

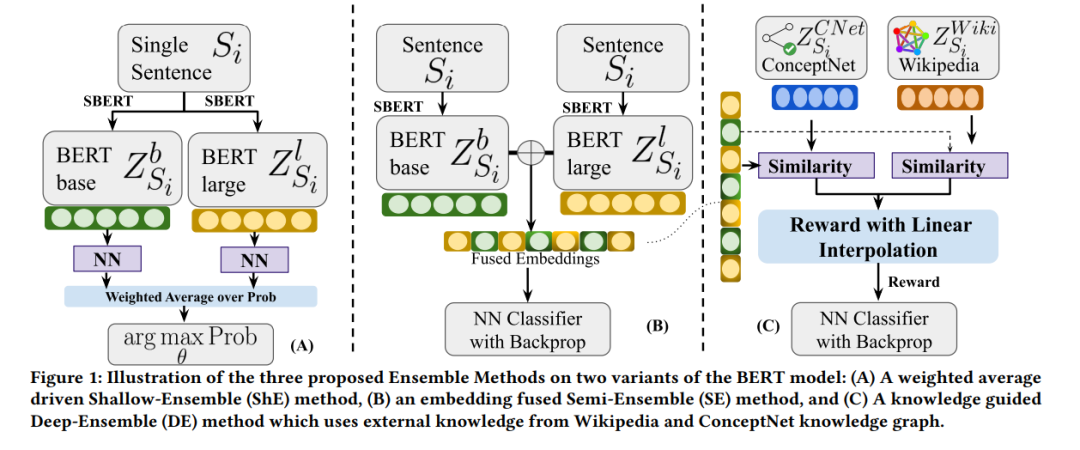
自然语言处理(NLP)社群一直在使用众包技术来创建基准数据集,例如用于训练现代语言模型(LMs)如BERT的通用语言理解与评估(GLUE)。GLUE任务使用互注解者度量(如Cohen的Kappa(𝜅))来衡量可靠性分数。然而,LMs的可靠性方面经常被忽视。为了解决这个问题,我们探索了一种由知识引导的LM集成方法,该方法利用强化学习来整合来自ConceptNet和维基百科的知识图谱嵌入。这种方法模仿人类注解者依赖外部知识来弥补数据集中的信息缺陷。在九个GLUE数据集中,我们的研究显示集成增强了可靠性和准确性分数,超过了现有最先进的方法。
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年11月2日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年11月2日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日