

在快速发展的自然语言生成(NLG)评估领域中,引入大型语言模型(LLMs)为评估生成内容质量开辟了新途径,例如,连贯性、创造力和上下文相关性。本综述旨在提供一个关于利用LLMs进行NLG评估的全面概览,这是一个缺乏系统分析的新兴领域。我们提出了一个连贯的分类体系来组织现有的基于LLM的评估指标,提供了一个结构化的框架来理解和比较这些方法。我们的详细探索包括批判性地评估各种基于LLM的方法论,以及比较它们在评估NLG输出时的优势和局限性。通过讨论尚未解决的挑战,包括偏见、稳健性、领域特定性和统一评估,本综述旨在为研究人员提供洞见,并倡导更公平、更先进的NLG评估技术。
自然语言生成(NLG)处于现代AI驱动通信的前沿,近期在大型语言模型(LLMs)方面的进展彻底改变了NLG系统的能力(Ouyang et al., 2022; OpenAI, 2023)。这些模型,依靠深度学习技术和大量的训练数据,展现出在广泛应用中生成文本的卓越能力。随着NLG技术的快速发展,建立可靠的评估方法以准确衡量生成内容的质量变得越来越重要。
传统的NLG评估指标,如BLEU(Papineni et al., 2002)、ROUGE(Lin, 2004)和TER(Snover et al., 2006),主要关注表面层面的文本差异,通常在评估语义方面存在不足(Freitag et al., 2020)。这一局限性已被指出阻碍了研究进展,并可能导致误导性的研究结论。此外,其他使用神经嵌入来计算分数的方法(Liu et al., 2016; Sellam et al., 2020; Zhang et al., 2020),尽管在评估诸如语义等价性和流畅性方面有所考虑,但它们的灵活性有限,适用范围受限(Freitag et al., 2021a)。此外,这些传统方法与人类判断的一致性较低(Liu et al., 2023c),且对分数的解释性不足(Xu et al., 2023)。这些缺点突显了NLG领域需要更细腻和全面的评估方法的需求。
