的替代指标。 1. 目标操纵的生成响应属性: 毒性、隐私、公平性和幻觉。