随着大型语言模型(LLMs)的最新进展,结合LLMs与多模态学习的兴趣日益增长。先前关于多模态大型语言模型(MLLMs)的综述主要集中在理解方面。本综述详细阐述了不同领域的多模态生成,包括图像、视频、3D和音频,并重点介绍了这些领域的里程碑式的显著进展。具体来说,我们详尽调查了这些方法背后的关键技术组件和研究中使用的多模态数据集。此外,我们深入探讨了可以利用现有生成模型进行人机交互的工具增强型多模态代理。最后,我们还全面讨论了人工智能安全的进展,并研究了新兴应用及未来前景。我们的工作提供了对多模态生成的系统且深入的概述,预计将推动生成内容人工智能(AIGC)和世界模型的发展。所有相关论文的精选列表可以在https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation找到。
人与物理世界的互动涉及来自多种模态的信息,例如语言、视觉和音频。因此,实现一个世界模拟器也需要模型能够以灵活的方式感知和响应多模态信息。最近,OpenAI提出了一个基础视频生成模型Sora [1],能够生成高度逼真的视频作为世界模拟器。它在模拟或生成真实世界视频方面取得了很大进展,但无法生成其他模态,如文本、3D和音频。此外,它缺乏感知其他模态(如图像、视频、3D和音频)的能力,使其成为一个无法全面理解的世界模拟器。
在过去的几年中,研究人员专注于单一模态的生成并取得了很大的进展:在文本生成方面,我们见证了从BERT [2]、GPT1 [3]、GPT2 [4]、GPT3 [5]、GPT4 [6]到ChatGPT [7]、LLaMA [8]、[9]的定性飞跃,模型参数和训练样本数量迅速增长,导致模态能力和产品部署的不断提升。在视觉生成领域,随着扩散模型和大规模图文数据集的快速进步,图像生成取得了显著成就,能够根据各种用户提供的提示文本合成高质量的图像 [10]–[13]。随后,通过视频扩散模型和大规模视频语言数据集,视频生成领域也取得了重要进展,出现了许多开创性的工作,如 [14]–[22] 和Sora [1]。在3D生成方面,随着CLIP [23]模型的出现,一些方法 [24]–[26] 尝试将文本信息带入3D表示的渲染图像(即点云、网格、NeRF [27]和高斯投影 [28]),这些方法在文本到3D生成方面取得了显著进展。此外,将Stable Diffusion (SD) [10]与文本到图像渲染相结合,推动了一系列文本到3D生成的工作 [29]–[43]。强大的文本到图像模型帮助3D生成实现了更高的性能和更好的结果。在音频生成领域,一系列代表性工作涉及不同的音频域,如 [44]–[46] 的文本到音频、 [47]–[49] 的文本到音乐和 [50]–[55] 的文本到语音,它们在生成高质量的自然声音、音乐和人类级语音方面取得了显著的性能。
