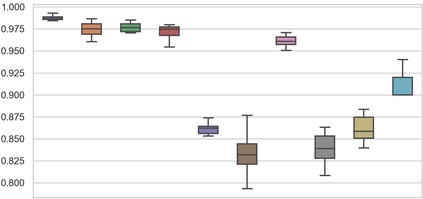
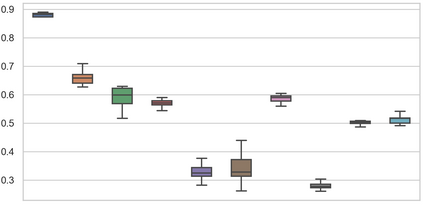
Due to high data demands of current methods, attention to zero-shot cross-lingual spoken language understanding (SLU) has grown, as such approaches greatly reduce human annotation effort. However, existing models solely rely on shared parameters, which can only perform implicit alignment across languages. We present Global--Local Contrastive Learning Framework (GL-CLeF) to address this shortcoming. Specifically, we employ contrastive learning, leveraging bilingual dictionaries to construct multilingual views of the same utterance, then encourage their representations to be more similar than negative example pairs, which achieves to explicitly aligned representations of similar sentences across languages. In addition, a key step in GL-CLeF is a proposed Local and Global component, which achieves a fine-grained cross-lingual transfer (i.e., sentence-level Local intent transfer, token-level Local slot transfer, and semantic-level Global transfer across intent and slot). Experiments on MultiATIS++ show that GL-CLeF achieves the best performance and successfully pulls representations of similar sentences across languages closer.
翻译:由于目前方法的数据要求很高,对零点点跨语言口语理解的注意已经增加,因为这种方法大大降低了人类笔记努力;然而,现有模式完全依赖共享参数,这些参数只能对各语文进行隐含的调整;我们提出了全球-地方反向学习框架(GL-CLeF),以解决这一缺陷;具体地说,我们采用对比式学习,利用双语词典来构建同一语句的多语种观点,然后鼓励其表达方式比负面的对应方式更加相似,从而实现各语文类似句子的明确一致表述;此外,GL-CLEF的一个关键步骤是拟议的地方和全球部分,实现精细的跨语言转移(即判决一级的地方意图转移、象征性的当地时间档转移、以及语义一级的全球跨意向和时间段转移),关于MultiATIS++的实验显示,GL-CLeF取得了最佳表现,并成功地将类似句的表述方式拉近各语种。