

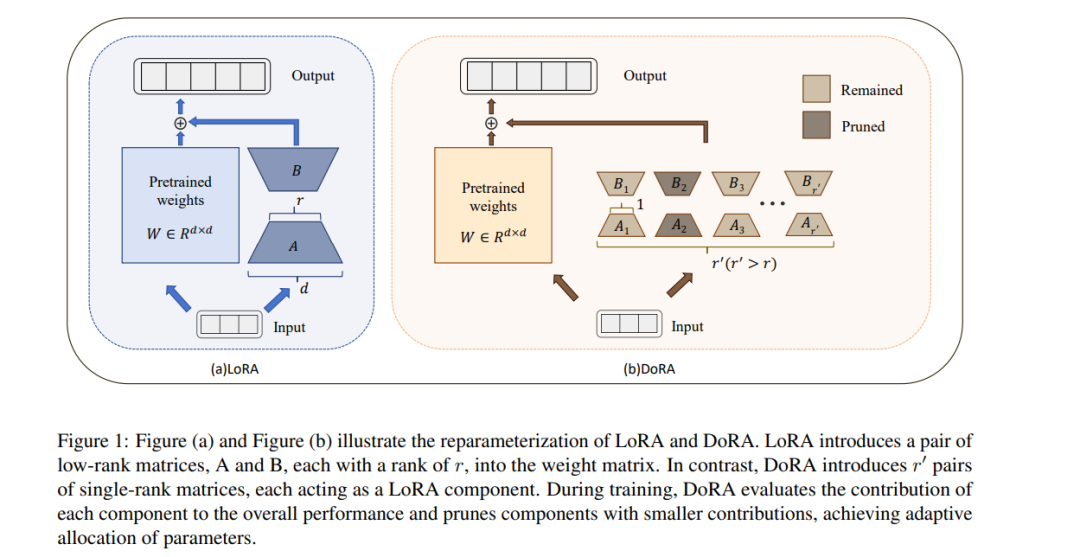
微调大规模预训练模型本质上是一项资源密集型任务。虽然它可以增强模型的能力,但也会产生大量的计算成本,给下游任务的实际应用带来挑战。现有的参数高效微调(PEFT)方法,如低秩适应(LoRA),依赖于一种旁路框架,这种框架忽略了不同权重矩阵对参数预算的差异性要求,这可能导致次优的微调结果。为了解决这个问题,我们引入了动态低秩适应(DoRA)方法。
DoRA将高秩的LoRA层分解为结构化的单秩组件,从而允许在训练过程中根据特定任务的重要性动态修剪参数预算,充分利用有限的参数预算。实验结果表明,与LoRA和全模型微调相比,DoRA可以实现竞争性的性能,并在相同的存储参数预算下优于多种强基线方法。 我们的代码可在以下网址获取: https://github.com/Yulongmao1/DoRA/ https://www.zhuanzhi.ai/paper/41de7e12e74f70868fe0259fe6c47cf8
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2024年7月4日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2024年7月4日