预训练模型如何用在视觉任务?南洋理工最新《视觉语言模型》综述,全面概述视觉语言模型方法体系

视觉识别(如图像分类、目标检测和语义分割)是计算机视觉研究中长期存在的挑战,也是自动驾驶[1]、[2]、遥感[3]、[4]、机器人[5]、[6]等无数计算机视觉应用的基石。随着深度学习[7]、[8]、[9]的出现,视觉识别研究通过利用端到端的可训练深度神经网络(DNNs)取得了巨大的成功。然而,从传统机器学习[10]、[11]、[12]、[13]向深度学习的转变带来了两个新的重大挑战,即深度学习从零开始[7]、[8]、[9]的经典设置下的DNN训练收敛缓慢,以及在DNN训练中费力耗时地收集大规模、特定任务、众标数据[14]。
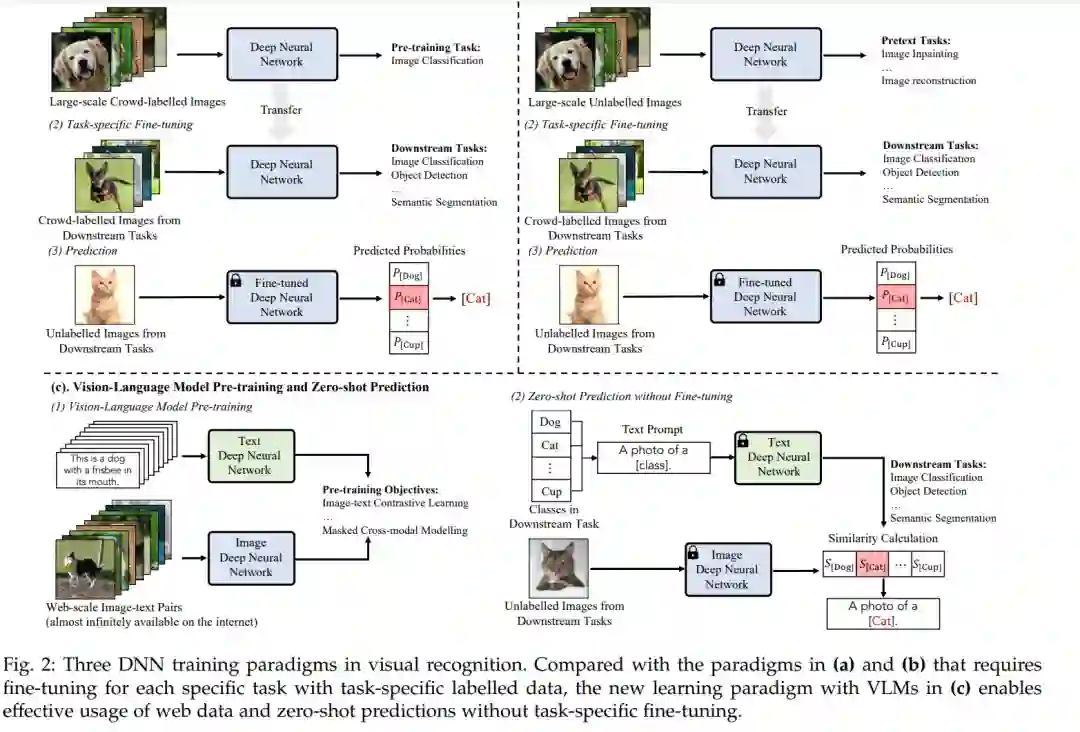
最近,一种新的学习范式预训练、微调和预测在广泛的视觉识别任务[15]、[16]、[17]、[18]、[19]中表现出了巨大的有效性。在这种新范式下,DNN模型首先用某些现成的大规模训练数据(被标注或未标注)进行预训练,然后用图2(a)和(b)所示的特定任务标注训练数据对预训练模型进行微调。通过在预训练模型中学习到的全面知识,这种学习范式可以加速网络收敛,并为各种下游任务训练表现良好的模型。
尽管如此,预训练、微调和预测范式仍然需要一个额外的阶段,使用来自每个下游任务的标记训练数据进行特定任务的微调。受自然语言处理[20],[21],[22],[23]进展的启发,一种名为视觉-语言模型预训练和零样本预测的新的深度学习范式最近受到越来越多的关注[14],[24],[25]。在这种范式中,一种视觉-语言模型(VLM)是用互联网上几乎无限可用的大规模图像-文本对进行预训练的,预训练的VLM可以直接应用于下游视觉识别任务,而无需微调,如图2(c)所示。