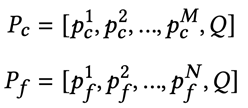本文简要介绍ACM MM 2024录用论文“Focus, Distinguish, and Prompt: Unleashing CLIP for Efficient and Flexible Scene Text Retrieval”。该论文提出了一个名为“Focus, Distinguish, and Prompt (FDP)”的方法,通过充分挖掘CLIP的内在潜能来实现无需感知的(OCR-free)场景文字检索。具体而言,针对CLIP直接用于场景文字检索时存在的文字感知尺度有限和视觉语义概念纠缠两方面问题,提出首先通过转移注意力和探寻隐含知识模块使模型聚焦于场景文字,然后将查询文本分类成实词和虚词分别进行处理,并设计扰动查询辅助模块抵抗形近单词的干扰,最后通过语义感知的提示方法完成图像的排序和检索。由于免去了复杂的场景文字检测和识别过程,FDP在保证检索精度的条件下能够显著提高检索速度,并在词组级别检索和属性感知检索设置下展现出突出的优势。
一、研究背景****
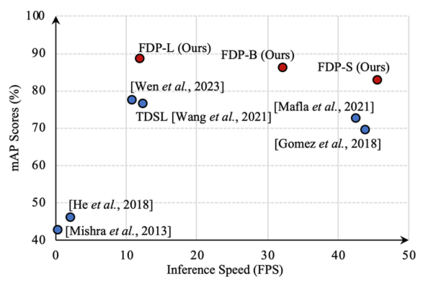
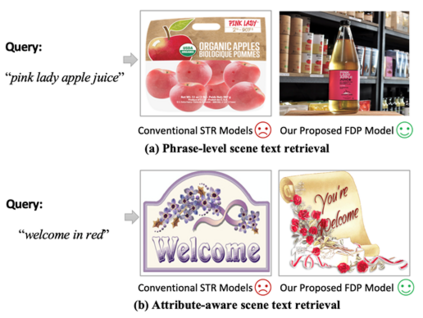
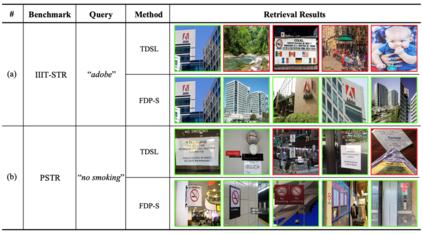
场景文字检索旨在从图片库中搜索包含查询文本的所有图像。目前大多数方法借助OCR框架,存在两方面缺陷:1)难以达到检索精度与速度的良好均衡。如图1所示,以TDSL[1]和Wen et al.[2]为代表的检索方法需要引入显式的文字检测或识别过程,在检索速度上呈现不足。相对而言,Gomez et al.[3]利用一个简洁的Single-shot CNN框架能够达到较快的检索速度,但其是以精度的下降为代价的。2)无法处理不同形式的查询文本。如图2所示,现实生活中人们想要检索的查询文本往往是多样化的。但是,现有方法采用局部检索机制(将单词视为查询单元),不能灵活地泛化到词组级别或属性感知等更广泛的检索场景。
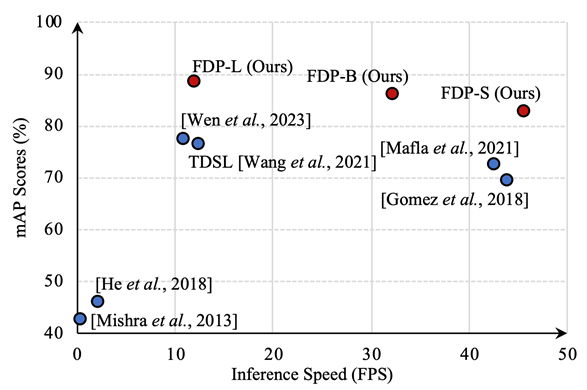
图1 FDP方法与先前方法在检索精度和速度上的对比

