

图:2023 年 5 月 15 日,在波兰 Nowa Deba 举行的波兰领导的 "Anakonda 23 "演习中,第 1 步兵师第 2 装甲旅战斗队第 70 装甲团第 2 营 B 连的士兵在联合武器实弹演习中向一辆 M1A2 艾布拉姆斯坦克开火,为第 4 步兵师提供支援。(照片拍摄者:美国陆军一级军士长 Theresa Gualdarama)。
1858 年,保罗-墨菲(Paul Morphy,被认为是他那一代最伟大的棋手)与两位对手--德国贵族卡尔二世(Karl II,不伦瑞克公爵)和法国贵族伊苏阿德-沃韦纳尔格伯爵(Comte Isouard de Vauvenargues)--在歌剧演出期间进行的国际象棋比赛被称为 "歌剧对局",可以说是历史上最著名的比赛。它是攻击棋的典型范例,体现了发展、时间、牺牲和战术组合的重要性。虽然多域作战(MDO)显然比国际象棋更复杂,但国际象棋的随机性可以为考虑和分析这一概念提供一个框架。人工智能(AI)与国际象棋的结合揭示了新的战略,并将国际象棋推向了新的高度。人工智能对战略游戏的影响揭示了将其融入 MDO 的可能性,特别是对聚合概念的影响。MDO 要求指挥官通过在五个领域和三个维度上运用联合能力和陆军能力,将各种武器结合起来--这是最严峻的挑战。
类比推理框架:国际象棋与多域作战
十五世纪初,意大利和西班牙出现了现代国际象棋规则。棋局分为三个不同的阶段:开局、中局和尾盘。在开局阶段,棋手要发展自己的棋子,确保国王安全,并试图控制中心。在中局中,棋手进行攻击和防守,通过战术组合获得优势。尾盘则是棋手夺取优势位置并吃掉国王。在既定的冲突期间,MDO(尤其是融合概念)可以在这些阶段中进行分析。执行 MDO 的挑战不在于概念,而在于实践。了解问题集并不难,但要将其充分付诸实施则是一项艰巨的任务。野战手册(FM)3-0《作战》将融合定义为 "针对任何领域的决定性节点组合,协同运用多领域和多层次的能力,对某一系统、编队、决策者或特定地理区域产生影响所产生的结果"。融合 "棋盘 "横跨五个领域--空间、网络空间、海洋、空中和陆地,以及三个维度--物理、信息和人。如表 1 所示,融合可以像国际象棋比赛一样分阶段进行。
指挥官面临的挑战是如何将联合部队和陆军在多个领域和层面的能力结合起来,以达到预期效果。指挥官必须在五个领域和三个维度对能力进行定位,接收可操作的实时信息,确定最佳的同步和协调组合,并在时间和空间上对高智能对手产生大规模影响。从概念上讲,这些领域和维度之间有 15 个交叉点或球体(见表 2)。
每个领域都有一种能力。组合数的数学公式如图 1 所示。

图1:能力组合公式
从概念上讲,如果一名指挥官有 15 种可用能力(n = 15),并希望集结其中两种能力(r = 2),那么可以考虑 105 种组合。如果一名指挥官在这 15 个领域(n = 15)中每个领域都有一种能力,并希望集结三种能力(r = 3),那么可以考虑 455 种组合。如果指挥官希望集结三种能力,并且这些能力的应用顺序也很重要,那么我们考虑的就不再是组合,而是排列组合;在这种情况下,指挥官可以考虑 2,730 种排列组合。这只是考虑到每个球体存在一种能力。问题随之而来: 指挥官是否有可用的工具来处理所有这些潜在组合,并在时间有限的环境中做出最佳选择?指挥官是否有能力分析接近 2730 种排列组合并选择最佳行动方案?
