【AAAI2022】锚框排序知识蒸馏的目标检测

知识蒸馏是一种模型压缩的有效手段,但是适用于目标检测的知识蒸馏方法却很少被研究。而且,我们通过实验发现,在分类任务上主导的soft label蒸馏,并不适用于目标检测,只能带来很小的提升。因此,设计一种适用于目标检测的知识蒸馏方法很有必要。
https://www.zhuanzhi.ai/paper/b867f1778005b17a1547c8f74353158b
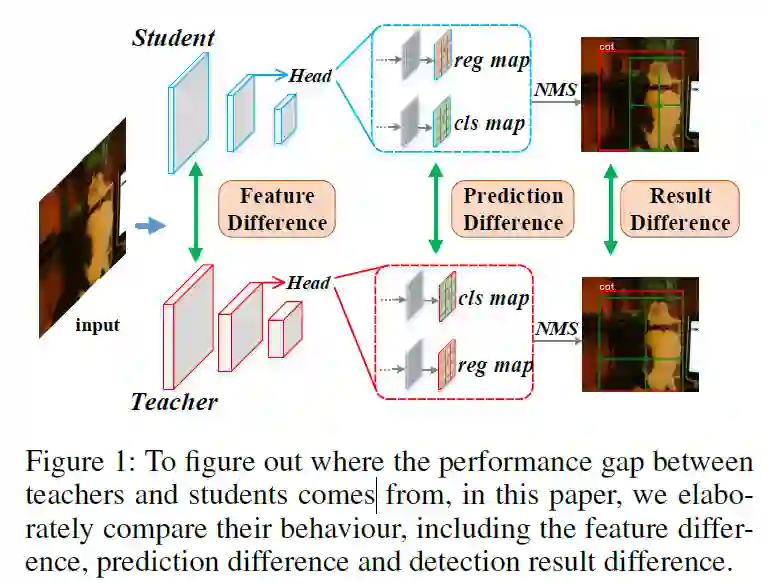
我们从特征、网络预测和NMS之后的检测结果这三方面,详细比较了教师检测器和学生检测器的差异到底在哪里。我们发现,在一些困难样本上,教师模型和学生模型的表现非常不一致,它们最终的检测结果(after NMS),往往是从不同的anchor进行预测。这个现象表明,教师网络和学生网络在anchor的排序上存在差异。教师网络有更强的表征能力,能更加准确地建模出anchor之间的语义关系,让检测结果从语义信息最强的anchor输出,并能抑制其他弱一些的anchors;而学生网络在这方面,会表现得差一些。基于这个发现,我们设计了一种新的知识蒸馏方法:Rank Mimicking (排序蒸馏)。
特征蒸馏的目的,是想让学生模型能够产生和教师一样准确的预测。但是,通过可视化,我们发现,在一些区域上,尽管学生模型的特征和教师模型的特征,有很大不同(如下图第二行黄框所示),但在这些区域,学生模型自己也可以产生准确的预测,并不需要依赖教师模型的指导(如下图第一行黄框所示)。这个现象就导致了特征蒸馏过程中,有很多无效的梯度,并不能帮助学生模型产生准确的预测。因此,我们提出了Prediction-guided feature imitation,利用预测的差异来反向引导特征蒸馏,让特征蒸馏直接拉近学生预测和教师预测之间的距离。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RMFI” 就可以获取《【AAAI2022】锚框排序知识蒸馏的目标检测》专知下载链接






