论文推荐| [CVPR 2020 Oral] ABCNet:基于自适应贝塞尔曲线的实时端到端自然场景文字检测及识别网络(附代码)

本文介绍的是被CVPR2020录取为Oral的论文“ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network”。这篇文章的想法最开始是由金老师提出来,后来在阿德莱德沈老师组里访问期间合作完成。这是一篇关于曲线端到端场景文字检测识别的方法。主要特点就是能处理任意形状的场景文本,速度快,而且精度较高,目前完整的代码也已经开源(包括使用到的数据等),供完整复现,我们会在文末附上链接。
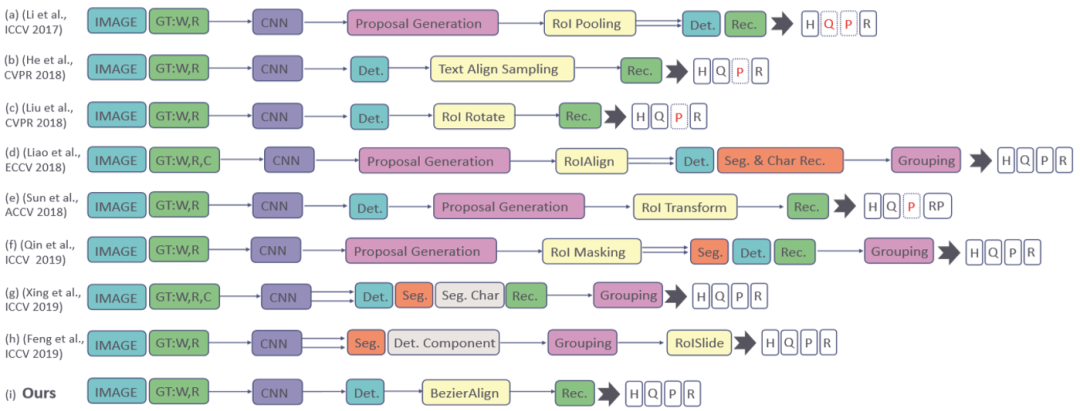
由上图可以看到,早期的一些端到端方法只能够处理一些规则形状的场景文本。为了处理曲线文本,有些方法利用了单字级别的标注,有些方法则利用了分割的思路,前者通常需要高昂的标注代价,后者则需要比较复杂的后处理。此外,过去端到端的方法最大的创新一般是在连接检测与识别的采样模块,这一模块,在过去无一例外都需要矩形或者是四边形的输入,而且在处理曲线文本的时候有很大的局限性。
本文提出的方法是一种Single-Shot的方法,框架简单速度较快。相较以往的采样方法的输入只能是矩形或者四边形,这篇文章所采用的BezierAlign能够将参数化的不规则包围盒矫正成水平矩形。这个工作的动机主要是由于以往的端到端的场景文本检测识别的方法通常存在两个比较大的问题:
-
一是速度太慢。因为这些方法有些需要复杂的两阶段方法去堆砌先进的检测和识别的框架;有些则需要先训练识别分支再训练检测分支,使得端到端的框架实际上没有进行端到端的训练;有些则需要例如基于分割的复杂的后处理方式去适应各种形状的自然场景文本。由于端到端的速度比起单独的两个检测和识别的框架没有优势,这样的局限也使得在过往RRC比赛中,端到端的任务取得最好的结果的方法几乎全是使用各自独立的检测和识别的网络。 -
二是检测识别的特征连接模块。对于任意形状的场景文本,以往的检测识别的方法往往需要基于TPS的方法对检测的结果进行矫正。而这样的一个额外的过程一方面会明显降低速度,使得框架更复杂,另一方面也容易导致文本矫正区域由于矫正的难易程度以及准确程度,使得后续识别性能降低。
