【CVPR2023】基于图像特定提示学习的零样本生成模型自适应

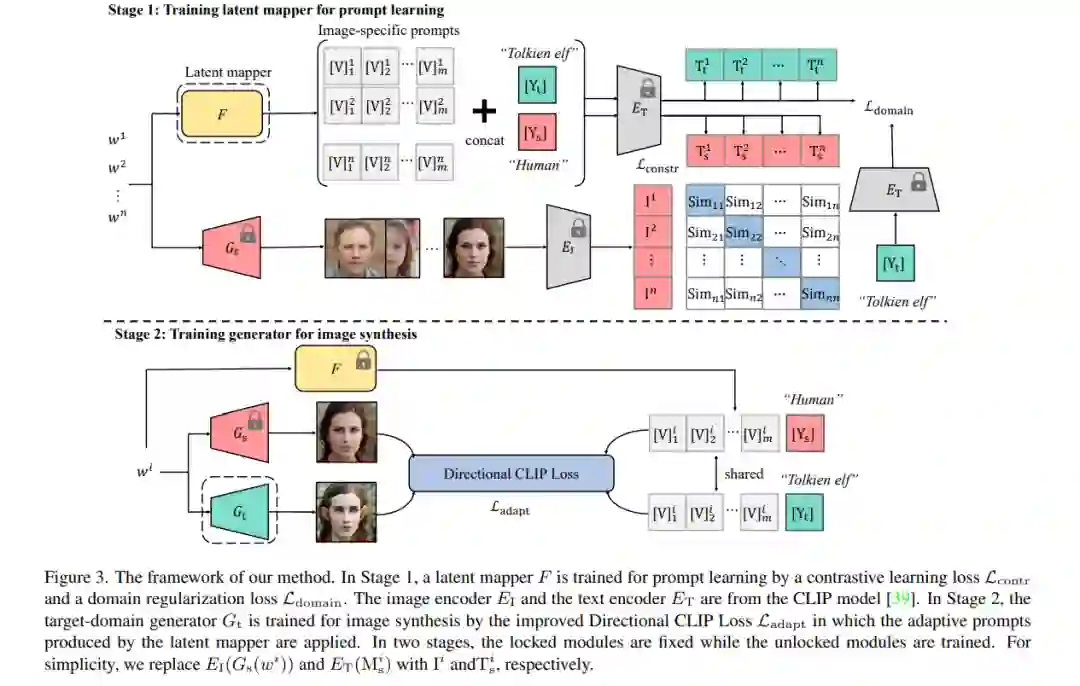
最近,CLIP引导的图像合成在将预训练的源域生成器适应于未见过的目标域方面表现出了诱人的性能。它不需要任何目标域样本,只需要文本域标签。训练是非常高效的,例如,几分钟。然而,现有方法在生成图像的质量方面仍然存在一定的局限性,并且可能会出现模式崩溃的问题。一个关键的原因是对所有的跨域图像对应用固定的自适应方向,从而导致相同的监督信号。为了解决这个问题,本文提出了一种图像特定提示学习(image -specific Prompt Learning, IPL)方法,为每个源域图像学习特定的提示向量。为每个跨域图像对生成一个更精确的自适应方向,使目标域生成器具有更大的灵活性。不同领域的定性和定量评估表明,IPL有效地提高了合成图像的质量和多样性,缓解了模式崩溃。此外,IPL独立于生成模型的结构,如生成对抗网络或扩散模型。代码可以在https://github.com/Picsart-AI-Research/IPLZero-Shot-Generative-Model-Adaptation上找到。
https://arxiv.org/pdf/2304.03119.pdf
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复或发消息“PLI” 就可以获取《【CVPR2023】基于图像特定提示学习的零样本生成模型自适应》专知下载链接



登录查看更多
相关内容
专知会员服务
34+阅读 · 2020年6月19日


相关VIP内容
专知会员服务
34+阅读 · 2020年6月19日
相关资讯
相关论文