表1:融合阶段
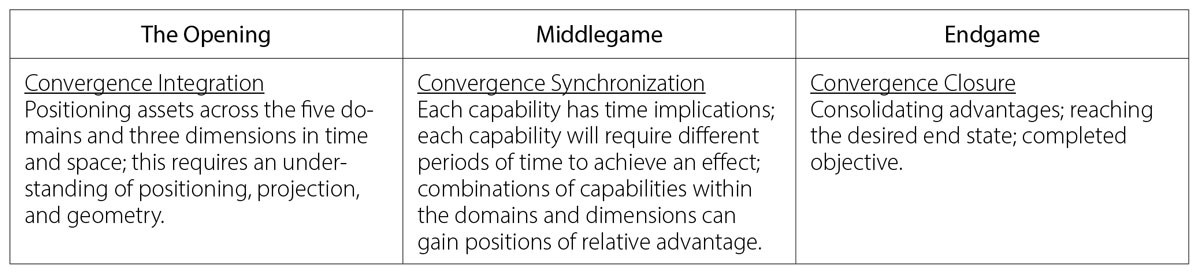
表2:组合球

FM 3-0 指出,编队在行动中实现融的程度取决于领导者能否很好地做到以下几点:
通过提供混合、冗余和重叠覆盖的有效监视,了解敌方系统及其能力、需求、决策过程和弱点。
- 确定所需的整体效果或机会,以及促成这一机会的单个效果和目标。
- 在最有效的层级整合陆军和联合能力。
- 考虑所有领域和冗余攻击方法,以提高成功概率。
- 同步使用每种能力和梯队,对敌方系统产生同步、连续和持久的影响。
- 评估单个效果以及实现预期总体效果的可能性。如果未达到预期效果或出现其他机会,指挥官应准备重新攻击或调整行动方案。
- 承担风险并迅速利用会聚提供的机会。
对指挥官而言,融合不应是发现性学习。指挥官根据自身经验和作战框架,对如何开展行动有自己的概念。就像下棋一样,他们会有自己偏爱、研究和实施的攻击和防御策略。人工智能的出现可以通过提供梯队战略和近乎实时的分析来协助计划和执行阶段,从而提高成功的概率。在计划阶段,指挥官可以利用人工智能探索针对特定敌方参数的能力组合,发现新的战术和战略,或重申自己的偏好。在执行阶段,人工智能可协助处理/过滤信息,并提供衔接建议。
人工智能:自学习算法
谷歌 DeepMind 团队创建的人工智能程序 AlphaGo 在围棋比赛中击败了当时的世界冠军(人类)李世石,成为头条新闻。围棋有 10170 步,是国际象棋的三百倍。2018 年,AlphaZero 以一百比零击败了 AlphaGo。其意义在于,AlphaZero 只用了三天时间就从零开始训练自己下围棋,并完胜 AlphaGo。AlphaZero 接收到的唯一输入是游戏的基本规则。如果有了参数明确的基本规则,人工智能算法就可以在没有人类输入的情况下制定战术和策略。理论上,我们可以开发一个人工智能程序,让它来下一盘涉及 15 个领域能力的棋。