本文介绍我们被AAAI'22接收的工作《On the Efficacy of Small Self-Supervised Contrastive Models without Distillation Signals》。
https://www.zhuanzhi.ai/paper/3e62e1f673466df464ee1dafe962c576
在确定研究小模型对比学习这个方向的时候,正好是CompRess[1]、SEED[2]等工作刚刚发表的时候。原本我们的计划是沿着知识蒸馏(Knowledge Distillation)希望进一步提升小模型自监督的SOTA表现,但是很快我们意识到了几个问题:
首先,现有工作汇报的小模型基线使用的一律都是ResNet50架构下的默认设置,还没有对自监督小模型训练效能的研究;
其次,研究蒸馏方法在小模型上的应用本质上不是一个自监督学习问题。因为这个时候大模型成为小模型的监督信号,原本利用数据进行增强让网络学习到某种不变形的自监督学习在这个时候退化成为了一个简单的regression问题;
最后,蒸馏方法往往需要部署一个大的网络,这在一些计算资源受到限制的场景里并不是非常适用,这也再一次增强了我们想要单纯研究小模型自身对比学习效能的动机。
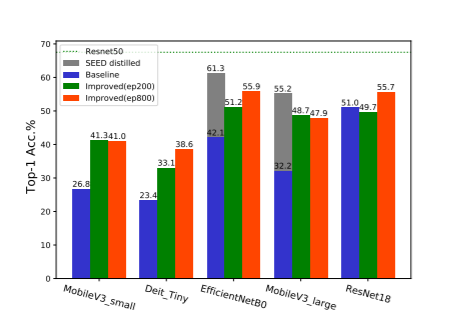
值得一提的是,前人的工作对小模型为什么在对比学习框架下表现糟糕给出了统一的猜想:对比学习这种instance discrimination的前置任务需要区分的类太多,对小模型来说太过困难,因此小模型在这样的前置任务上没有办法学到比较好的特征[2,3,4]。但事实上我们后面会看到,这个假设并没有说服力。解释小模型为什么学不到好的表征空间依旧是一个需要探索的方向。
本文主要研究并验证了小模型在没有蒸馏信号引导下自监督训练的可行性,希望能够给小领域的同行带来一些有用的信息。综合上述的结果,我们验证了即使在训练时不需要大模型提供的蒸馏信号引导,小模型的自监督表现依然能够达到一个不错的水平。我们希望这项工作能够为未来小模型自监督领域的工作带来一些启发,欢迎志同道合的朋友们在评论区分享自己的观点~
文章链接:[2107.14762] On the Efficacy of Small Self-Supervised Contrastive Models without Distillation Signals (arxiv.org)