图2 词组级别(Phrase-level)和属性感知(Attribute-aware)设置下的场景文字检索 针对上述问题,该论文探究是否能够利用CLIP的内在潜能实现高效灵活的场景文字检索。通过实验发现,直接使用冻结的CLIP模型已经能够达到一定的检索精度(52.93% mAP on IIIT-STR),而且得益于CLIP简洁的网络架构,其检索速度也非常快(76.32 FPS)。但是,原生CLIP仍然面临文字感知尺度有限和视觉语义概念纠缠两方面问题,在处理小文字、虚词查询以及形近单词上效果不佳。 二、方法原理简述****
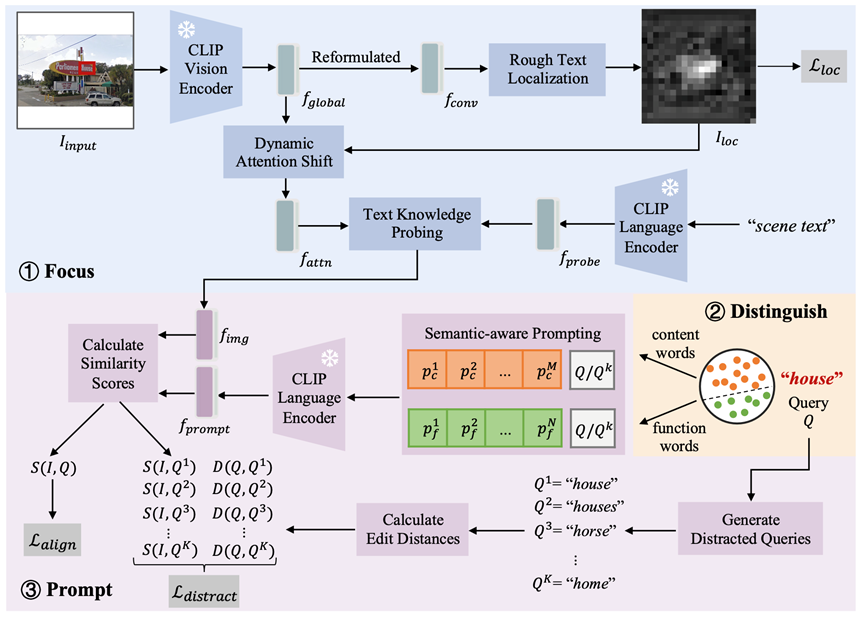
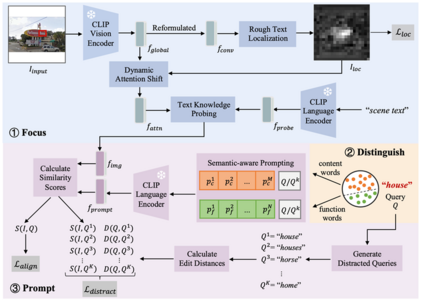
图3 FDP整体结构图
本文介绍的FDP模型整体结构如图3所示,其遵循Focus、Distinguish、Prompt的三步流程,具体细节如下:
1. Focus:聚焦文字区域
因为原生CLIP能够支持的输入图像分辨率非常有限(如224*224),而场景文字常常在图像中仅占据很小的一部分,因此许多文字可能会被CLIP忽略或错误识别。为此,FDP首先采用位置编码插值的方法扩大输入图像分辨率,然后提出Dynamic Attention Shift和Text Knowledge Probing 模块分别从视觉空间和语义空间增强场景文字信息。1)Dynamic Attention Shift:给定输入图像,通过CLIP视觉编码器和一个重新参数化模块获得二维图像特征。基于,利用文字检测标注训练一个轻量化的网络预测文字定位概率图,并将作为掩码动态调整多头注意力层里的注意力分布,得到注意力特征,进而将模型关注区域转移到场景文字。2)Text Knowledge Probing:利用文本“Scene Text”的语言特征作为探针,将其与进行基于交叉注意力机制的特征交互来激活文字有关知识,获得更适用于文字检索任务的图像特征。
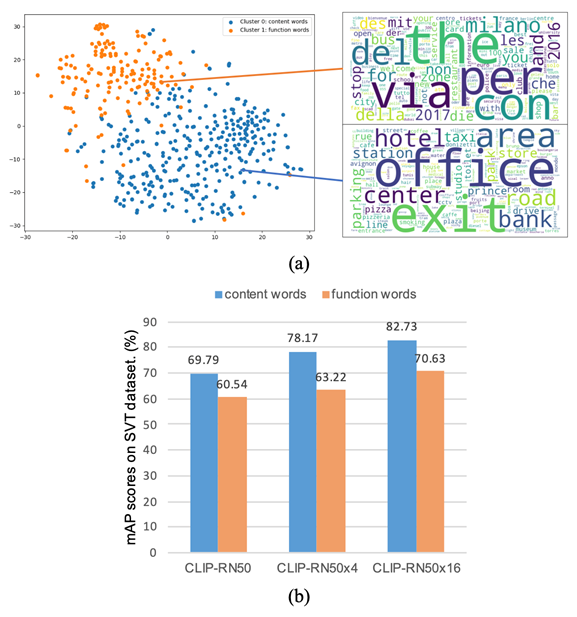
2. Distinguish:区分查询文本
3. Prompt:提示优化检索
受CoOp[4]等可学习提示方法的启发,FDP提出语义感知的提示学习方法实现高效的场景文字检索。具体而言,针对实词和虚词,分别引入两组可学习上下文向量,与查询文本拼接在一起作为提示输入:
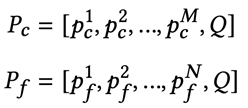
通过计算每个图像特征与提示特征的余弦相似度,对待检索图像进行排序,进而完成检索。此外,在训练时引入扰动查询辅助模块,其根据查询文本生成编辑距离较小的干扰查询文本作为难负例,帮助模型提升对于形近单词(如“Advice”和“Advise”)的鉴别能力。 三、主要实验结果****