那么是否能够设计一种端到端的算法,这种算法既能处理自然界中各种形状的场景文本,又能真正做到端到端的训练,还能达到实时的性能呢?为此,本文提出了两个创新点:
-
使用贝塞尔曲线来对曲线文本的形状进行建模。既然水平文本使用矩形框,四边形文本使用四边形框,曲线文本为何不能使用曲线框呢?一方面曲线框需要的参数数量明显少于多边形框,另一方面其能够平滑地拟合曲线文本边界从而可以最大程度地减小文本的形变。而贝塞尔曲线作为曲线表达的一种最基本的数学形式,用来作为包围盒定位的方式是一种很自然的想法。 -
使用贝塞尔曲线对齐层BezierAlign来用于连接检测识别的特征。参数化的贝塞尔曲线边界使得在边界上采点变得十分容易,进而可以简单地采用并行的方式去提取曲线文字区域的特征。而这也是第一次对边界参数化进行端到端训练的尝试。
事实上,过去的一些端到端的方法也可以无须通过TPS或者STN的方法,而是效仿BezierAlign的方式将边界参数化来进行采样,从而提高性能。
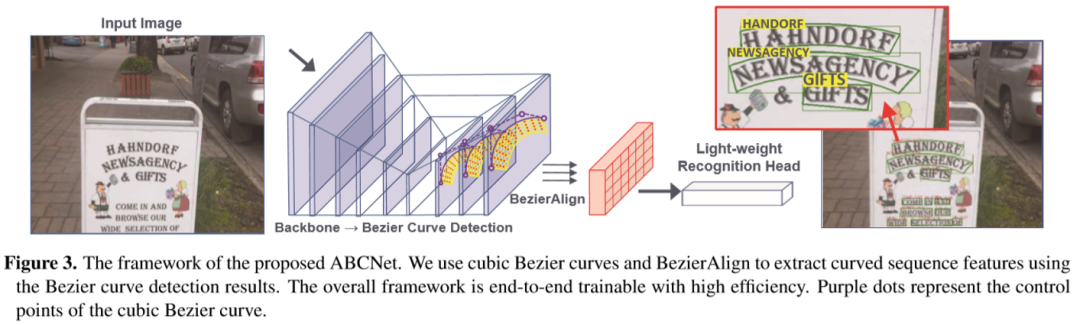
本文的网络框架设计主要可以分为基于FPN的Anchor-free的文字检测模块,连接检测识别特征的采样模块,以及一个轻量级的识别模块。文本检测模块基于FPN在P3-P7上执行不同比例的文本检测,此部分与FCOS相同。随后的识别特征以1 / 4、1 / 8和/ 1/16的三个比例提取。本文的主要的创新之处在于边界框的建模。在这里,如前文提到,我们使用了贝塞尔曲线来建模任意形状的文本。为此,我们首先简单介绍一下何为贝塞尔曲线。
贝塞尔曲线是法国雷诺汽车公司的工程师Bezier最早提出的一种曲线构造方法,它基于逼近(拟和)的概念,以其直观和设计简单的优点自1962年出现以来在图像处理中被广泛应用。
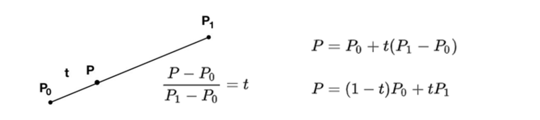
我们可以从线性插值开始理解贝塞尔曲线。由上图所示,假定P在P0P1上移动,那么P0P与整个路径的比值就是t,将这个式子变形我们可以得到P的位置关于t的一个函数,其中t属于0-1之间。
那么如果这里有两条线段,情况如下图所示,根据上图,我们可以得到S1,S2,S关于t的函数,将S1,S2带入S中,我们能够得到S关于t的一个一元二次多项式,而这个式子就是一条二次贝塞尔曲线。
