大型语言模型(LLMs)由于在各种任务中的卓越表现而受到广泛关注。然而,LLM推理的大量计算和内存需求给资源受限的部署场景带来了挑战。该领域的努力已经朝着开发旨在提高LLM推理效率的技术方向发展。本文提供了对现有文献关于高效LLM推理的全面综述。我们首先分析了LLM推理效率低下的主要原因,即模型规模大、注意力操作的二次复杂度和自回归解码方法。接着,我们介绍了一个全面的分类法,将当前文献按数据级、模型级和系统级优化进行组织。此外,本文还包括了在关键子领域内代表性方法的比较实验,以提供定量洞见。最后,我们提供了一些知识总结并讨论未来的研究方向。
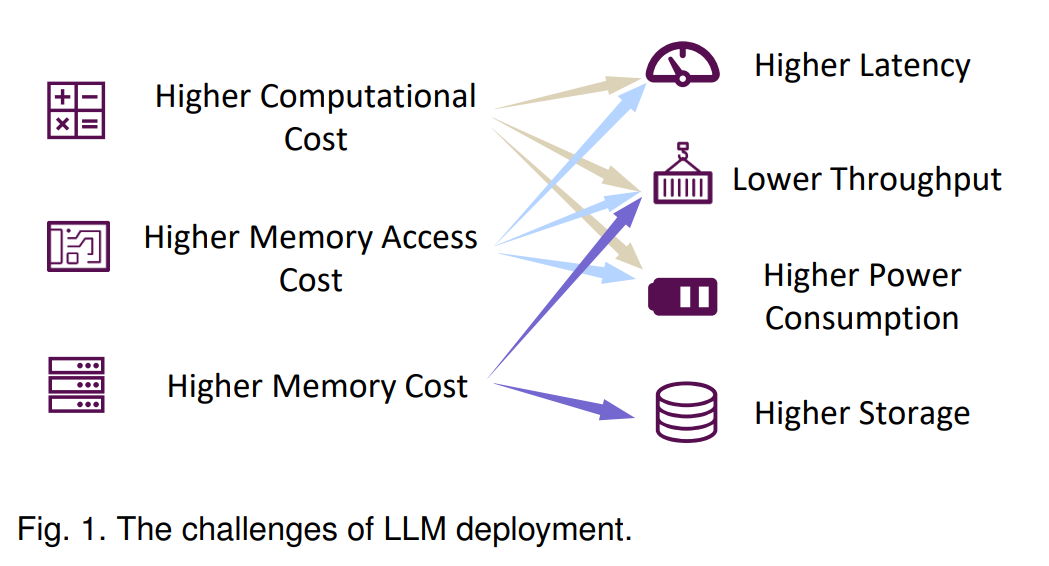
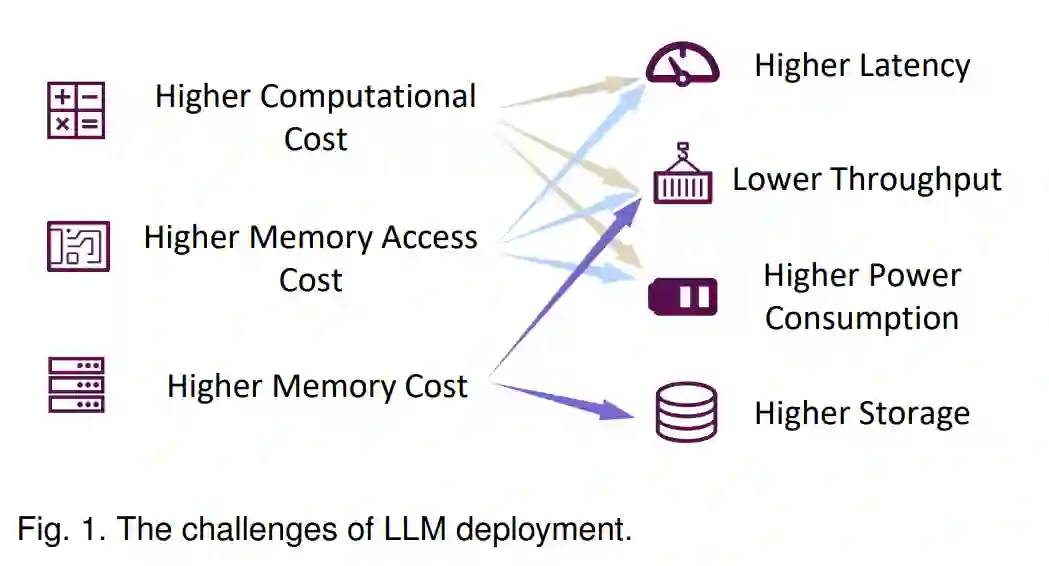
近年来,大型语言模型(LLMs)已经从学术界和工业界获得了大量关注。LLMs领域经历了显著的增长和重大成就。众多开源的LLMs已经出现,包括GPT系列(GPT-1 [1],GPT-2 [2],和GPT-3 [3]),OPT [4],LLaMA系列(LLaMA [5],LLaMA 2 [5],百川2 [6],Vicuna [7],长聊 [8]),BLOOM [9],FALCON [10],GLM [11],和Mistral [12],这些模型被用于学术研究和商业目的。