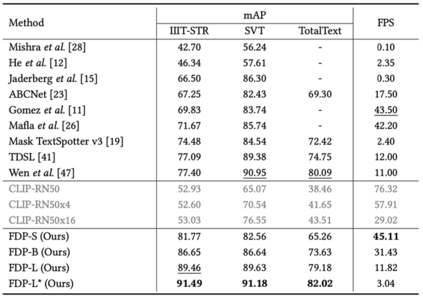
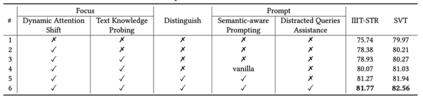
通过与已有方法的性能对比实验(表1)和消融实验(表2),可验证FDP方法的有效性和优越性。在IIIT-STR数据集上,FDP-S与先前最好的方法相比,检索精度提升了4.37%,速度快了4倍。在更有挑战性的SVT和TotalText数据集上,FDP仍然能获得具有竞争力的结果。
表1 FDP与已有方法在常用数据集上的性能对比
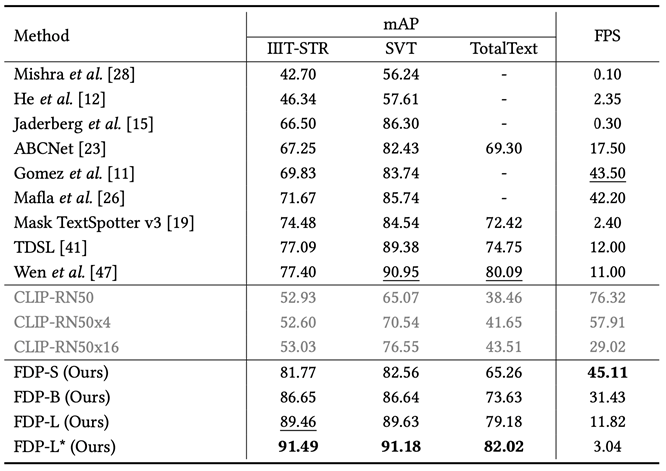
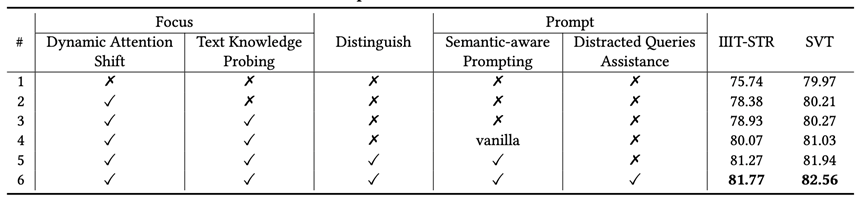
表2 消融实验结果
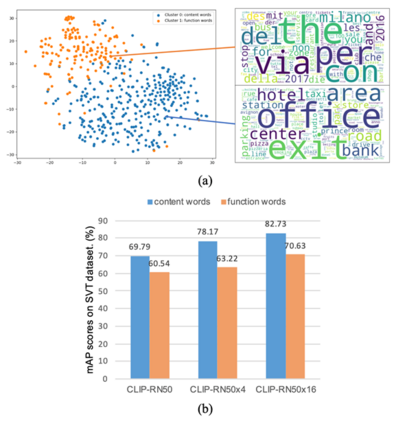
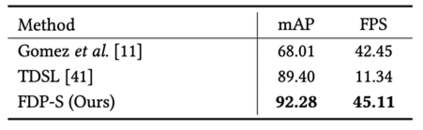
为了验证FDP在处理不同形式查询文本上的优势,作者构建了一个词组级别的场景文字检索数据集PSTR。如表3和图5结果所示,FDP在该数据集上明显优于传统的基于局部检索的方法。图6的定性结果进一步说明FDP能够感知场景文字的颜色、字体和位置等属性信息,具有很好的泛化性。
表3 FDP与已有方法在PSTR数据集上的性能对比
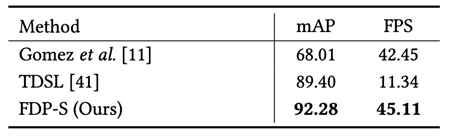
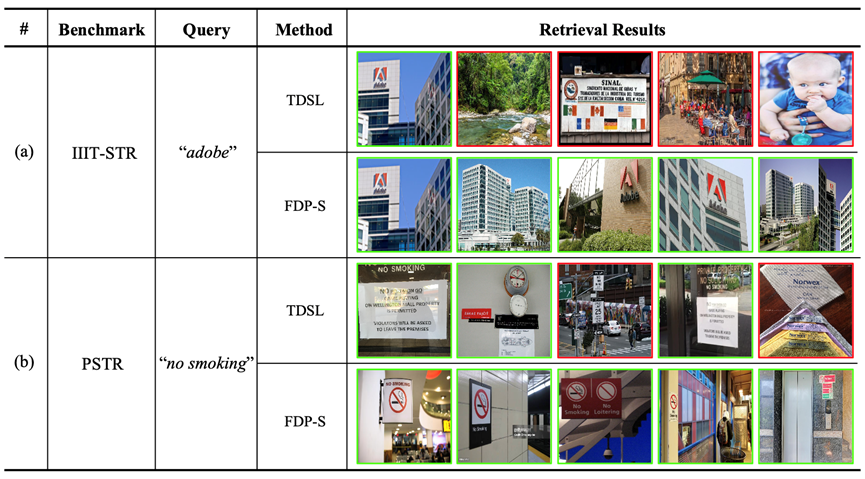

图6 FDP用于属性感知文字检索的定性结果 四、总结与讨论****
最近的一些工作[5, 6]表明,CLIP模型通过在大量图像-文本数据上预训练,已经具备了一定的OCR能力。受此启发,本文提出一种新视角:是否可以利用CLIP的内在潜能实现准确、高效且灵活的场景文字检索。对此,论文设计提出了一个无需感知的场景文字检索模型FDP (Focus, Distinguish, and Prompt),其中“Focus”步骤挖掘了CLIP中隐含的场景文字有关知识,“Distinguish”和“Prompt”步骤进一步克服了视觉语义纠缠带来的负面影响。在三个公开数据集上的实验结果证明了所提出模块的有效性,并表明FDP在检索精度和速度之间取得了更好的平衡。此外,FDP可以很容易地推广到词组级别或属性感知场景下的文字检索,更适用于实际需求。
五、相关资源****