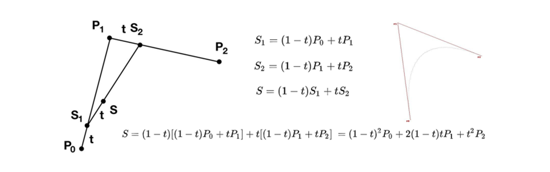
同样的方法,如下图所示,我们可以得到三次贝塞尔曲线,式子中的P就是对应4个控制点,他们都是常数。以此类推,我们能够得到N次贝塞尔曲线的公式,其中Bn,k即为大家所熟知的伯恩斯坦多项式,而(n k)则为二项式系数。
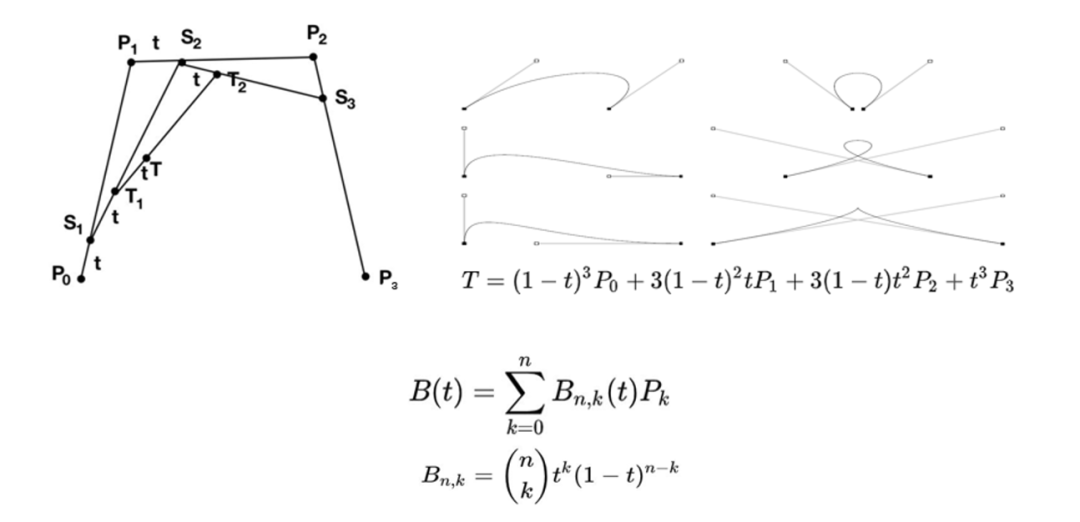
现在可以了解到,给定比例系数t以及其对应的固定点P,就可以确定一条贝塞尔曲线。那么对于任意曲线文本,如何利用贝塞尔曲线去表示,即是一个反推的过程,即已知曲线上的一些点,推到贝塞尔曲线对应的系数。
由于三阶曲线基本能涵盖绝大多数的自然场景文本,同时其极少的参数量有利于简化模型,本文利用了三阶贝塞尔曲线去拟合文本,也就是每条曲线需要四个控制点,那么一个文本实例框总共需要8个控制点。由于直线框是曲线文本的特例,对于两条长边,边的两端是两个控制点,其余两个控制点则按照1/3的位置在长边进行插值,保证所有框的参数量一致。
但是由于现存的数据都是基于多边形的,所以我们必须根据多边形的标注点生成贝塞尔曲线的控制点才能够对模型进行训练。
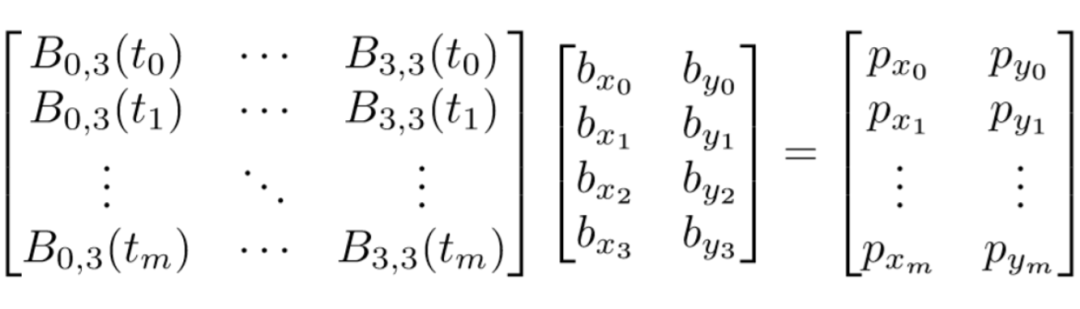
如下图所示,左边是原始GT, 对于CTW1500而言,一个曲线边的标注点的个数是7个,他们的坐标值也就是对应上面等式的右项。我们要求解的4个控制点的坐标值就是中间这项。为了求解,我们需要算出系数是多少,也就是t为多少时对应哪一个控制点。这里的t我们则通过折线段的累计长度与7个点构成的折线段的周长的比值来确定。根据之前的贝塞尔公式,我们能够求得所有伯恩斯坦多项式的值,又由于方程个数大于解的个数,我们可以通过最小二乘解反解出四个控制点的坐标值,结果如右下图所示。

可以看到,生成的结果包围盒的边界明显更加平滑了。
下图显示了更多的结果。我们事实上观察过所有的生成结果,基本上三次贝塞尔曲线能够比较完美地去拟合各种形状的文本的边界。所有生成的结果也都放在了文末的链接上。

BezierAlign
在确定标签后,模型可以很好的训练和预测,在模型预测得到控制点后,为了较好的获得文本区域,这里作者提出了BezierAlign用于特征对齐。那么BezierAlign与其他的采样方式有什么不同呢?

