多语言大型语言模型利用强大的大型语言模型处理和响应多种语言的查询,这在多语言自然语言处理任务中取得了显著的成功。尽管取得了这些突破,但在这一领域仍缺乏一个全面的综述来总结现有方法和最近的发展。为此,在本文中,我们提出了一个彻底的审查,并提供了一个统一的视角来总结多语言大型语言模型(MLLMs)文献中的最新进展和新兴趋势。本文的贡献可以总结如下:(1)第一份综述:据我们所知,我们采取了第一步,在多语言对齐的基础上对MLLMs研究领域进行了彻底的审查;(2)新分类法:我们提出了一个新的统一视角来总结MLLMs的当前进展;(3)新前沿:我们突出了几个新兴的前沿并讨论了相应的挑战;(4)丰富资源:我们收集了大量的开源资源,包括相关论文、数据语料库和排行榜。我们希望我们的工作能为社区提供快速访问并推动MLLMs的突破性研究。
近年来,大型语言模型(LLMs)在各种自然语言处理任务上取得了优异的表现(Brown et al., 2020; Touvron et al., 2023a; Bang et al., 2023; Zhao et al., 2023b; Pan et al., 2023; Nguyen et al., 2023a; Trivedi et al., 2023),并展示出了令人惊讶的突发能力,包括上下文学习(Min et al., 2022; Dong et al., 2022)、思维链推理(Wei et al., 2022; Huang et al., 2023a; Qin et al., 2023a)以及规划(Driess et al., 2023; Hu et al., 2023b)。然而,大多数LLMs主要关注英语任务(Held et al., 2023; Zhang et al., 2023i),使其在多语言环境,尤其是低资源环境下表现不足。
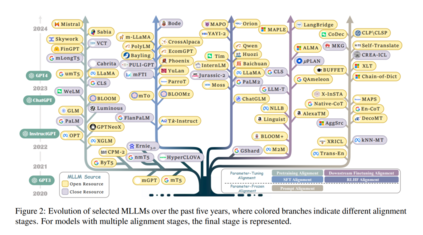
实际上,全球有超过7000种语言。随着全球化的加速,大型语言模型的成功应考虑服务于不同国家和语言。为此,多语言大型语言模型(MLLMs)具有全面处理多种语言的优势,越来越受到关注。具体来说,现有的MLLMs可以根据不同阶段大致分为两组。第一系列工作(Xue et al., 2020; Workshop et al., 2022; Zhang et al., 2023g; Muennighoff et al., 2022)利用多语言数据调整参数以提升整体多语言性能。第二系列工作(Shi et al., 2022a; Qin et al., 2023b; Huang et al., 2023a)还采用先进的提示策略,在参数冻结推理阶段挖掘MLLMs的更深层次多语言潜力。