VLM预训练通常由某些视觉-语言目标[14],[25],[26]指导,使其能够从大规模图像-文本对[27],[28]中学习图像-文本对应关系,例如:CLIP[14]采用图像-文本对比目标,通过在嵌入空间中将成对的图像和文本拉近并将其他图像和文本推远来进行学习。通过这种方式,预训练的vlm捕获了丰富的视觉-语言对应知识,并可以通过匹配任何给定图像和文本的嵌入来进行零样本预测。这种新的学习范式能够有效地利用网络数据,并允许零样本预测,而不需要特定任务的微调,实现起来很简单,但表现得非常好,例如,预训练的CLIP在36个视觉识别任务中实现了出色的零样本性能,从经典图像分类[29],[30],[31],[32],[33]到人类行为和光学字符识别[14],[34],[35],[36],[37]。
随着视觉-语言模型预训练和零样本预测的巨大成功,在各种VLM预训练研究之外,人们还深入研究了两条研究路线。第一行探索了带有迁移学习[38],[39],[40],[41]的vlm。几个迁移方法证明了这一点,例如,提示调优[38],[39],视觉适应[40],[41]等,所有预训练的vlm对各种下游任务的有效适应都具有相同的目标。第二行通过知识蒸馏[42],[43],[44]探索vlm,例如,[42],[43],[44]探索如何从VLM中提取知识到下游任务,旨在在目标检测,语义分割等方面取得更好的性能。
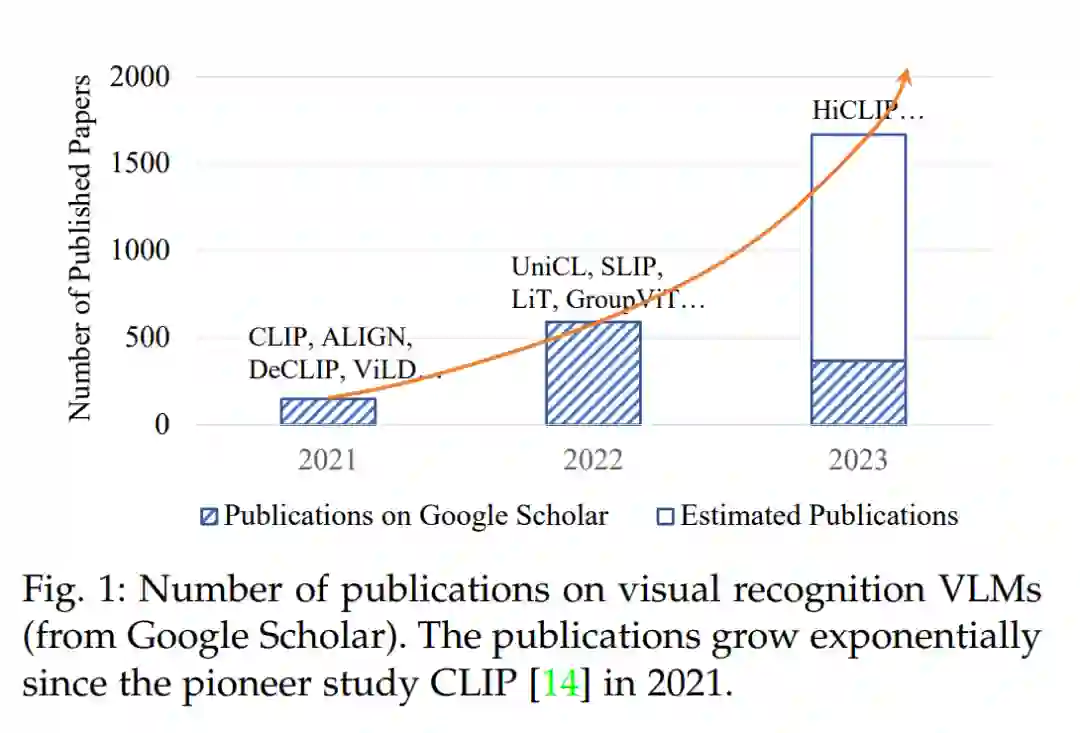
尽管从图1所示的大量近期论文中证明了从VLM中获取大量知识的浓厚兴趣,但研究界缺乏一份全面的调查,可以帮助梳理现有的基于VLM的视觉识别研究、面临的挑战以及未来的研究方向。我们的目标是通过对各种视觉识别任务(包括图像分类、目标检测、语义分割等)中的VLM研究进行系统的综述来填补这一空白。
从不同的角度进行了综述,包括背景、基础、数据集、技术方法、基准和未来的研究方向。我们相信,这项调查将为我们已经取得的成就提供一个清晰的蓝图,我们可以沿着这个新兴但非常有前瞻性的研究方向进一步取得成就。