人工智能程序可以发现最佳组合或排列组合,以最有效的方式集结能力。如果假设精通国际象棋需要一万小时,那么指挥官是否有成为 MDO 专家所需的反复练习时间呢?在 MDO 中应用人工智能可以在计划和准备阶段提供这些重复练习,并在行动期间提供建议。
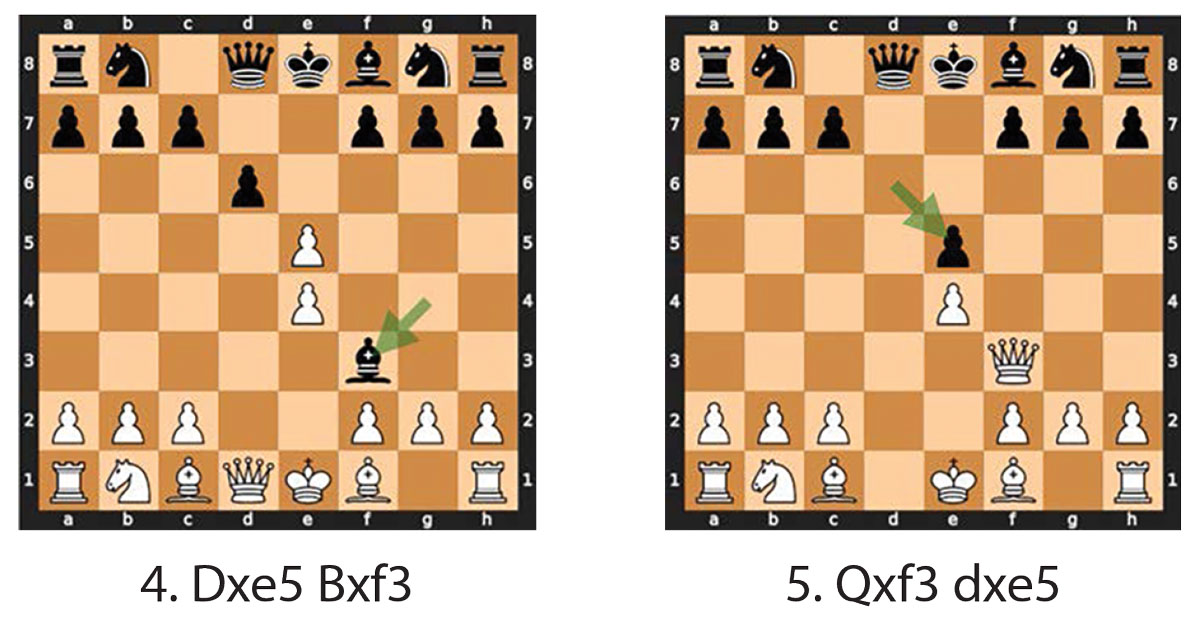
图2. 开局
开局:融合集成
根据 FM 3-0,"整合是对军事力量及其行动的安排,以形成一支整体作战的力量"。这种对能力部署、时机选择和条件设定的理解对 MDO 至关重要。在 "歌剧院对局 "中,执白棋的墨菲开局便将兵走到 e4。随后的开局顺序如下 (1) e4 e5,(2) Nf3 d6(对手走的是菲利多防御),(3) d4 Bg4,(4) dxe5 Bxf3,(5) Qxf3 dxe5,(6) Bc4 Nf6,(7) Qb3 Qe7(见图 2)。
下面是我们可以从开局中总结出的经验。首先,墨菲立即用第5步棋Qxf3进行威胁。5、Qxf3,提出了下一步Bc4的将死局面。甚至在第5步棋之前 甚至在第5步棋之前,墨菲就将棋子置于有利位置,威胁到无人防守的兵。"危险等级"的概念在国际象棋中是一个常见的主题,因为棋手会对对手的每一个弱点施加攻击压力,因为他们知道即使是一个兵的优势也会使他们在接下来的比赛中处于有利地位。收敛的关键在于了解自己通过能力布局向敌人施加即时压力的能力。其次,墨菲在开局中第二次移动皇后的非正统棋步(第7步,Qb3)立即带来了另一种将死局面(见图3)。虽然在现代对局中很可能不会走这步棋,但他(根据对手的棋力)决定立即施压是最好的办法。这步棋迫使对手回应 Qe7 挡住了黑棋的 f8 象,使得这步棋无效。将这一点应用到MDO中,开局中是否有一些能力布局能立即使敌方应用某种能力作战无效,或者提供足够的摩擦力,使敌方必须花费大量时间、资源和精力才能部署这种能力?

