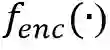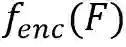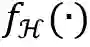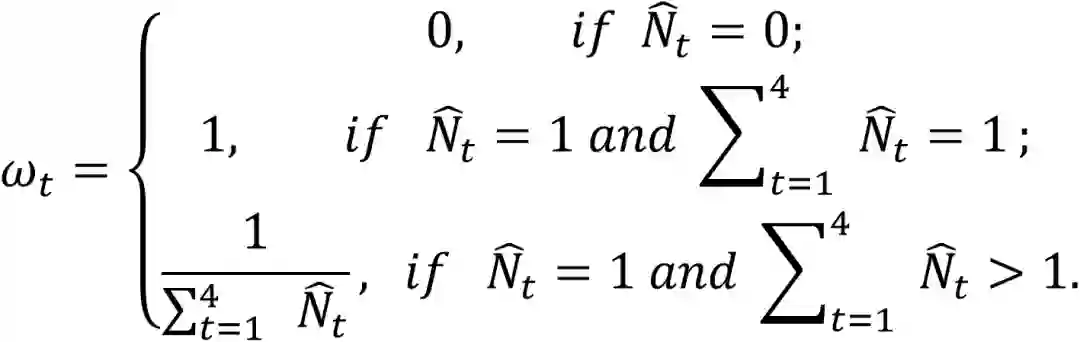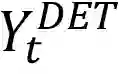本文简要介绍ICML 2024 Spotlight论文 “Towards Unified Multi-granularity Text Detection with Interactive Attention” 的主要工作。该论文提出了一种名为“Detect Any Text”(DAT) 的新型文字统一检测算法框架,高效解决文档智能应用中不同粒度文字检测需求,具体包括单词、文字行、段落以及页面四种粒度。本文的主要贡献在于引入了跨粒度的特征交互模块,通过学习不同粒度文字实例之间的结构相关性,从而有效提升模型对于各种粒度文本的检测效果;以及设计了一种混合粒度训练策略,以端到端的形式并行完成不同粒度文字的检测任务,从而显著降低了多粒度文字检测的算法复杂度。

图1 多粒度文字实例之间的结构相关性示意图;第一行为原始图片;第二行为多粒度文字检测结果真值,分别包括单词(用黄色多边形标注)、文字行(用绿色多边形标注)、段落(用棕色多边形标注)和页面(用紫色轮廓标注)。
一、研究背景****
现有的OCR引擎或者文档图像分析系统通常需要为不同应用场景(场景文字检测、版式分析、页面分割等)和不同粒度(单词、文字行、段落、页面等)的文字检测任务训练多个独立的模型,这会导致过高的计算复杂度和资源开销。此外,如图1所示,在自然场景或者电子文档中,不同粒度的文字通常存在着内在的结构相关性(例如从页面-段落-文字行-单词存在着级联的包含关系),现有的文字检测方法例如ESText-Spotter[1]、HierText[2]等在特征学习阶段并未有效利用这种结构相关性,从而导致检测效果难以提升。 