总而言之,这项工作的主要贡献有三个方面。首先,对用于图像分类、目标检测和语义分割等视觉识别任务的VLMs进行了系统综述。据我们所知,这是视觉识别VLMs的第一次综述,通过对现有研究的全面总结和分类,为这个有前途的研究领域提供了一个大的图景。其次,研究了视觉识别VLM的最新进展,包括对多个公共数据集上的现有工作进行全面的基准测试和讨论。第三,分享了几个用于视觉识别的VLM中可以追求的研究挑战和潜在研究方向。
本综述的其余部分组织如下。第2节介绍了视觉识别的范式发展和几个相关的调查。第3节描述了VLM的基础,包括广泛使用的深度网络架构、预训练目标和VLM评估中的下游任务。第4节介绍了常用的VLM预训练和评估中的数据集。第5节回顾并分类了VLM预训练方法。第6节和第7节分别对VLM的迁移学习和知识蒸馏方法进行了系统综述。第8节在多个广泛采用的数据集上对所审查的方法进行了基准测试和分析。最后,我们在第9节中分享了视觉识别的几个有前途的VLM研究方向。
2 背景
本节介绍了视觉识别训练范式的发展,以及它如何向视觉-语言模型预训练和零样本预测范式演进。我们还讨论了几个相关的综述,以突出本综述的范围和贡献。
2.1 视觉识别的训练范式
视觉识别范式的发展大致可以分为五个阶段,包括(1)传统机器学习和预测,(2)深度从头学习和预测,(3)有监督的预训练、微调和预测,(4)无监督的预训练、微调和预测和(5)视觉-语言模型预训练和零样本预测。在接下来的内容中,我们将对这五种训练范式进行详细介绍、比较和分析。
2.1.1 传统的机器学习和预测
在深度学习时代[7]之前,视觉识别研究严重依赖特征工程,使用手工特征[13]、[45]、[46]、[47]、[48]、[49]、[50]、[51]和轻量级学习模型[10]、[11]、[12]将手工特征分类为预定义的语义类别。例如,经典的SIFT特征[51]对图像尺度、平移和旋转的变化具有容忍度,实现了非常令人印象深刻的视觉识别性能。然而,这种范式需要领域专家为特定的视觉识别任务制作有效的特征,不能很好地应对复杂的任务,也具有较差的可扩展性。
