

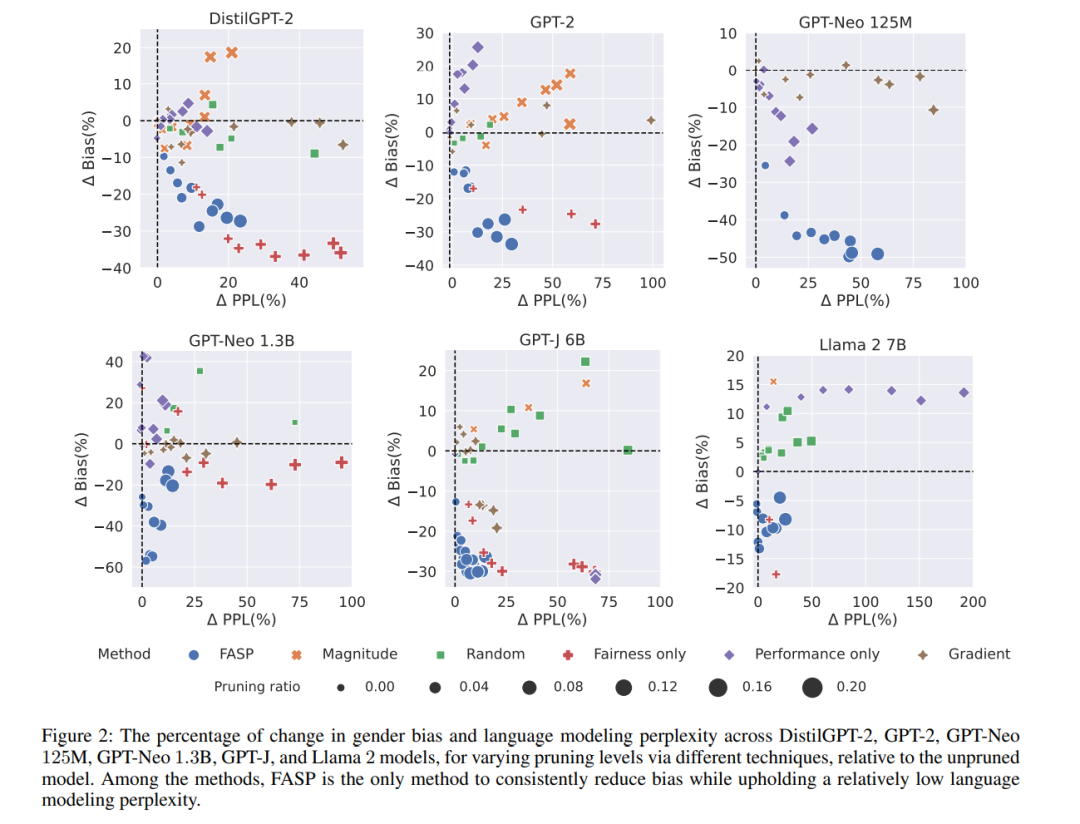
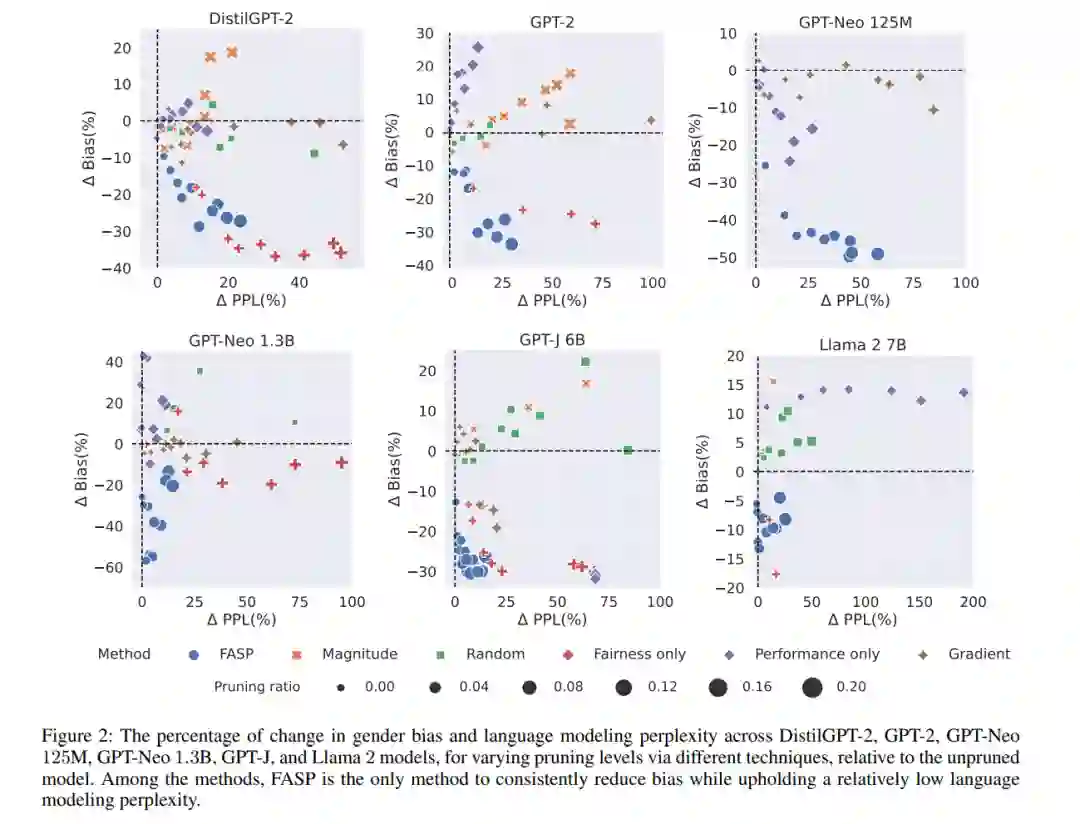
大型语言模型(LLMs)的不断增大引入了在它们的训练和推断中面临的挑战。移除模型组件被认为是解决大型模型尺寸问题的一种方法,然而,现有的剪枝方法仅关注性能,而没有考虑到对LLMs的负责任使用的一个重要方面:模型的公平性。 对于多样化群体,如女性、黑人、LGBTQ+、犹太社区等,重要的是要关注LLMs的公平性,因为它们正在被部署并面向广泛的受众。在这项工作中,首先,我们研究了在基于预训练Transformer的语言模型中,注意力头(attention heads)如何影响公平性和性能。然后,我们提出了一种新的方法,用于剪枝那些对公平性产生负面影响但对性能至关重要的注意力头,即语言建模能力的关键头部。我们的方法在时间和资源方面具有实用性,因为它不需要对最终剪枝后的更公平模型进行微调。 我们的研究结果表明,与有偏见的模型相比,DistilGPT-2、GPT2、两种不同尺寸的GPT-Neo、GPT-J和Llama 2模型的性别偏见分别减少了19%、19.5%、39.5%、34.7%、23%和8%,而性能只略有下降。警告:本研究使用了具有冒犯性质的语言。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日