图3. 开局(续)
MDO 的融合概念要求指挥官将部队的各个部分整合起来,以实现统一目标和统一行动。根据 FM 3-0,指挥员拥有多种智力工具来促进这种融合:目标定位流程、任务式分析、按梯队嵌套任务和目的,以及交战区域开发。
人工智能建议 1。创建一个由人工智能支持的智能工具,使指挥官能够探索、学习和了解能力运用。然后,指挥官可以根据自己的个性、经验和人工智能增强的兵棋推演来决定他们喜欢设置的条件。利用人工智能来研究能力部署和初始条件设置,可以大大提高指挥官在行动中的初始动作,从而增加成功的机会。国际象棋职业棋手都有自己喜欢的开局,并有应对或打击对手反应的策略。指挥官也可以在 MDO 结构中拥有自己喜欢的能力,并成为应用这些效果的专家。根据从 "歌剧游戏 "开局中吸取的经验教训,人工智能的初步研究可以集中在以下问题上:
- 哪些能力可以通过球形对敌方资产造成直接压力?哪些能力可以针对敌方结构中的最初弱点?
- 按领域划分,哪些能力可以通过初始定位阻挡敌方的关键能力?某一领域的能力是否能自动抵消或减轻敌方在另一领域的能力?
- 哪些初始能力部署对敌方威胁最大?是否有自动威胁敌方获胜能力(将死)的能力?
中局:融合同步
一旦领导者整合了正确的能力,就必须使其使用和效果同步。FM 3-0 将同步定义为 "在时间、空间和目的上安排军事行动,以便在决定性地点和时间产生最大的相对战斗力"。使指挥官能够确定何时开始使用某种能力以及如何在执行过程中适应作战环境变化的因素包括以下几点:
- 随着时间的推移,单个效果如何相互补充。
- 每种能力或编队从开始使用到产生各自效果所需的时间。
- 每种效果是持久的、同时的还是连续的。