2.1.2深度学习从零开始和预测
随着深度学习[7]、[8]、[9]的出现,视觉识别研究通过利用端到端的可训练dnn,用单一框架统一特征提取和分类过程,取得了巨大的成功。基于dnn的视觉识别绕开了复杂的特征工程,在很大程度上专注于神经网络的架构工程,以学习有效特征。例如,ResNet[9]通过跳跃设计实现了有效的深度网络,并可以从大量群体标记的数据中学习语义特征,在具有挑战性的1000类ImageNet分类任务[52]上取得了前所未有的性能。另一方面,从传统机器学习向深度学习的转变提出了两个新的重大挑战,包括从头开始深度学习的经典设置下的DNN训练收敛缓慢,以及DNN训练中费力且耗时地收集大规模、特定任务和众标数据[14]。
2.1.3 有监督的预训练、微调和预测
随着发现从标记的大规模数据集中学习到的特征可以迁移到下游任务[15],[16],[17],从头学习和预测的范式已经逐渐被有监督的预训练、微调和预测的新范式所取代。这种新的学习范式,如图2(a)所示,以监督损失对大规模标记数据(如ImageNet)进行预训练DNN,然后用特定任务的训练数据[15]、[16]、[17]对预训练的DNN进行微调。由于预训练的dnn已经学习了一定的视觉知识,它可以加速网络收敛,并帮助用有限的特定任务训练数据训练出表现良好的模型。
虽然范式监督预训练、微调和预测在许多视觉识别任务上实现了最先进的性能,但它在预训练中需要大规模的标记数据。为了缓解这一限制,最近的研究[18]、[19]采用了一种新的学习范式无监督预训练、微调和预测,探索自监督学习从无标记数据中学习有用和可转移的表示,如图2(b)所示。为此,各种自监督训练目标(即,伪装任务)[18]、[53]、[54]、[55]、[56]被提出,包括学习上下文信息的图像修复[53],建模跨块关系的掩码图像建模[54],通过对比训练样本[18]来学习判别式特征的对比学习等。