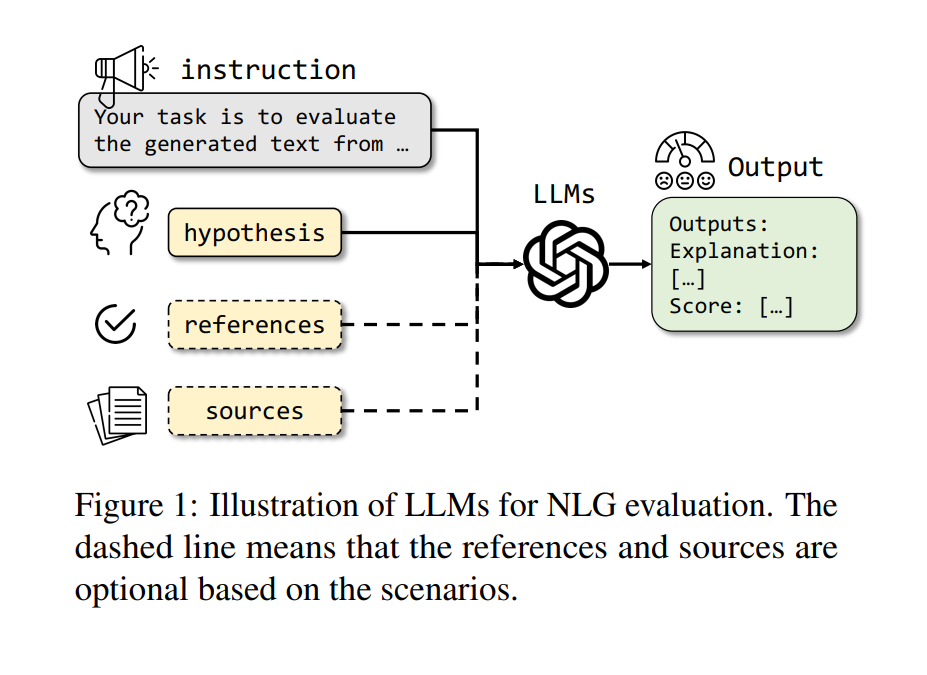
大型语言模型(LLMs)涌现的能力为基于LLM的NLG评估提供了有前景的途径,例如Chain-of-Thought(CoT)(Wei et al., 2022b)、零次学习指令跟随(Wei et al., 2022a)、更好地与人类偏好相一致(Ouyang et al., 2022)等。这些特性使LLMs成为评估NLG输出的有力工具,与传统方法相比提供了更为复杂和更好地与人类一致的评估(Liu et al., 2023c;Kocmi and Federmann, 2023;Fu et al., 2023)。例如,LLMs可以生成合理的解释来支持最终评分(Xu et al., 2023),而利用人类反馈的强化学习(RLHF)可以使LLMs的偏好更好地与人类一致(Ouyang et al., 2022;Zheng et al., 2023)。如图1所示,这些方法的关键策略涉及指示LLMs使用提示来从不同方面评估生成的文本,无论是否有参考资料和来源。然而,众多基于LLM的NLG评估方法,针对不同的任务和目标,缺乏统一的概述。
鉴于LLMs在NLG评估领域的工作量不断增加,迫切需要一个综合总结来导航这一领域内的复杂性和多样化方法。本综述旨在提供这一有前景领域的全面概述,呈现一个用于组织现有工作的连贯分类体系。我们详细勾勒了关键研究及其方法论,并深入分析了这些方法的各种优点、局限性和独特属性。此外,我们探索了该领域内尚未解决的挑战和开放性问题,从而为未来的学术探索勾画出潜在的途径。这一全面探索旨在激发读者对LLM在NLG评估中方法的细微差别和不断变化的动态有深入的了解。