论文链接:https://arxiv.org/pdf/2408.00441 代码(即将开源):https://github.com/Gyann-z/FDP 参考文献****
[1] Hao Wang, Xiang Bai, Mingkun Yang, Shenggao Zhu, Jing Wang, and Wenyu Liu. 2021. Scene text retrieval via joint text detection and similarity learning. In CVPR. 4558–4567.[2] Lilong Wen, Yingrong Wang, Dongxiang Zhang, and Gang Chen. 2023. Visual matching is enough for scene text retrieval. In WSDM. 447–455.[3] Lluís Gómez, Andrés Mafla, Marçal Rusinol, and Dimosthenis Karatzas. 2018. Single shot scene text retrieval. In ECCV. 700–715.[4] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022. Learning to prompt for vision-language models. IJCV 130, 9 (2022), 2337–2348.[5] Yiqi Lin, Conghui He, Alex Jinpeng Wang, Bin Wang, Weijia Li, and Mike Zheng Shou. 2023. Parrot captions teach clip to spot text. arXiv preprint arXiv:2312.14232.[6] Cheng Shi and Sibei Yang. 2023. Logoprompt: Synthetic text images can be good visual prompts for vision-language models. In ICCV. 2932–2941.
原文作者:Gangyan Zeng, Yuan Zhang, Jin Wei, Dongbao Yang, Peng Zhang, Yiwen Gao, Xugong Qin, Yu Zhou撰稿:曾港艳、周宇编排:高 学审校:连宙辉发布:金连文