然后,自监督预训练模型在带有标记任务特定训练数据的下游任务上进行微调。由于这种范式在预训练中不需要标记数据,它可以利用更多的训练数据来学习有用的和可迁移的特征,与监督预训练[18]、[19]相比,导致甚至更好的性能。
2.1.5 VLM预训练和零样本预测
尽管有监督或无监督预训练的预训练和微调范式提高了网络收敛性,但它仍然需要一个额外的阶段对图2(a)和(b)所示的带标签的特定任务训练数据进行微调。受自然语言处理的预训练成功[20],[21],[22],[23]的激励,一种名为视觉-语言模型预训练和零样本预测的新深度学习范式被提出用于视觉识别,如图2(c)所示。在互联网上几乎无限可用的大规模图像-文本对的情况下,VLM由特定的视觉-语言目标[14],[25],[26]进行预训练。通过这种方式,预训练的vlm捕获了丰富的视觉-语言对应知识,并可以通过匹配任何给定图像和文本的嵌入,对下游视觉识别任务进行零样本预测(无需微调)。
与预训练和微调相比,这种新的范式可以在不进行特定任务微调的情况下有效利用大规模网络数据和零样本预测。大多数现有研究探索从三个角度来改进VLM: 1) 收集大规模信息丰富的图像-文本数据,2) 设计高容量模型以从大数据中有效学习,3) 设计新的预训练目标用于学习有效的视觉-语言关联。本文对视觉识别的这一新的视觉-语言学习范式进行了系统的综述,旨在为现有的VLM研究、这一具有挑战性但非常有前途的研究领域面临的挑战和未来方向提供一个清晰的蓝图。
3 VLM基础
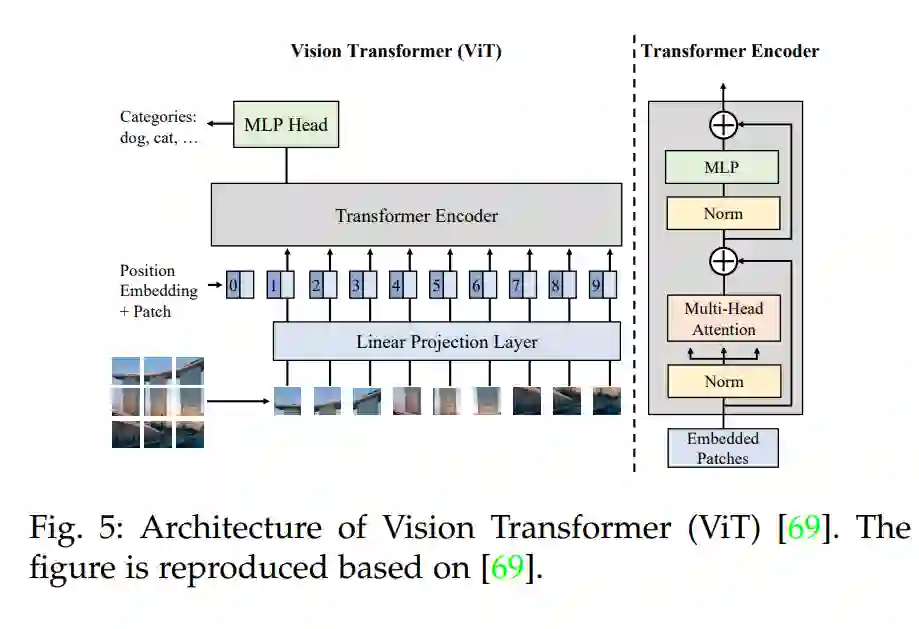