此外,FM3-0 指出,当融合的效果累积起来并形成一个扩大机会的循环时,融合就最为有效。采用多种冗余攻击方法可避免依赖单一方法,从而提高成功概率。成功会使敌军做出反应并启动更多能力,从而在一个或多个领域创造新的机会。
中局是指挥官通过在决定性节点上取得一系列胜利来获得优势地位的地方。"歌剧游戏 "中有许多适用的概念可应用于会聚中局。对局继续进行:(8)Nc3 c6,(9)Bg5 b5,(10)Nxb5!cxb5,(11)Bxb5+ Nbd7,以及(12)0-0-0 Rd8(见图 4 和图 5)。
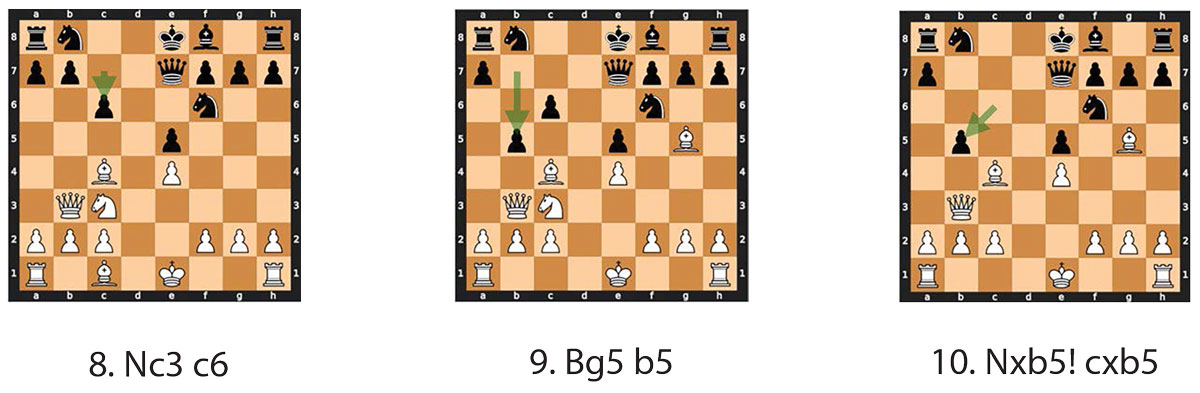
图4. 中局
在第 9 步棋中用 Bg5 保持灵活性的能力至关重要。事实证明第9步棋至关重要。这步棋开发了白棋的所有能力,显示了战术上的耐心,同时保持了在两边攻城的能力。这步棋还将黑棋的黑夜钉在了f6,使对手f8的象和f6的马都失去了作用。此外,由于黑棋处于弱势,它迫使敌方提前发起攻击(从黑棋走到 b5 可以看出)。马的销子和白棋车的开档将导致黑棋的失败。

图5. 中局(续)
人工智能建议 2。创建一种人工智能算法,为指挥官提供能力效果建议。无论是从传感器(理想状态,尽管存在数据被黑客攻击的固有风险)还是人工输入的数据,人工智能都能帮助过滤信息,并就如何为敌方提供多重困境提出建议。如果指挥官在融合能力时必须考虑 2730 种排列组合,那么人工智能就能提供 "最佳行动 "建议。根据能力定位和敌情评估,人工智能可以帮助指挥官在行动中做出决策;从本质上讲,人工智能程序成为了协助指挥官做出决策的额外参谋人员。它可以协助瞄准过程,但更重要的是,它可以为执行杀伤链提供实时建议。
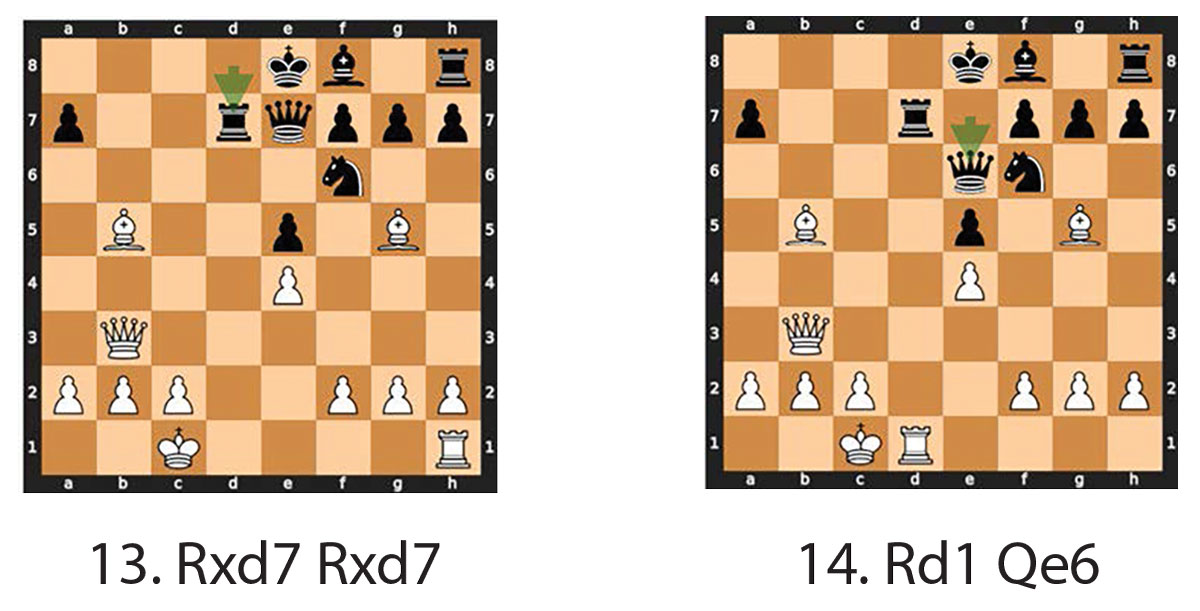