本综述的组织:我们呈现了利用LLMs进行NLG评估的首个全面综述。首先,我们建立了NLG评估的正式框架,并提出了一个分类体系来分类相关工作(第2节)。随后,我们深入并详细阐述这些工作(第3节)。此外,我们对评估LLM评估者有效性的各种元评估基准进行了系统回顾(第4节)。鉴于这一领域的快速发展,我们确定并讨论了一些可能指导未来研究的潜在开放问题(第5节)。在结束这一系统综述时,我们倡导通过开发更公正、更稳健、更专业和统一的基于LLM的评估者来推动这一领域的发展。此外,我们强调整合其他评估方法,如人类判断,以实现更全面和多面的评估框架。
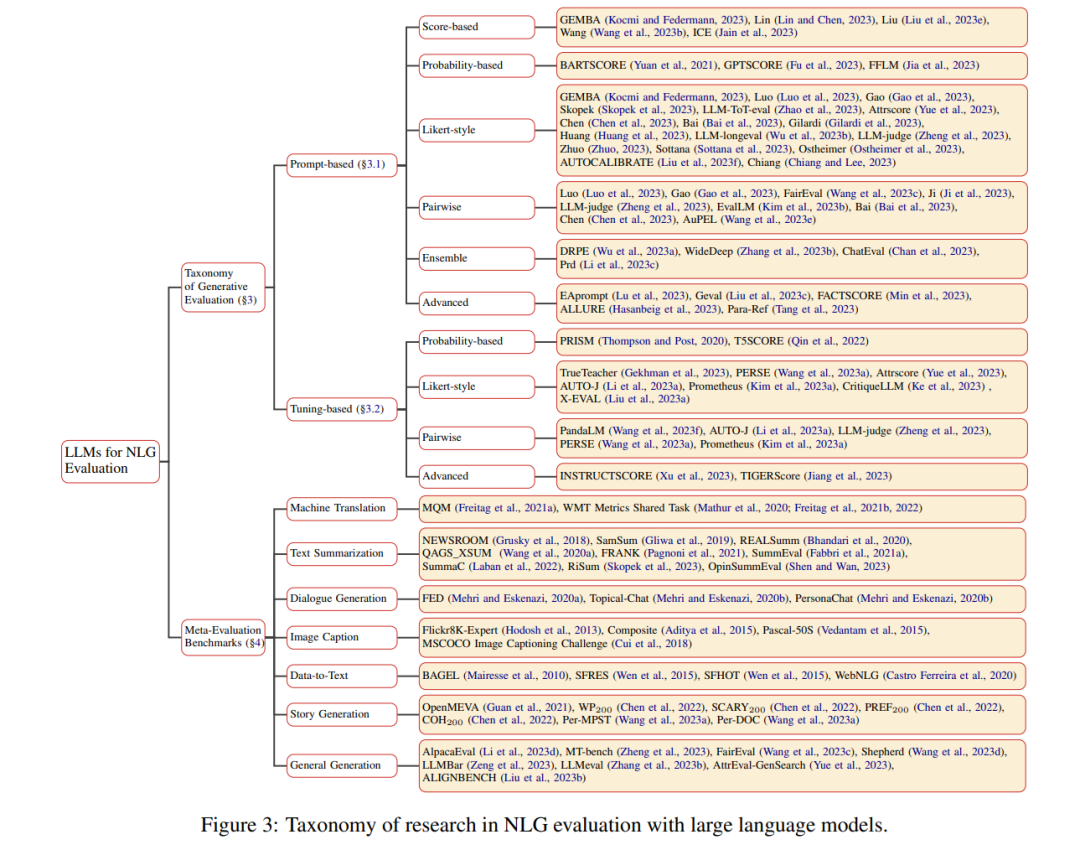
在大型语言模型(LLMs)迅速发展的背景下,越来越多的研究将重点放在利用这些模型作为NLG任务的评估者。这种关注特别源于LLMs的高容量生成能力,导致出现了使用它们来对NLG文本进行质量评估的工作——我们将这种范式称为生成性评估。这一类别大致分为基于提示的评估和基于微调的评估,其核心在于LLM评估者的参数是否需要微调。基于提示的评估通常涉及使用精心设计的提示指导强大的基础LLMs来评估生成的文本。另一方面,基于微调的评估依赖于专门为NLG评估校准的开源LLMs。这两种方法都适用于不同的评估协议,用于衡量生成文本的质量。
当前方法考虑不同的评分协议来判断生成假设文本的质量。一些尝试部署LLM评估者产生连续的标量分数,代表单个生成文本的质量——称为➊ 基于分数的评估。其他方法计算基于提示、来源或参考文本(可选)的生成文本的生成概率作为评估指标,称为➋ 基于概率的评估。在多样化的领域中,某些工作将NLG评估转化为分类任务,使用类似李克特量表的多级别对文本质量进行分类。在这种情况下,LLM评估者通过将生成的文本分配到特定的质量级别来评估其质量——称为➌ 李克特风格评估。