VLM预训练[14],[24]旨在预训练一个VLM来学习图像-文本相关性,针对视觉识别任务的有效零样本预测[9],[66],[67],[68]。给定图像-文本对[27],[28],它首先采用一个文本编码器和一个图像编码器来提取图像和文本特征[9],[20],[69],[70],然后学习与某些预训练目标[14],[24]的视觉-语言相关性。有了学习到的视觉-语言相关性,VLMs可以在未见过的数据上以零样本的方式进行评估[14],[24],通过匹配任何给定图像和文本的嵌入。在本节中,我们介绍了VLM预训练的基础,包括用于提取图像和文本特征的常见深度网络架构,用于建模视觉-语言相关性的预训练目标,以及用于评估预训练的VLM的下游任务。
4 数据集
本节总结了用于VLM预训练和评估的常用数据集,如表1-2所示。
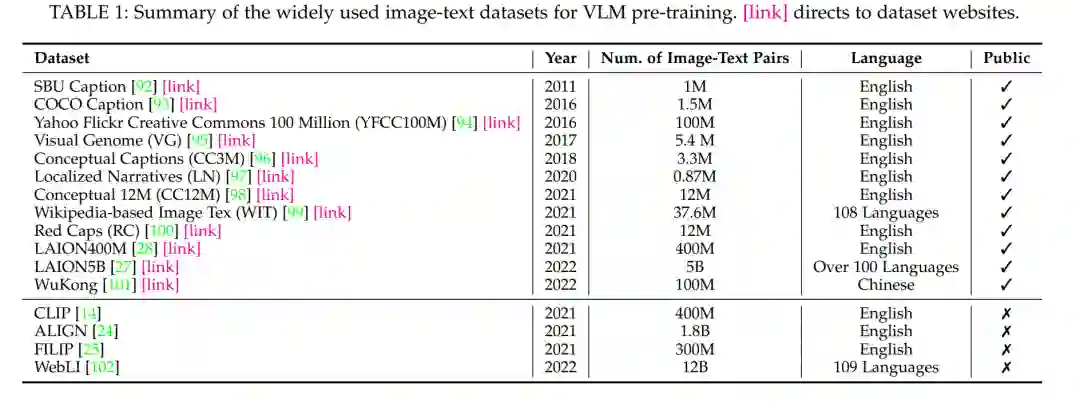
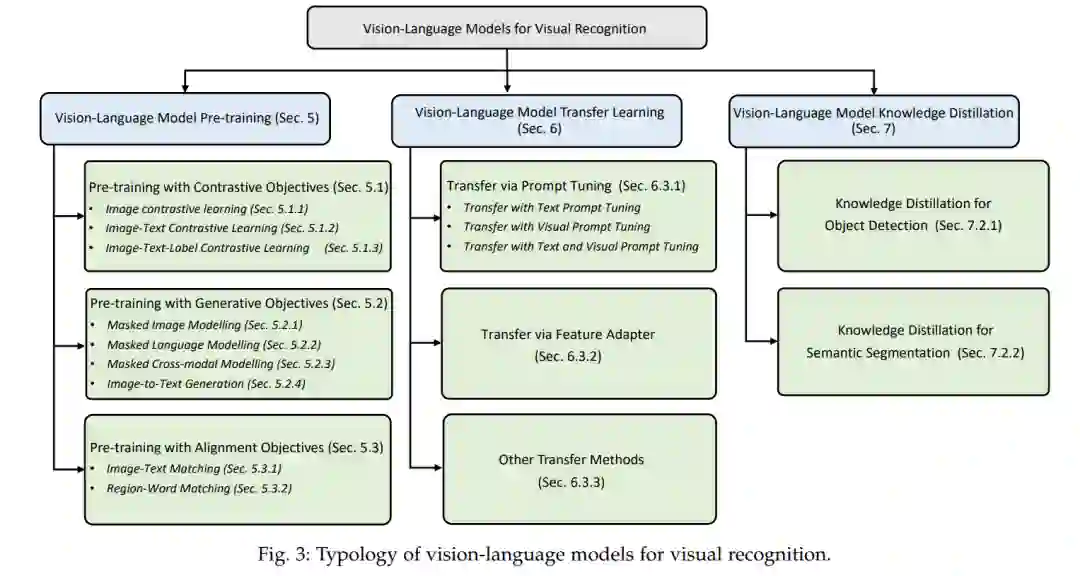
5 视觉-语言模型预训练
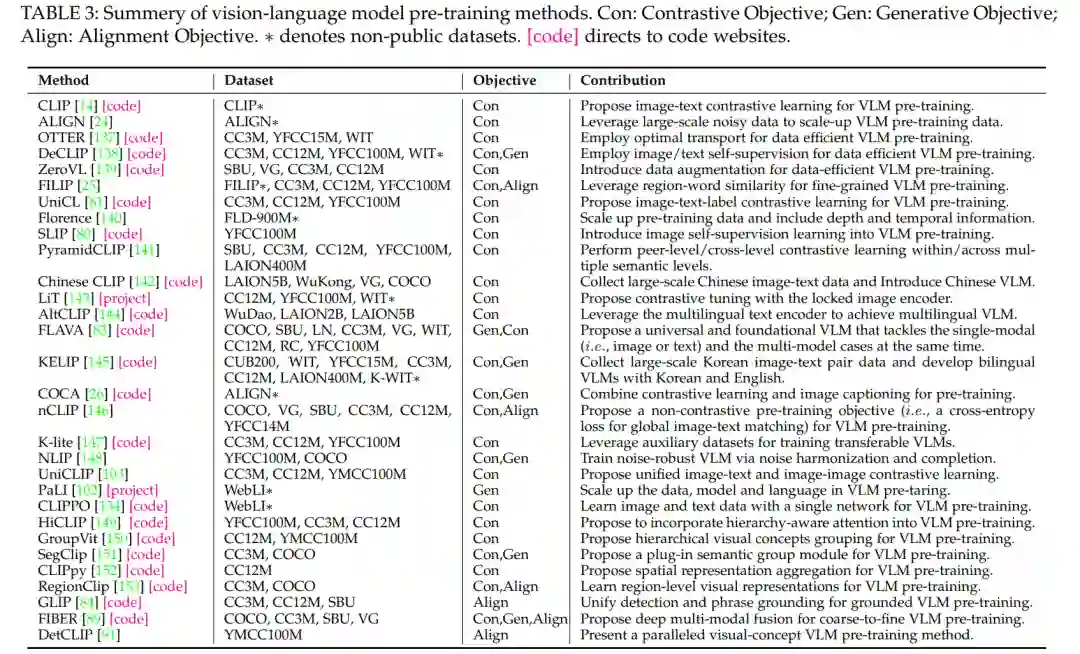
如第3.2节所述,VLM预训练已经用三种典型的方法进行了探索,包括对比目标、生成目标和对齐目标。本节通过表3所列的多个VLM预训练研究对它们进行了回顾。
5.1 具有对比目标的VLM预训练
对比学习在VLM预训练中已经被广泛探索,它为学习具有判别力的图像-文本特征设计了对比目标[14],[80],[138]。
5.2 带有生成目标的VLM预训练
生成式VLM预训练通过学习通过掩码图像建模、掩码语言建模、掩码跨模态建模和图像到文本生成生成图像或文本来学习语义知识。
5.3 带有对齐目标的VLM预训练
对齐目标通过学习预测给定的文本是否正确描述了给定的图像,强制vlm对齐成对的图像和文本。它可以大致分为全局图像-文本匹配和局部区域-单词匹配,用于VLM预训练。
5.4 总结和讨论
