

在过去的十年中,基于人类研究者手动设计的算法,深度强化学习(RL)取得了巨大的进展。最近,已经证明可以元学习更新规则,希望发现能够在广泛的RL任务上表现良好的算法。尽管从像Learned Policy Gradient(LPG)这样的算法中获得了令人印象深刻的初步结果,但当这些算法应用于未见过的环境时仍然存在泛化差距。在这项工作中,我们研究元训练分布的特性如何影响这些算法的泛化性能。受此分析的启发,并基于来自无监督环境设计(UED)的想法,我们提出了一种新颖的方法,自动生成课程以最大化元学习优化器的遗憾,并提出了一种我们称为算法遗憾(AR)的遗憾新近似。结果是我们的方法——通过环境设计获得的通用RL优化器(GROOVE)。在一系列实验中,我们显示GROOVE在泛化方面优于LPG,并评估AR与UED的基线指标,将其确定为在这种设置中环境设计的关键组成部分。我们相信这种方法是朝着发现真正通用的RL算法的一步,这些算法能够解决广泛的真实世界环境。
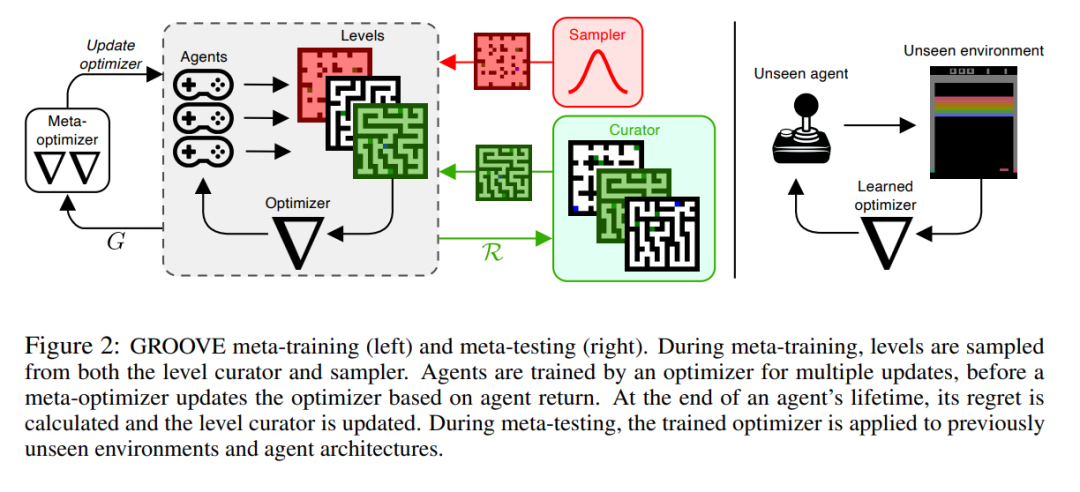
过去十年里,深度强化学习[Sutton 和 Barto, 1998, RL]取得了巨大的进展,这是一个范式,其中智能体与环境互动以最大化标量奖励。特别地,深度RL智能体已经学会了掌握复杂的游戏[Silver 等, 2016, 2017, Berner 等, 2019],控制实体机器人[OpenAI 等, 2019, Andrychowicz 等, 2020, Miki 等, 2022],并越来越多地解决真实世界的任务[Degrave 等, 2022]。然而,这些成功是由手工设计的算法推动的,这些算法经过多年的优化,来应对RL中的新挑战。因此,当这些方法转移到新任务时,它们并不总是展现出相同的性能[Henderson 等, 2018, Andrychowicz 等, 2021],并受到我们对RL的直觉的限制。近期,元学习已经成为一种用数据驱动的方式发现通用RL算法的有希望的方法[Beck 等, 2023b]。特别地,Oh 等[2020]引入了Learned Policy Gradient (LPG),显示可以在玩具环境上元学习一个更新规则,并将其无缝转移到在具有挑战性的未见过的领域上训练策略。尽管初步结果令人印象深刻,但当这些算法应用于未知环境时,仍存在显著的泛化差距。在这项工作中,我们希望通过研究元训练分布的特性如何影响这些算法的泛化来学习通用和鲁棒的RL算法。受此分析的启发,我们的目标是自动学习一个元训练分布。我们基于无监督环境设计[Dennis 等, 2020, UED]的思想,这是一个范式,其中学生智能体在一个老师提议的适应性环境分布上进行训练,老师试图提议最大化学生遗憾的任务。UED通常被应用于训练单个的RL智能体,已被证明能生成能够无缝迁移至具有挑战性的人为设计任务的稳健策略。相反,我们将UED应用于元RL设置,元学习一个策略优化器,我们称其为策略元优化(PMO)。为此,我们提出算法遗憾(AR),一个用于选择元训练任务的新指标,除此之外,还基于LPG和UED的思想构建了一种方法。我们将我们的方法命名为通过环境设计获得的通用RL优化器,或称GROOVE。
我们在无结构的格子世界环境分布上训练GROOVE,并严格地检查其在各种未见过的任务上的表现——从具有挑战性的格子世界到Atari游戏。与LPG相比,GROOVE在所有这些领域上都取得了显著改善的泛化性能。此外,我们将AR与UED文献中提出的先前环境设计指标进行了比较,确定它是这一设置中环境设计的关键组成部分。我们相信这种方法是朝着发现真正通用的RL算法的方向迈出的一步,这些算法有能力解决各种真实世界的环境。
我们在JAX [Bradbury等,2018]中实现了GROOVE和LPG,这导致在单个V100 GPU上的元训练时间为3小时。作为LPG的第一个完整且开源的实现,与参考实现相比,我们实现了主要的加速,后者在16核的TPU-v2上需要24小时。这将使学术实验室能够在这个领域进行后续研究,其中计算约束长期以来一直是一个限制因素。
我们的贡献可以总结如下:• 为了区分这个问题设定与传统的元-RL,我们使用Meta-UPOMDP(第2.1节)为PMO提供了一个新的公式化描述。• 我们提出了AR(第3.2节)——一种用于PMO的新的遗憾近似,以及GROOVE(第3.3节)——一种使用AR进行环境设计的PMO方法。• 我们分析了元训练分布的特性如何影响PMO的泛化(第4.2节),并展示AR作为任务信息度的代理(第4.3节)。• 我们对GROOVE和LPG进行了广泛的评估,展示了在分布内的稳健性和分布外的泛化性能的提高(第4.4节)。• 我们进行了AR的消融实验,展示了没有AR的现有方法(PLR和LPG)的不足,以及AR中对抗代理的影响(第4.5节)。