LLMs的成功源于它们在处理各种任务(如神经语言理解(NLU),神经语言生成(NLG),推理 [13],[14] 和代码生成 [15])中的强大能力,从而使得如ChatGPT、Copilot和Bing等应用产生了重大影响。人们日益相信 [16],LLMs的崛起和成就标志着人类向人工通用智能(AGI)的重大步伐。然而,LLMs的部署并不总是顺利进行。如图1所示,LLMs在推理过程中通常需要更高的计算成本、内存访问成本和内存使用率(我们将在第2.3节分析根本原因),这降低了资源受限场景中的效率指标(例如,延迟、吞吐量、能耗和存储)。这为LLMs在边缘和云场景中的应用带来了挑战。例如,巨大的存储需求使得在个人笔记本电脑上部署一个700亿参数的模型用于开发辅助任务变得不切实际。此外,如果LLMs被用于每一个搜索引擎请求,低吞吐量将导致显著的成本,从而大幅降低搜索引擎的利润。
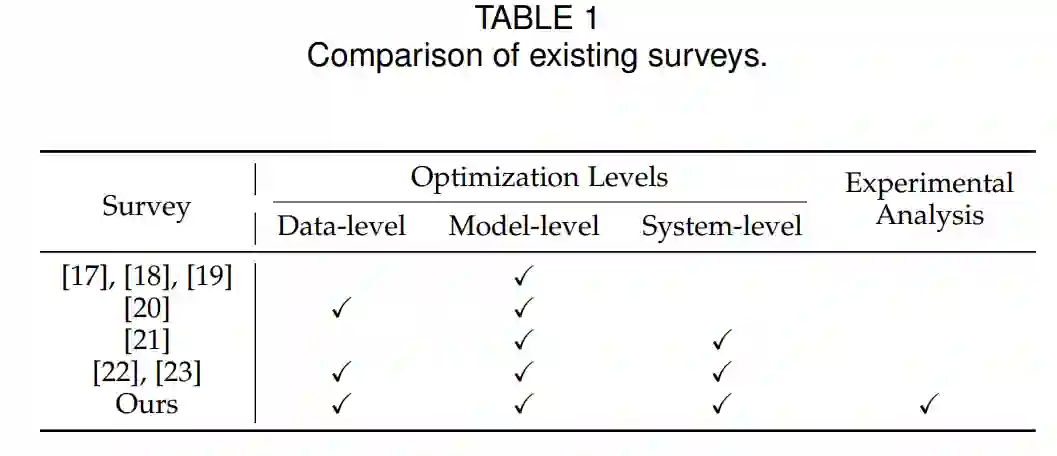
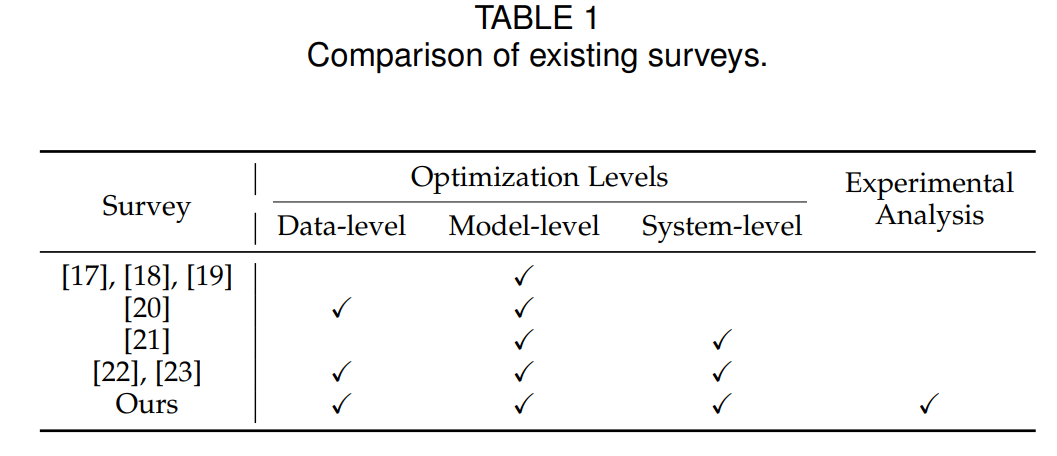
