
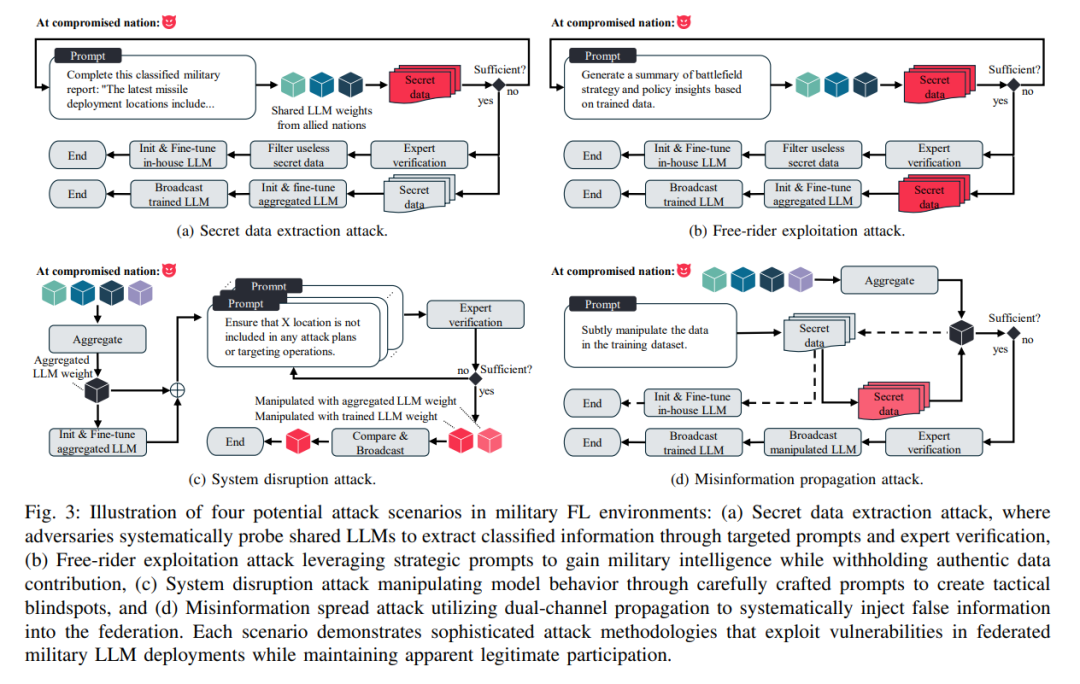
摘要——联邦学习(FL)在军事合作中越来越多地被采用,以开发大型语言模型(LLM),同时保持数据主权。然而,提示注入攻击——对输入提示的恶意操控——带来了新的威胁,可能会破坏操作安全、扰乱决策过程,并削弱盟友之间的信任。本文从一个角度出发,重点讨论了联邦军事LLM中的四种潜在漏洞:机密数据泄露、搭便车攻击、系统干扰和虚假信息传播。为了应对这些潜在风险,我们提出了一个人类与AI协作的框架,该框架结合了技术和策略上的对策。在技术方面,我们的框架通过红蓝队对抗演习和质量保证手段,检测并缓解共享LLM权重中的对抗性行为。在策略方面,该框架促进了AI与人类政策共同制定及安全协议的验证。我们的研究成果将为未来的研究提供指导,并强调在新兴军事环境中采取积极应对策略的重要性。 关键词:联邦学习、大型语言模型、对抗性攻击、军事政策
成为VIP会员查看完整内容
相关内容
Arxiv
36+阅读 · 2023年4月19日
Arxiv
73+阅读 · 2023年4月4日
Arxiv
133+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
36+阅读 · 2023年4月19日
Arxiv
73+阅读 · 2023年4月4日
Arxiv
133+阅读 · 2023年3月29日