图6. 中局(续)
莫菲中局最强大的概念是牺牲的概念。在对手走兵到b5(第9步棋)之后,莫非没有将象退到d3,而是用Nxb5吃掉了这只兵(第10步棋)!(第10步),牺牲了他的马,但却给他带来了优势局面。莫菲并没有撤退,而是决定牺牲来保持节奏和进攻压力。对局至此,莫菲虽然在材料上处于劣势,但却依靠棋子的实用性获胜。墨菲有四颗棋子(2xbishops、1xrook和1xqueen)可以用来攻击,而黑棋则围着王转。黑棋车到d8后有很多选择。国际象棋的一个常见概念是逼迫棋步,使对手做出不利的反应。主要的逼迫棋步包括格杀和吃掉。
中局继续进行(13)Rxd7 Rxd7 和(14)Rd1 Qe6(见图6)。值得注意的是,在第 第13步,黑棋以 Rxd7 取象,而不是以 g5 取马 f6。在黑棋吃掉Rxd7之后,威力较小的白棋象使黑车失去了作用,因为它被钉在原地以保护国王。
在 MDO 中,与牺牲最接近的概念是欺骗。联合出版物 3-13.4《军事欺骗》将军事欺骗定义为 "故意误导对手军事、准军事或暴力极端组织决策者的行动,从而使对手采取有助于完成友军任务的具体行动(或不行动)"。FM 3-0 指出,欺骗 "有助于制造多重困境"、不确定性和迟缓敌方决策。FM 3-0 中没有 "牺牲 "一词。在国际象棋中,"牺牲 "是指放弃一个棋子,以获得其他形式的战术或位置补偿。牺牲也可以是故意用价值较高的棋子交换对方价值较低的棋子。莫菲在第10步棋(Nxb5!) 军事欺骗和牺牲的概念存在细微差别。联合出版物 3-13.4 明确指出,欺骗的意义在于误导决策者。这主要是通过信息优势来实现的,即给敌方决策者制造多重困境,或将其注意力集中在一个攻击计划上,同时执行另一个计划。