同时,➍ 成对比较方法涉及使用LLM评估者比较一对生成文本的质量。此外,➎ 组合评估方法利用多个不同LLMs或提示的LLM评估者,协调评估者之间的沟通以产生最终评估结果。最后,一些最新的研究探索了➏ 高级评估方法(考虑细粒度标准或结合连续思考或上下文学习的能力),旨在获得更全面和细致的评估结果。
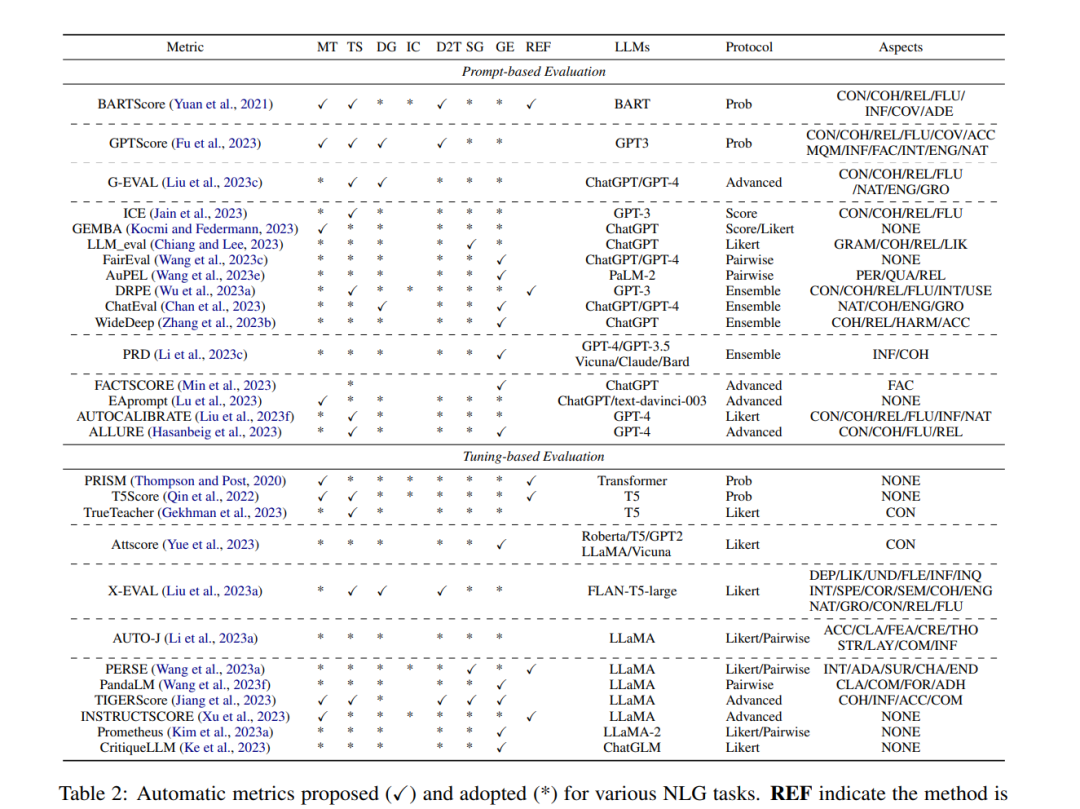
本节深入探讨了这两个主要类别的评估方法,每种方法都伴随其相应的评估协议。表2提供了当前基于提示和基于微调评估方法的全面概述。该表详细说明了它们各自的适应任务、基础模型、评分协议和评估方面,以便于清晰参考。
基于LLM的评估者已在多种NLG任务中找到应用。与此同时,众多现有和近期引入的元评估基准用于验证这些评估者的有效性。这些基准包括了对生成文本质量的人类注释,以及评估自动评估者和人类偏好之间一致性的程度。根据涉及的任务,这些基准可以被分类为单一场景示例,如机器翻译和摘要,以及多场景基准。本节将提供这些NLG任务及其相关元评估基准的概述。
结论
在本综述中,我们详尽地调查了LLMs在NLG评估中的作用。我们全面的分类体系按三个主要维度对作品进行分类:评估功能、评估参考和评估任务。这个框架使我们能够系统地分类和理解基于LLM的评估方法论。我们深入探讨了各种基于LLM的方法,审视它们的优势并比较它们的差异。此外,我们总结了NLG评估的普遍元评估基准。
在我们的研究中,我们强调了这一快速发展领域的进步和现存挑战。尽管LLMs在评估NLG输出方面提供了开创性的潜力,但仍有一些未解决的问题需要关注,包括偏见、稳健性、混合评估方法的整合,以及LLM评估者内部对特定领域和统一评估的需求。我们预计,解决这些挑战将为更通用、有效和可靠的NLG评估技术铺平道路。这样的进步将显著促进NLG评估的发展以及LLMs的更广泛应用。