以前的采样方法的输入要么是水平矩形,要么是四边形。这些方法都无可避免地会采到背景的信息,从而影响了识别。即使是像RoI Masking的方法,也是会受到分割噪声以及横向分散切割导致识别性能下降的影响。而BezierAlign只对两条曲线包围区域内的像素进行Align,即给定输入的Feature Map以及对应的曲线的控制点,BezierAlign并行地对区域内的点进行处理。在[0-1]中取一个值t,可以根据贝塞尔曲线方程得到上边界的点tp和下边界点bp,根据线性插值就可以得到tp到bp连线中的所有点的位置:
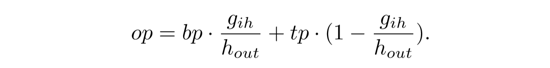
以此类推即可得到整个区域内的点的位置,进而可以利用双线性插值得到BezierAlign后的特征。从下面的可视化也可以发现BezierAlign对曲线文本的识别也是有明显帮助的:

识别分支
识别部分由于共享了检测部分的特征,文章中使用了较为轻量的结构:
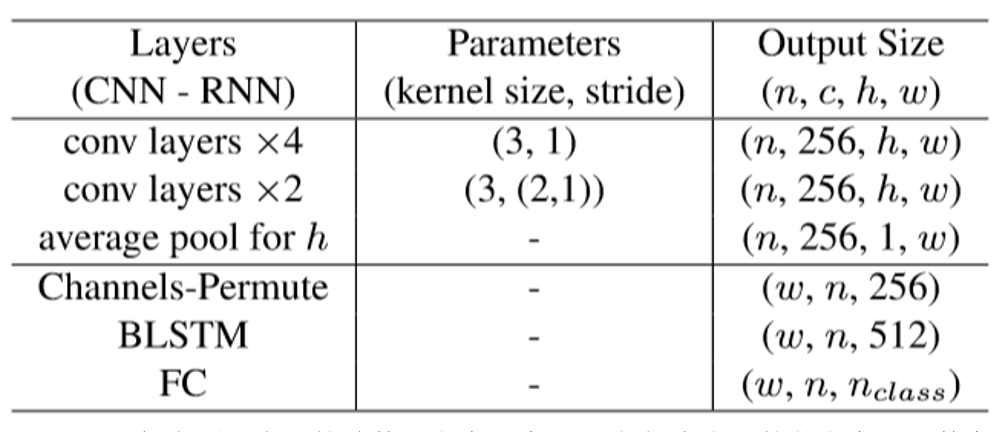
其中N_Class 代表预测类别的总数,文中设为97,包括大小写的英文字母,数字,符号,其中倒数第二类代表所有其他的字符(主要是代表CTW1500中出现的所有中文),最后一类代表终止符。
当然,对于端到端的训练尤其是识别来说,需要大量的样本,我们因此也合成了15W张合成图片。具体来说,我们从COCO-Text中过滤出4万张无文本的背景图像,然后准备分割蒙版和每个背景图像的深度。我们通过修改VGG合成方法对文字渲染, 扩大形状的多样性,用各种艺术字体和语料合成场景文本,同时为所有文本实例生成多边形标注。然后将标注用刚刚介绍的贝塞尔曲线GT的生成方法得到控制点的坐标值。
我们合成了两批数据,第一批94,723张,主要包含弯曲幅度较小的文本。第二批54,327,包含了较多明显弯曲的文本。数据集也都有公开在文末的相关链接中。
本文的方法在基于文本行的CTW1500和基于单词级别的Total-Text上均取得了目前最好的性能:
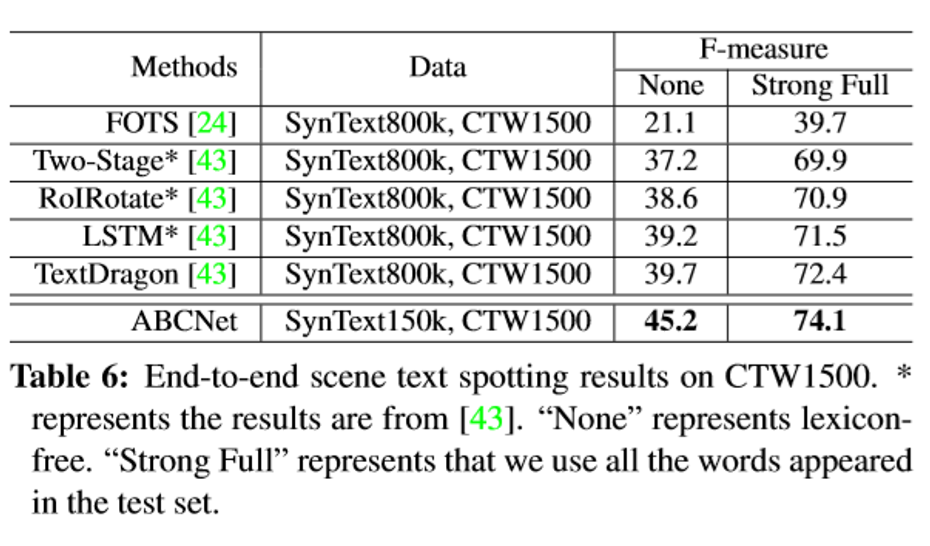
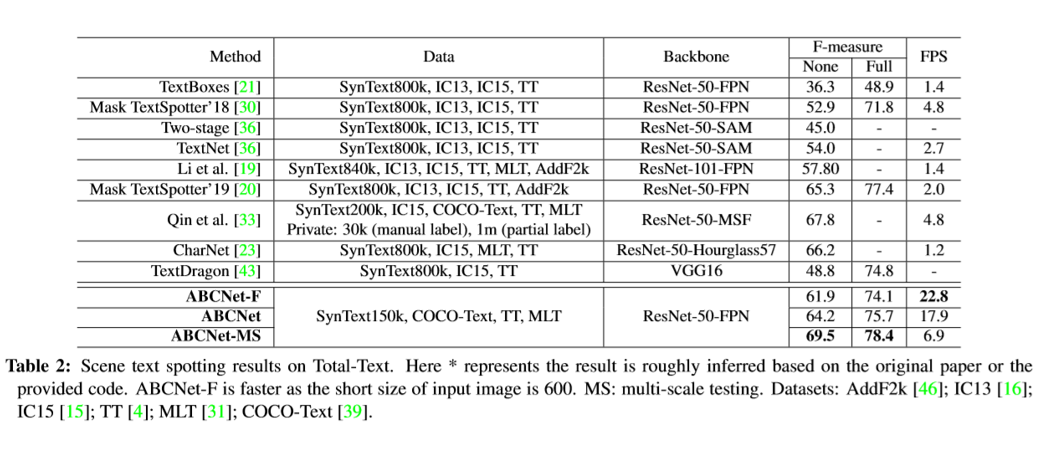
更多详细内容参考论文,部分端到端检测及识别结果如下图所示:

弯曲的文本在现实世界中非常普遍,例如,在柱状物体中的文本例如桶和瓶子,球形物体,诸如褶皱平面,例如衣服,彩带,招牌,硬币和徽标等。在大多数购物中心中,很容易找到许多弯曲的文字。因此,成功的场景文本应用无法忽视这些高度呈现的弯曲文本所具有的工业价值。
这篇文章提供了一个用曲线数学表达形式作为曲线平滑建模的新思路,其采用的贝塞尔曲线只是一种最简单的方法,三次贝塞尔曲线不一定能够完美包围极端的任意形状文本,但是本文的方法为后续采用更复杂的类似高阶贝塞尔曲线,B样条曲线,NURBS等曲线形式奠定了基础。
本文提出的BezierAlign也使得特征提取更为准确,这自然会带来性能的提升。实际上,过去很多端到端的方法也可以在不使用TPS或STN的情况下对检测特征进行采样,而可通过类似BezierAlign方法对边界进行参数化以提高性能,这值得进一步研究及验证。
ABCNet在两个数据上均达到了SOTA,同时相较于以往的任意形状场景文本的端到端方法,本文的速度也有明显的优势。
承蒙评委厚爱,本文的CVPR评审的最终得分是111。
文章链接:https://arxiv.org/abs/2002.10200
代码链接:
https://github.com/aim-uofa/AdelaiDet(detectron2,提供 完整训练测试代码,数据,demo 等,会持续更新)
https://github.com/Yuliang-Liu/bezier_curve_text_spotting (PyTorch版, 该版本目前只提供demo)
原文作者:Yuliang Liu, Hao Chen, Chunhua Shen, Tong He, Lianwen Jin, Liangwei Wang
编排:高 学
审校:连宙辉
发布:金连文