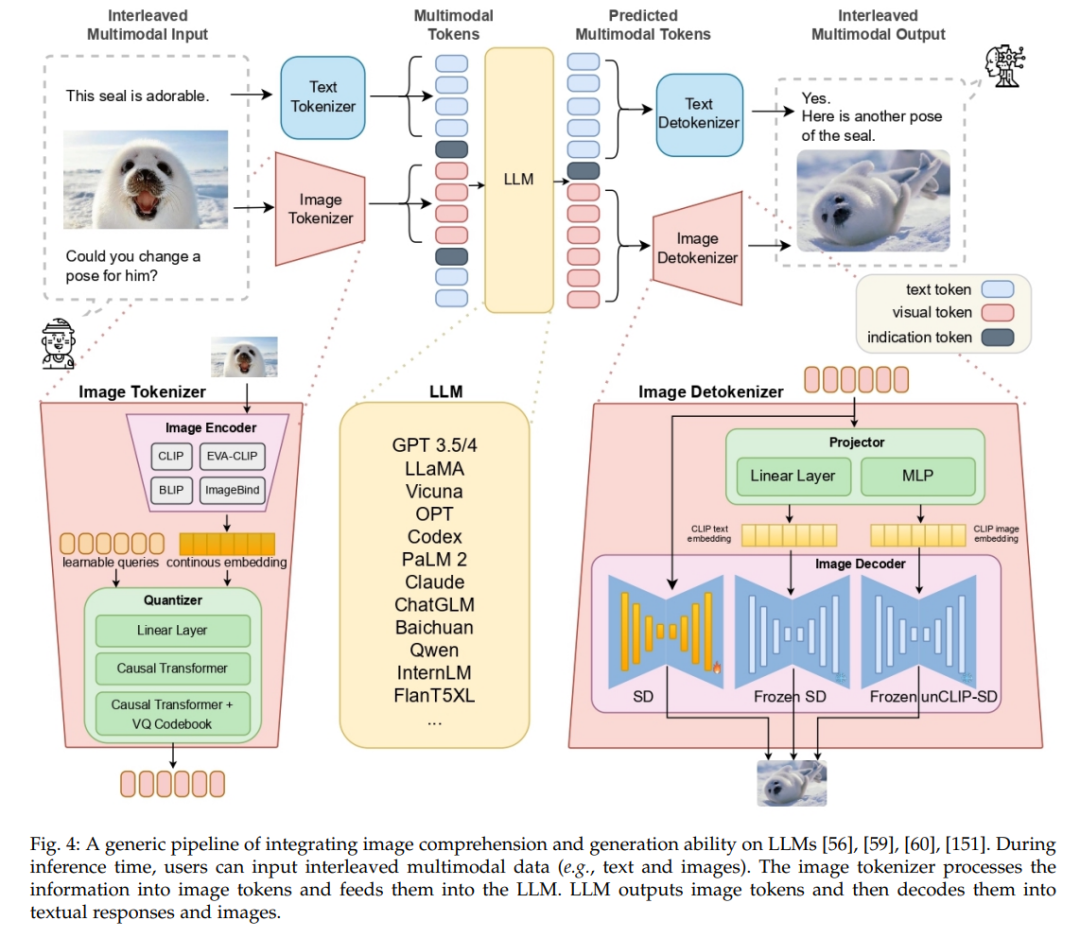
随着大型语言模型(LLMs)的显著进步,其他非文本模态开始利用LLMs的力量来增强其生成流程,或将文本生成与非文本生成集成到一个统一系统中,旨在实现更高级的功能和改进的生成性能。在图像生成方面,有两类方法与语言模型实现了显著的整合。第一类方法涉及将视觉信息编码为离散的令牌ID,试图统一视觉理解与生成 [56]–[61]。具体来说,视觉信息被编码为令牌表示,LLMs直接理解并生成视觉令牌,从而实现视觉理解与生成的同步。第二类方法专注于利用LLMs提升现有预训练文本到图像(T2I)模型的生成质量:一类工作涉及利用LLMs作为布局规划器,结合对象的空间位置、数量和对象大小的知识,生成所需的边界框 [62]–[66]。在获得边界框后,可以通过一个基于文本到图像(T2I)模型生成图像 [67]。另一种方法是利用LLMs扩展用户输入的提示 [68]:通过提供高度详细和全面的用户提示,LLMs通过丰富提示信息生成高质量的图像。在LLMs的帮助下,视觉生成实现了更高的生成质量、改进的提示跟随能力、对话功能和用户友好界面。在视频生成方面,LLMs作为统一的多模态联合生成的通用骨干 [69]、[70],用于视频布局规划 [63]、[71]–[74] 和动态指导的时间提示生成 [75]–[79]。在3D生成和编辑方面,LLMs作为用户与3D资产之间的桥梁,提高了交互效率 [80]、[81] 并帮助用户理解 [82]、[83] 3D资产。在音频生成和编辑方面,语言模型主要作为多模态音频的协调骨干 [84]–[96],用于特定任务的条件器 [97]–[99],用于音频理解的标签器 [100]–[102],以及用于交互生成/编辑的代理 [103]–[108],并作为新方法的灵感来源 [47]、[48]、[53]、[109]–[111]。LLMs在音频领域的日益广泛使用不仅改变了我们与声音和音乐互动的方式,还扩展了AGI与音频技术交叉点的边界。此外,多模态代理将多种模态整合到一个系统中,开发出一个能够理解和生成非文本模态的通用系统。因此,LLMs在生成各种模式的内容中扮演着越来越不可或缺的角色。
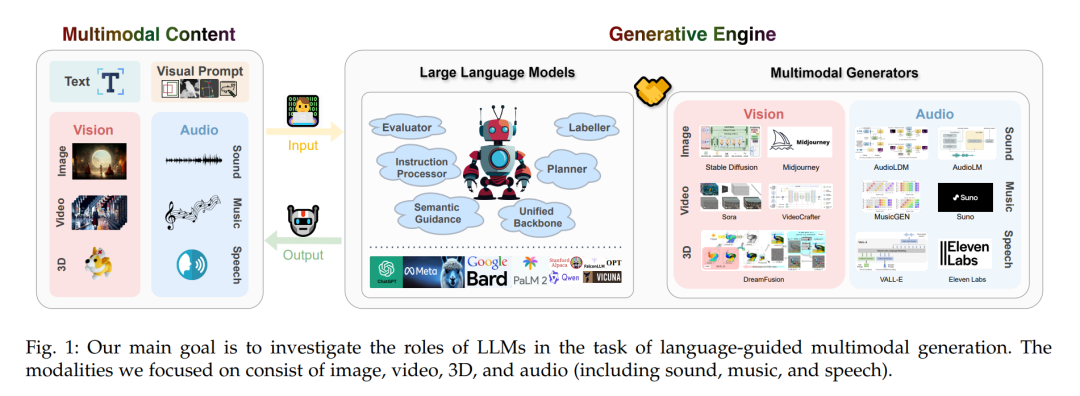