另一方面,牺牲是为了优势而故意摧毁一种能力。双方都知道能力的重要性。战争是人类的事业,为了阵地优势而牺牲生命的想法是难以想象的。此外,为了阵地优势而故意摧毁装备、平台或其他资源的想法也是不可取的。然而,随着无人系统的出现,出其不意的难度增加,必须在 MDO 中探讨牺牲的想法。
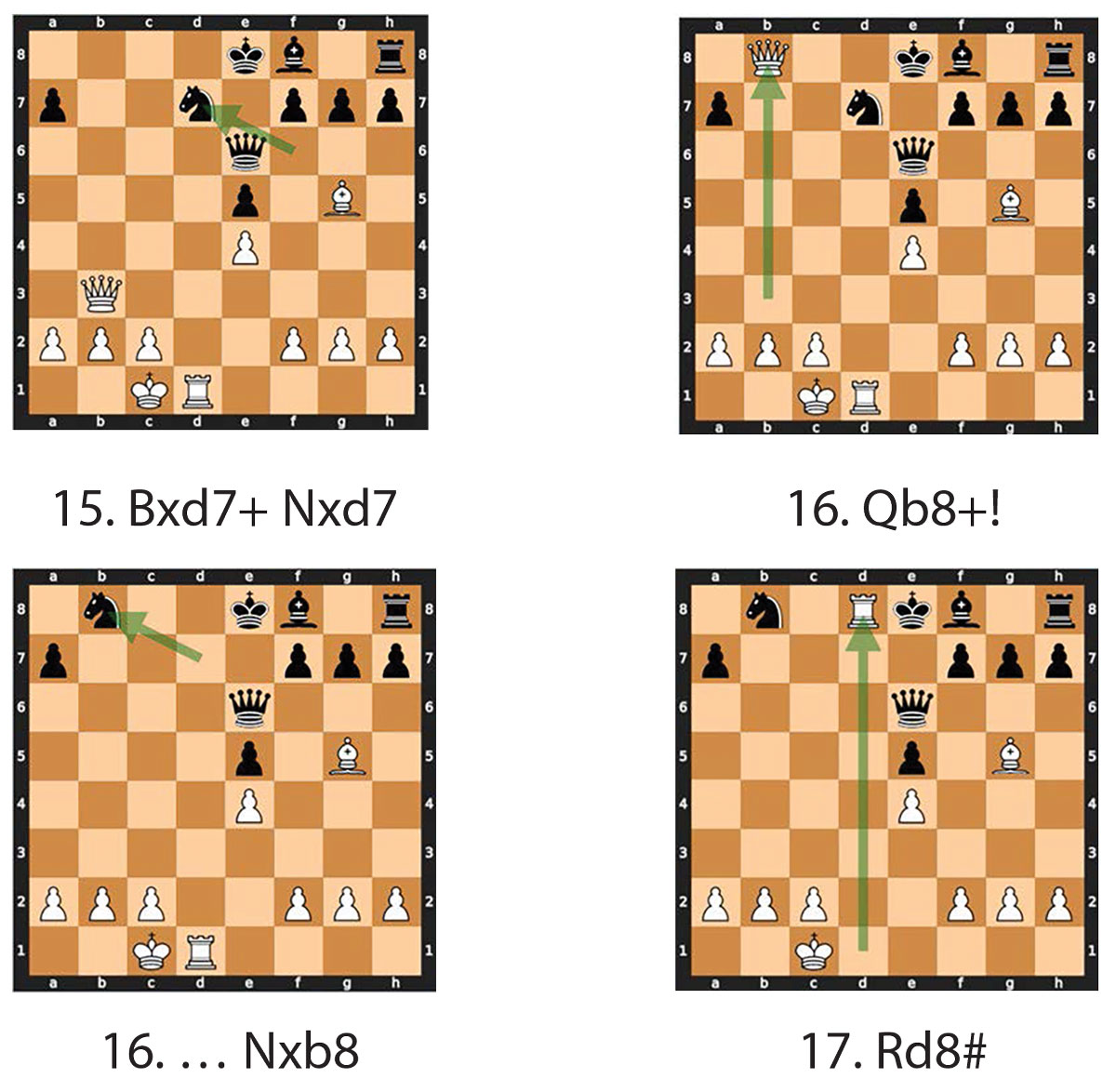
图7. 终局
人工智能建议 3。创建一个人工智能智能工具,探索融合行动中的牺牲概念。在战场上,皇后棋子的能力相当于什么?主教还是骑士?必须在 MDO 中探索牺牲的概念。随着传感器的增加,出其不意和欺骗将变得越来越困难。为了给敌方决策者带来多重困境并造成不确定性,必须引入牺牲的概念。是否有基于牺牲概念的能力组合或排列组合,以及具体的后续攻击路线,可以产生优势地位?
终局:融合结束
为了便于讨论,本文将胜利定义为目标的终结。在黑棋将后移至 e6 之后,国际象棋史上最具代表性的组合之一随之出现:(15) Bxd7+ Nxd7, (16) Qb8+!Nxb8,以及 (17) Rd8# (见图 7)。墨菲的 Qb8 这步棋牺牲了皇后,迫使对手以 Nxb8 吃掉,并以 Rd8 形成将死。
"歌剧对局 "之所以经受住了时间的考验,就是因为这个令人惊叹的布局。现在,每个国际象棋俱乐部都会教授墨菲对国际象棋基本原理的应用。在未来战争中,不确定性和不断变化的条件将普遍存在。然而,在 MDO 中使用人工智能可以帮助分析、过滤数据和提供建议。MDO 对指挥官跨领域、跨维度应用能力提出了巨大挑战。整合人工智能可简化行动,协助执行融合作战。
参考来源:U.S. Army,Lt. Col. Michael Kim

