AAAI'22-无需蒸馏信号的对比学习小模型训练效能研究

极市导读
本文介绍作者团队被AAAI2022接受的工作,本文主要研究以及验证了小模型在没有蒸馏信号引导下自监督训练的可行性。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文介绍我们被AAAI'22接收的工作《On the Efficacy of Small Self-Supervised Contrastive Models without Distillation Signals》。该工作在OPPO研究院@Coler老师的指导下合作完成,同时向实习期间给予过宝贵帮助的同事们@油炸蘑菇表示感谢,尤其特别感谢前辈Zhiyuan Fang在课题初期给我们的建议以及code base的分享。
本文主要研究并验证了小模型在没有蒸馏信号引导下自监督训练的可行性,希望能够给小领域的同行带来一些有用的信息。

文章链接:https://arxiv.org/abs/2107.14762
code链接:https://github.com/WOWNICE/ssl-small
一、为什么要研究小模型对比学习自身的训练效能?
在确定研究小模型对比学习这个方向的时候,正好是CompRess[1]、SEED[2]等工作刚刚发表的时候。原本我们的计划是沿着知识蒸馏(Knowledge Distillation)希望进一步提升小模型自监督的SOTA表现,但是很快我们意识到了几个问题:
-
首先,现有工作汇报的小模型基线使用的一律都是ResNet50架构下的默认设置, 还没有对自监督小模型训练效能的研究; -
其次, 研究蒸馏方法在小模型上的应用本质上不是一个自监督学习问题。因为这个时候大模型成为小模型的监督信号,原本利用数据进行增强让网络学习到某种不变形的自监督学习在这个时候退化成为了一个简单的regression问题; -
最后,蒸馏方法往往需要部署一个大的网络,这在一些 计算资源受到限制的场景里并不是非常适用,这也再一次增强了我们想要单纯研究小模型自身对比学习效能的动机。
值得一提的是,前人的工作对小模型为什么在对比学习框架下表现糟糕给出了统一的猜想:对比学习这种instance discrimination的前置任务需要区分的类太多,对小模型来说太过困难,因此小模型在这样的前置任务上没有办法学到比较好的特征[2,3,4]。但事实上我们后面会看到,这个假设并没有说服力。解释小模型为什么学不到好的表征空间依旧是一个需要探索的方向。
二、大/小模型在各个指标上的表现差异?
首先我们设置一系列用于评价模型表征空间的评测指标。前置任务相关的评测指标包括alignment、uniformity,以及instance discrimination accuracy. 下游任务相关的评测指标包括intra-class alignment、linear evaluation protocol,以及best-NN。其中intra-class alignment计算的是类内平均距离,使用了标签信息进行评测,它和之前的工作[5]中的tolerance在“单位球面表征空间”的约束下是等价的。而best-NN是我们提出的为了弥补原有的k-NN评测方法缺陷的新的评测指标:不同模型的表征空间可能在不同的超参k情况下能够达到表现的最优值,因此我们遍历 寻找最优的k-NN准确度作为模型的best-NN表现。其余的指标alignment/uniformity/linear evaluation protocol相信大家已经比较熟悉,这里就不再赘述。
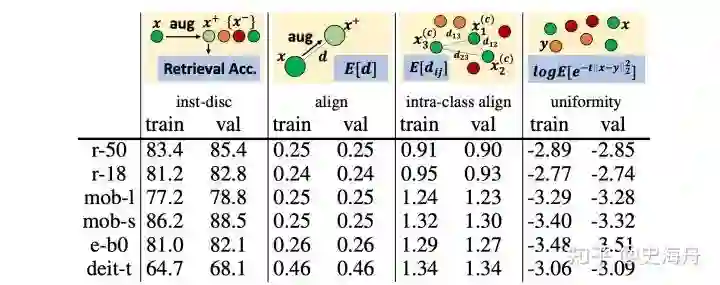
在同样的自监督训练设置下,我们比较了几个小模型和大模型的表征空间异同点(如表1所示);我们可以得到两个重要的观察:
-
大/小模型在前置任务上的表现非常接近(除去deit-t)。 这部分说明了前置任务完成度和下游任务表现没有特别明显的正相关。甚至观察大小模型之间的alignment/unifromity,我们看到一些小模型的uniformity优化地比大模型更好。 -
小模型在前置任务上没有发生过拟合。 这部分说明了前置任务的泛化误差(generalization error)不是导致其下游任务泛化性差的原因。

进一步地,我们将模型的表征空间通过t-sne进行可视化,得到图1。观察对比图1的左列,我们发现小模型的表征空间没有形成非常好的簇,绝大多数类别的样本比较松散地聚合在一起,而大模型却形成了一些明显的簇。导致以上分布的原因可以是under clustering(即正样本没有很好地被拉近在一起),同时也可以是over clustering(正样本被过度地拉近,但是同类别的样本没有相应地拉近)。观察图1的右列,我们同时将一个样本和它的两个augmented views' representations连接起来成为一个三角形,可以发现大/小模型的表征空间中的三角形均非常小(需要zoom in 100x才能看清楚),因此也就得到了我们的第三个观察:
-
小模型表征质量较差的主要原因是over clustering。
三、一些简单解决over clustering的假设
我们可以采用一些看起来fancy的方法来解决over clustering,但我们更希望自己的工作能够给未来的研究做一个铺垫,因此只验证一些看起来合理并且简单的手段,包括:温度( )、负样本数量、数据增广方案、权重初始化质量,以及projector架构。碍于篇幅限制,我们在这里仅仅给出猜想和一些重要的结论,不会涉及其中的实验数据和细节,感兴趣的小伙伴可以看我们的原文~
-
温度( ) 对表征空间uniformity/alignment产生的平衡作用。我们原本期望增加温度从而牺牲一些uniformity去换更好的alignment,进而缓解over clustering的现状,但实验结果告诉我们,对于小模型,稍微小一些的温度设置会有更好的效果( )。 -
负样本数量直接影响模型在训练期间遇到false negative samples的频率,我们猜想小模型可能对false negative samples更加敏感,但结果是该因素并不特别影响模型的表现。 -
数据增广控制了前置任务的难度,同时更强的数据增广能够抑制pre-training task中存在的shortcuts。通过增加数据增广的强度从而显著提升了小模型的表现。 -
权重初始化的质量导致不同的优化路径,很多时候直接影响最终模型的表现。这里我们研究了使用SEED进行过几个epoch蒸馏的模型作为小模型自监督学习的初始化权重,并且发现仅仅采用2个epoch蒸馏过后的权重(该权重的线性可分性比小模型本身的基线低),都可以给模型带来非常大的提升。 -
projecto架构是另一个控制前置任务学习时backbone network更新的组件,有很多的工作[2,6,7]说明了它们可能对模型产生的影响。这里通过验证,我们发现更宽的MLP能够给模型带来提升。
四、广泛提升自监督小模型的基线表现
接下来我们将以上经过验证的simple tricks合并,在5个架构的小模型上进行基准测试,来判断这些trick的有效性。我们得到了表2(linear evaluation protocol)以及表3(transfer learning results)。


在MobileNetV3-large网络结构上,我们进一步对这些tricks进行了ablation study,得到了以下结果:

五、总结
综合上述的结果,我们验证了即使在训练时不需要大模型提供的蒸馏信号引导,小模型的自监督表现依然能够达到一个不错的水平。我们希望这项工作能够为未来小模型自监督领域的工作带来一些启发,欢迎志同道合的朋友们在评论区分享自己的观点~
参考文献
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



