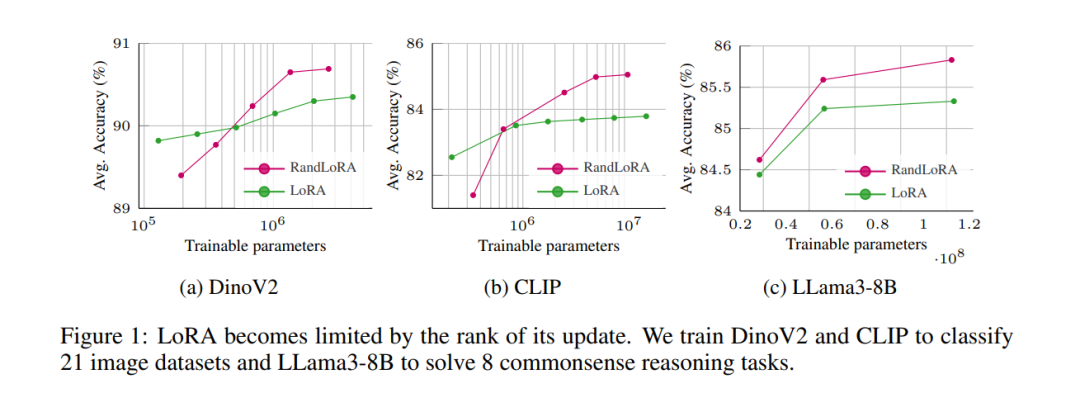
![]() 低秩适应(LoRA)及其变体在减少大型Transformer网络的可训练参数数量和内存需求方面取得了显著成果,同时保持了微调性能。然而,权重更新的低秩性质本质上限制了微调模型的表示能力,可能会影响复杂任务的表现。这引出了一个关键问题:当观察到LoRA与标准微调之间的性能差距时,这个差距是由于可训练参数数量减少,还是由于秩缺陷?本文旨在通过引入RandLoRA这一参数高效的方法来回答这个问题,该方法使用低秩、非可训练的随机矩阵的线性组合进行全秩更新。我们的方案通过将优化限制在作用于固定随机矩阵的对角缩放矩阵上,从而限制了可训练参数的数量。这使得我们能够在保持训练过程中的参数和内存效率的同时,有效克服低秩限制。通过在视觉、语言和视觉-语言基准上进行广泛的实验,我们系统地评估了LoRA和现有随机基方法的局限性。我们的研究发现,单独应用于视觉和语言任务时,全秩更新均表现出优势;尤其是在视觉-语言任务中,RandLoRA显著缩小——甚至有时消除——标准微调与LoRA之间的性能差距,证明了其有效性。
低秩适应(LoRA)及其变体在减少大型Transformer网络的可训练参数数量和内存需求方面取得了显著成果,同时保持了微调性能。然而,权重更新的低秩性质本质上限制了微调模型的表示能力,可能会影响复杂任务的表现。这引出了一个关键问题:当观察到LoRA与标准微调之间的性能差距时,这个差距是由于可训练参数数量减少,还是由于秩缺陷?本文旨在通过引入RandLoRA这一参数高效的方法来回答这个问题,该方法使用低秩、非可训练的随机矩阵的线性组合进行全秩更新。我们的方案通过将优化限制在作用于固定随机矩阵的对角缩放矩阵上,从而限制了可训练参数的数量。这使得我们能够在保持训练过程中的参数和内存效率的同时,有效克服低秩限制。通过在视觉、语言和视觉-语言基准上进行广泛的实验,我们系统地评估了LoRA和现有随机基方法的局限性。我们的研究发现,单独应用于视觉和语言任务时,全秩更新均表现出优势;尤其是在视觉-语言任务中,RandLoRA显著缩小——甚至有时消除——标准微调与LoRA之间的性能差距,证明了其有效性。![]()