

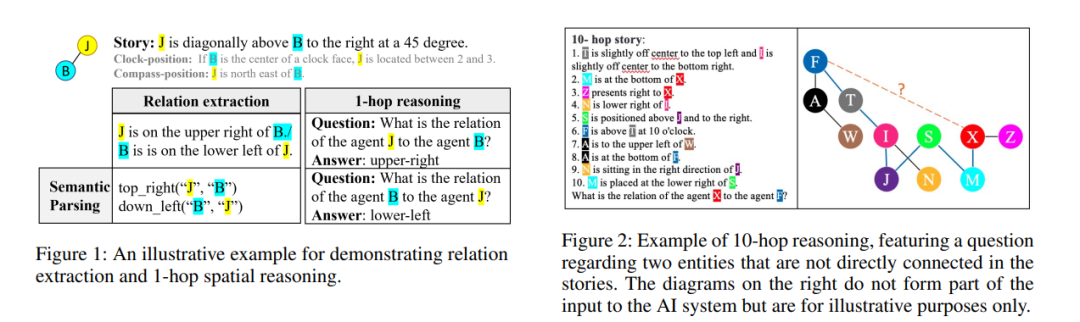
人工智能(AI)在各个领域取得了显著进展,像ChatGPT这样的大型语言模型因其类人的文本生成能力而获得了极大的关注。尽管取得了这些成就,空间推理仍然是这些模型的一个重大挑战。例如StepGame这样的基准测试评估了AI的空间推理能力,而ChatGPT在此方面的表现并不令人满意。 然而,基准测试中模板错误的存在影响了评估结果。因此,如果解决了这些模板错误,ChatGPT的表现有可能会更好,从而导致对其空间推理能力的更准确评估。在本研究中,我们对StepGame基准进行了精炼,为模型评估提供了更准确的数据集。我们分析了GPT在修正后基准上的空间推理表现,发现它在将自然语言文本映射到空间关系方面表现出熟练度,但在多跳推理方面存在限制。我们通过结合模板到关系的映射和基于逻辑的推理,为基准提供了一个无瑕疵的解决方案。这种结合展示了在StepGame上进行定性推理的熟练度,且没有遇到任何错误。接着,我们解决了GPT模型在空间推理方面的限制。我们部署了连续思考和树状思考的提示策略,提供了对GPT“认知过程”的洞察,并实现了准确性的显著提升。我们的调查不仅揭示了模型的不足,还提出了增强功能,为具有更强大空间推理能力的AI的进步做出了贡献。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日