总而言之,VLM预训练对具有不同跨模态目标的视觉-语言相关性进行建模,如图像-文本对比学习、掩码跨模态建模、图像到文本生成和图像-文本/区域-单词匹配。还探索了各种单模态目标,以充分挖掘其自身模态的数据潜力,如针对图像模态的掩码图像建模和针对文本模态的掩码语言建模。另一方面,最近的VLM预训练专注于学习全局视觉-语言相关性,在图像级识别任务(如图像分类)中有好处。同时,多项研究[84]、[89]、[91]、[150]、[151]、[152]、[153]通过区域-单词匹配对局部细粒度视觉-语言相关性进行建模,旨在在目标检测和语义分割中实现更好的密集预测。
6 VLM迁移学习
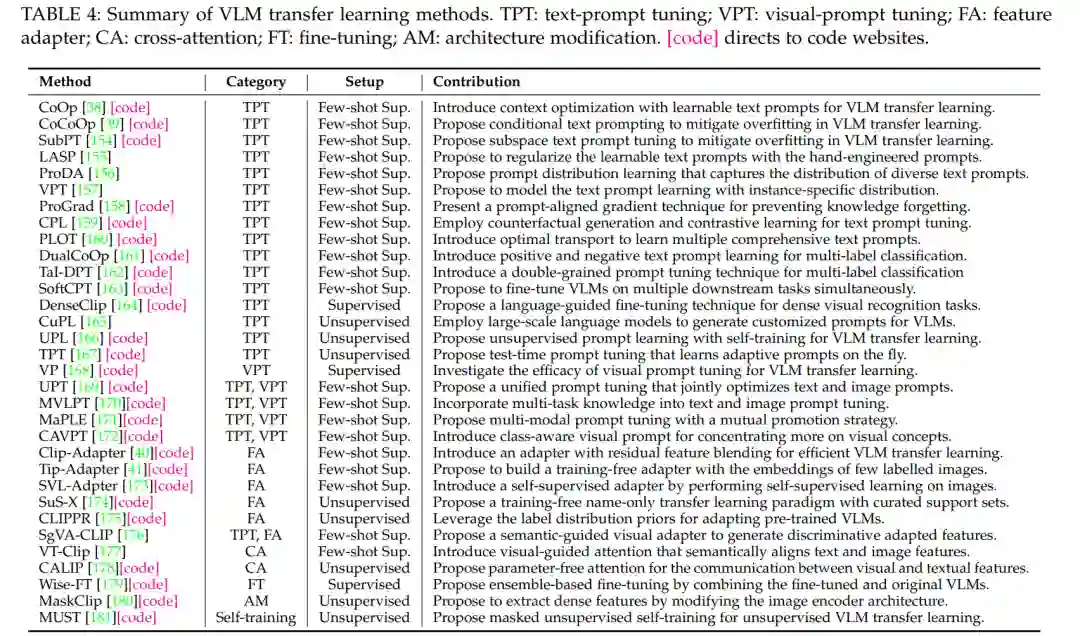
除了在没有微调的情况下直接将预训练的VLM应用于下游任务的零样本预测外,最近研究了迁移学习,通过提示微调[38],[154],特征适配器[40],[41]等使VLM适应下游任务。本节介绍了预训练VLM的迁移学习动机、常见的迁移学习设置以及三种迁移学习方法,包括提示调优方法、特征适配器方法和其他方法。
7 VLM知识蒸馏
由于VLM捕获了涵盖广泛的视觉和文本概念的通用知识,一些研究探索了如何提取通用和鲁棒的VLM知识,同时解决复杂的密集预测任务,如目标检测和语义分割。本节介绍了从VLM中提取知识的动机,以及两组关于语义分割和目标检测任务的知识蒸馏研究。

7. 结论
用于视觉识别的视觉-语言模型能够有效地使用web数据,并允许零样本预测,而无需特定任务的微调,这很容易实现,但在广泛的识别任务中取得了巨大的成功。本综述从背景、基础、数据集、技术方法、基准测试和未来研究方向等几个角度广泛回顾了视觉识别的视觉-语言模型。以表格的形式对VLM数据集、方法和性能进行了比较总结,为VLM预训练的最新发展提供了一个清晰的蓝图,这将极大地有利于这个新兴但非常有前途的研究方向的未来研究。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复或发消息“VLMS” 就可以获取《预训练模型如何用在视觉任务?南洋理工最新《视觉语言模型》综述,全面概述视觉语言模型方法体系》专知下载链接