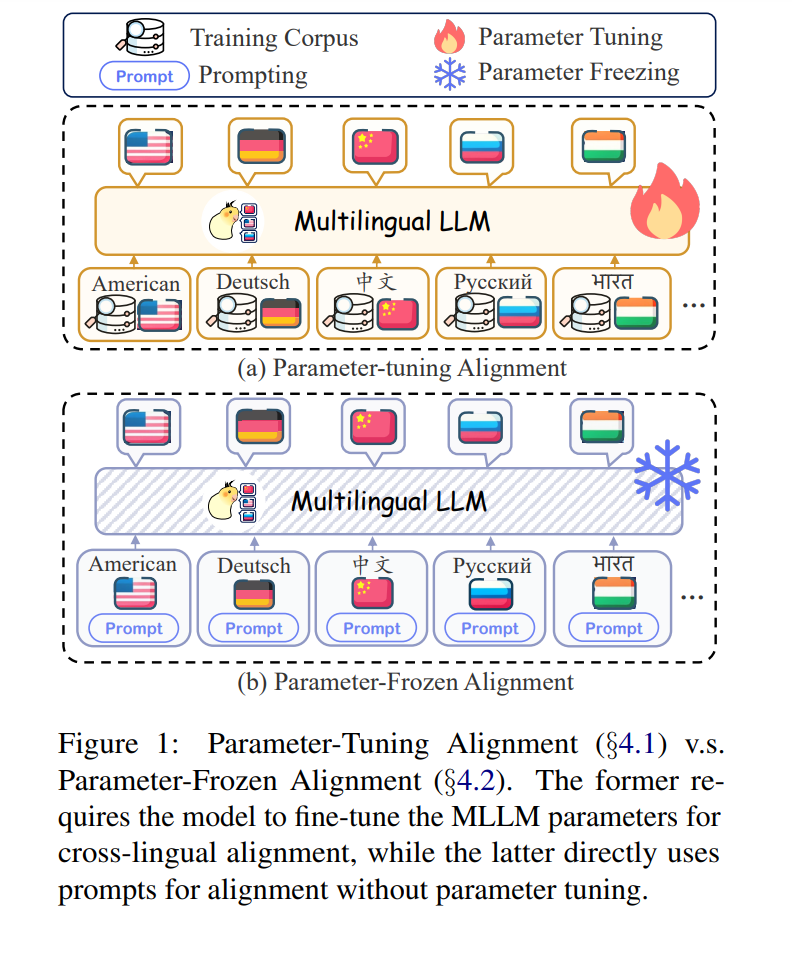
尽管在MLLMs上取得了显著成功,但仍缺乏对最近努力的全面回顾和分析,这阻碍了MLLMs的发展。为了弥补这一差距,我们首次尝试对MLLMs进行全面而详尽的分析。具体来说,我们首先介绍广泛使用的数据资源(§3)。此外,由于跨语言对齐的关键挑战,我们根据对齐策略引入了新的分类法(§4),旨在提供文献中的统一视角,包括参数调整对齐和参数冻结对齐(如图1所示)。具体来说,参数调整对齐需要在预训练、监督微调、人类反馈学习和下游微调过程中调整模型参数以增强英语和目标语言之间的对齐。参数冻结对齐指的是通过跨语言提示实现的对齐,无需调整参数。最后,我们指出了一些潜在的前沿领域以及MLLMs面临的相应挑战,希望激发后续研究(§5)。
本工作的贡献可以总结如下:(1)首次综述:据我们所知,我们是第一个根据多语言对齐在MLLMs文献中提出全面综述的;(2)新分类法:我们引入了将MLLMs分类为参数冻结和参数调整两种对齐类型的新分类法,为理解MLLMs文献提供了统一视角;(3)新前沿:我们讨论了一些新兴的前沿,并突出了它们的挑战和机遇,希望为未来研究的发展铺路;(4)详尽资源:我们首次尝试组织MLLMs资源,包括开源软件、多样的语料库和相关出版物的精选列表,可在https://multilingual-llm.net访问。 我们希望这项工作能成为研究者的宝贵资源,并激发未来研究的更多突破。
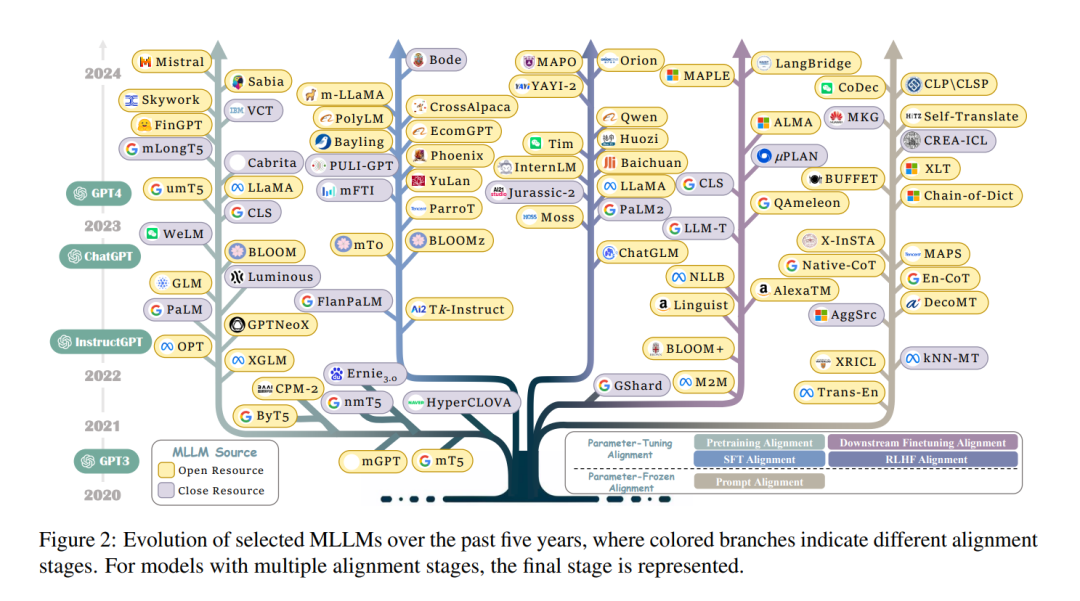
如图4所示,我们引入了一种新的分类法,包括参数调整对齐(§4.1)和参数冻结对齐(§4.2),旨在为研究人员提供一个统一的视角,以理解MLLMs文献。具体来说,参数调整对齐(PTA)包括一系列逐步进阶的训练和对齐策略,包括预训练对齐、监督微调(SFT)对齐、人类反馈学习(RLHF)对齐,以及最终的下游微调对齐。这些阶段的共同目标是系统地优化模型参数,以对齐多语言性能。相反,参数冻结对齐(PFA)侧重于基于PTA的四种提示策略:直接提示、代码切换提示、翻译对齐提示和检索增强对齐。这种方法保持原始模型参数,以实现预期结果。