为了赋能世界模拟器并推动多模态生成的发展,在这项工作中,我们对涉及LLMs在多模态生成中的工作及其在这一过程中的角色进行了全面回顾。如图1所示,我们将LLMs的角色总结为几个关键方面,如评估者、标注者、指令处理器、规划者、语义指导的提供者或骨干架构。此外,我们在第9节讨论了AIGC时代的重要安全问题,在第10节和第11节探讨了新兴应用和未来前景。
我们总结了我们的贡献如下:
- 我们首次系统性地回顾了LLMs在多模态生成中的应用,包括图像、视频、3D和音频。
- 我们通过比较分析前LLM时代和后LLM时代的生成技术演变,提供了对这些方法进展和改进的清晰视角。
- 我们从技术角度总结了LLMs在各模态生成过程中的各种角色。
- 我们讨论了重要的AI安全问题,研究了新兴应用,并探索了未来方向,以促进多模态生成和世界模型的发展。 内容概述
我们首先在第2节回顾了关于特定模态生成和LLMs的相关综述。接着在第3节简要回顾了代表性生成模型、多模态编码器、Transformer和LLMs的基本技术。然后,我们在第4节、第5节、第6节、第7节和第8节分别回顾了基于LLMs的不同视觉模态的视觉生成,包括图像、视频、3D、音频和多模态代理。最后,我们在第9节讨论了生成式AI的安全性,并在第11节探讨了基于LLMs的多模态生成领域的几个潜在未来方向。
范围
本综述探讨了多种模态的生成,包括图像、视频、3D模型和音频。我们的多模态生成综述涵盖了不同模态的单独生成以及多模态的联合生成。我们不会深入探讨纯文本生成,因为已有许多综述专门关注该领域的进展 [112]–[114]。我们的主要关注点是近年来大型语言模型的出现如何帮助生成其他视觉和音频模态,特别是在开放域生成方面。这将有助于我们设计更好的多模态统一生成模型。具体来说,我们关注以下任务:
- 图像生成与编辑:图像生成旨在根据用户提供的文本描述创建各种开放域图像内容,包括图片、照片或风格化绘画。图像编辑旨在根据用户指示修改输入的图像内容。
- 视频生成与编辑:模型根据自由形式的文本描述生成或修改任意和各种动态视觉内容。
- 3D生成与编辑:生成和编辑3D对象、场景或头像的任务,基于用户提供的文本描述。
- 音频生成与编辑:使用文本描述生成音频,包括一般声音、音乐和语音。音频编辑任务如添加、删除或修复涉及使用文本描述修改现有音频。
- 多模态生成代理:使LLMs能够通过利用各种专门的多模态工具处理不同模态的数据。
- 生成式AI安全:关注减少有害和偏见内容,保护版权,并解决多模态生成模型创建虚假内容的问题