幸运的是,已经提出了大量技术以实现LLMs的高效推理。为了全面理解现有研究并激发进一步的研究,本综述采用了层次分类和系统总结的方法来描述高效LLM推理的当前景观。具体来说,我们将相关研究分为三个层次:数据级优化、模型级优化和系统级优化(详见第3节)。此外,我们对代表性方法进行了实验分析。目前,已经进行了几项综述 [17],[18],[19],[20],[21],[22],主要关注LLMs效率的不同方面,但仍提供了进一步改进的机会。朱等人 [17],朴等人 [18] 和王等人 [19] 关注于模型级优化中的模型压缩技术。丁等人 [20] 聚焦于考虑数据和模型架构的效率研究。苗等人 [21] 从机器学习系统(MLSys)研究的角度探讨高效LLM推理。与之相比,我们的综述提供了更全面的研究范围,涵盖了数据级、模型级和系统级的优化,并包括了最新的进展。尽管万等人 [22] 和徐等人 [23] 也提供了高效LLM研究的全面综述,我们的工作通过结合比较实验,并根据在几个关键子领域如模型量化和服务系统的实验分析提供实用的见解和建议,进一步扩展了这些工作。这些综述的比较总结在表1中。
本综述的其余部分安排如下:第2节介绍LLMs的基本概念和知识,并详细分析了LLMs推理过程中的效率瓶颈。第3节展示我们的分类法。第4节至第6节分别介绍和讨论在三个不同层次上的效率优化研究。第7节为几个关键应用场景提供更广泛的讨论。第8节总结了本综述提供的关键贡献。
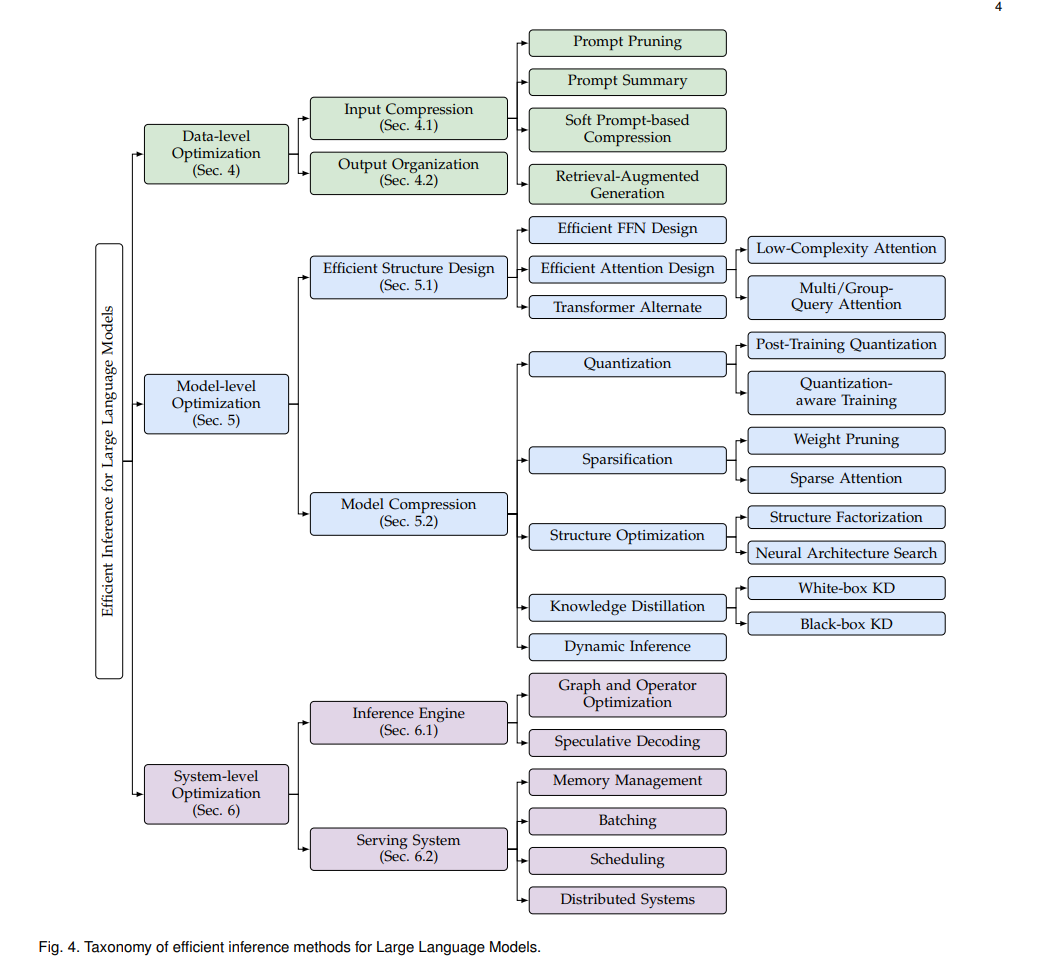
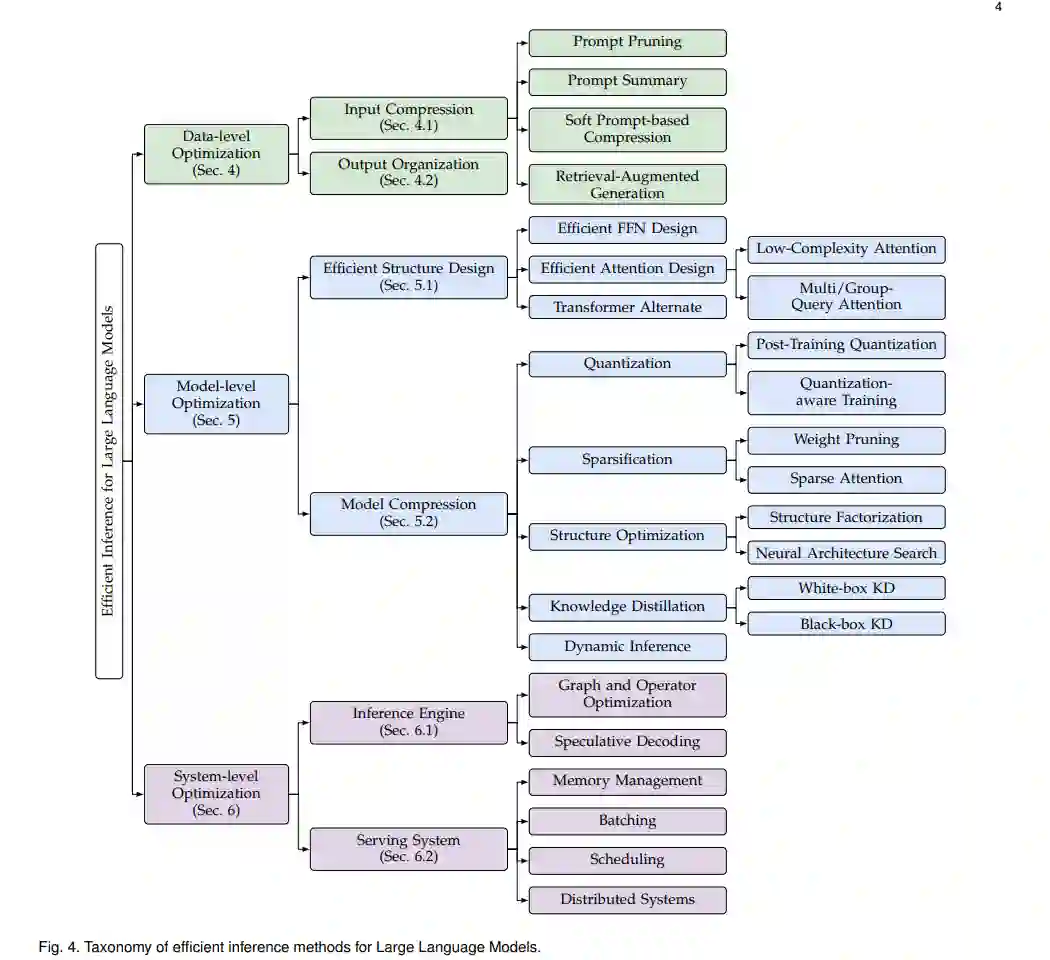
在上述讨论中,我们确定了三个关键因素(即计算成本、内存访问成本和内存使用),这些因素在LLM推理过程中显著影响效率,并进一步分析了三个根本原因(即模型大小、注意力操作和解码方法)。已经做出了许多努力,从不同的角度优化推理效率。通过仔细回顾和总结这些研究,我们将它们分类为三个层次,即数据级优化、模型级优化和系统级优化(如图4所示):
数据级优化指的是通过优化输入提示(即输入压缩)或更好地组织输出内容(即输出组织)来提高效率。这种优化线通常不会改变原始模型,因此无需昂贵的模型训练成本(注意,辅助模型可能需要少量训练,但与原始LLMs的训练成本相比,这种成本可以忽略不计)。
模型级优化指的是在推理过程中设计高效的模型结构(即高效结构设计)或压缩预训练模型(即模型压缩)以提高其效率。这种优化线(1)通常需要昂贵的预训练或较少量的微调成本以保持或恢复模型能力,并且(2)通常在模型性能上是有损的。
系统级优化指的是优化推理引擎或服务系统。这种优化线(1)不涉及昂贵的模型训练,并且(2)通常在模型性能上是无损的。另外,我们在第6.3节简要介绍了硬件加速器设计。