针对以上两方面的问题,本文提出的多粒度文字检测算法DAT旨在统一场景文字检测、版面分析、文档页面检测任务,输出一个端到端的模型,能够高效地处理包括单词、文字行、段落、页面在内的不同粒度的文字实例。此外,在特征学习阶段,通过跨粒度的特征交互建模以自上而下和自下而上两种方式学习不同粒度的文字实例之间的结构相关性,从而有效提升各种文字粒度的检测效果。
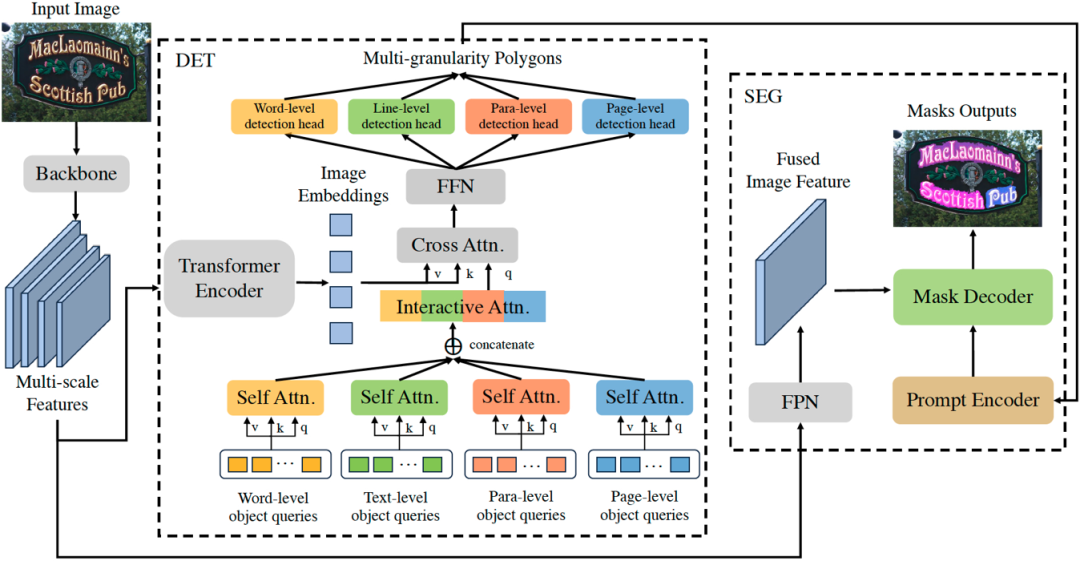
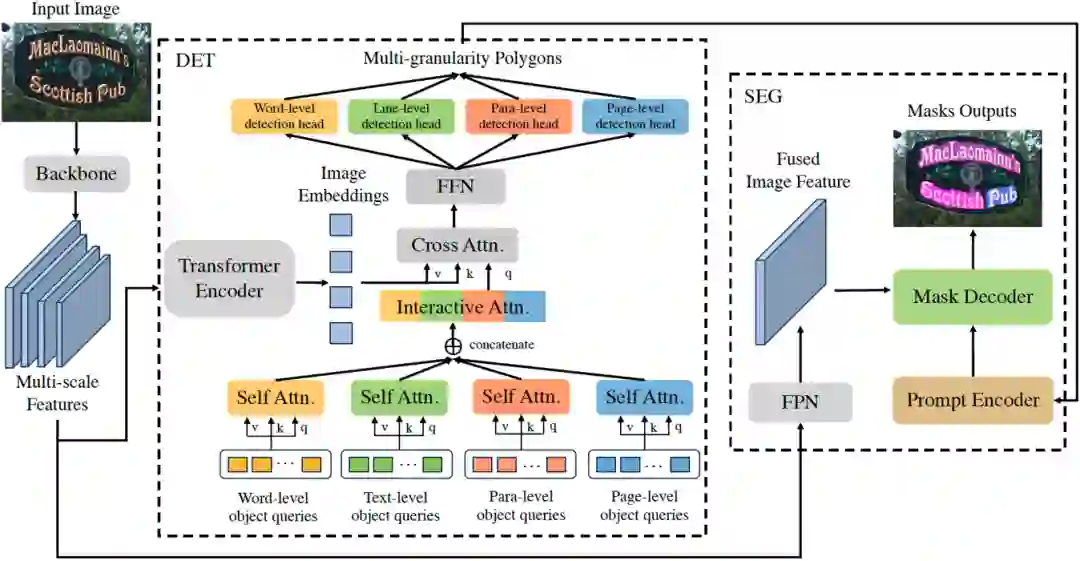
图2 Detect Any Text (DAT) 网络结构图。“DET”展示了多粒度检测框架中一个单层Transformer解码器的网络结构,其中省略了残差连接和归一化层。“SEG”展示了基于提示的分割模块的网络结构。 二、方法原理简述****
本文介绍的DAT算法基于Transformer的网络结构,在Transformer Decoder的部分以Group的形式并行进行四种文字粒度的检测任务,然后使用一个级联的Mask Decoder用来进一步实现精细的文字分割任务。DAT的网络框架如图2所示, 其整体流程如下: * 首先,给定输入图像 , 经过骨干网络得到多尺度的特征图F, 然后在Transformer Encoder
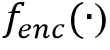
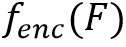
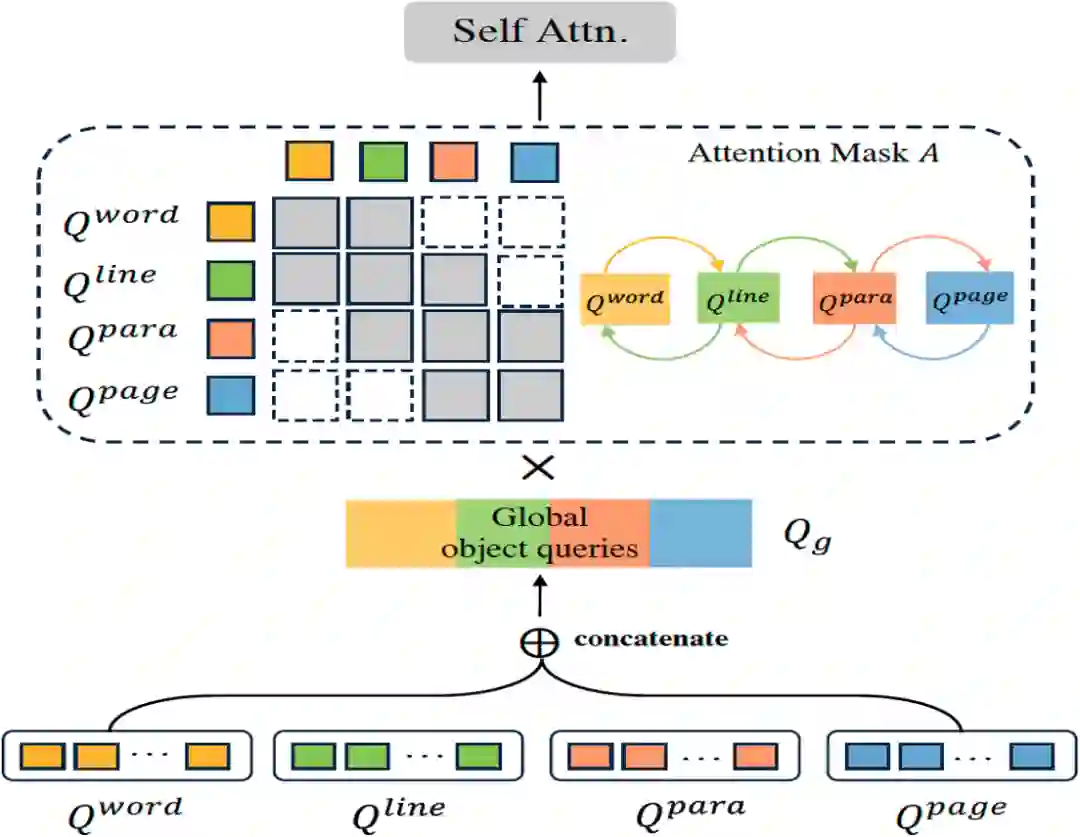
、注意力掩码A和分组的查询向量Q作为输入,进行交互式的特征学习和针对文字实例的全局推理,然后经过一个多任务检测头
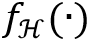
。 * 最后,采用一个FPN网络
来获取多尺度特征图F融合后的图像特征,输入到一个基于提示的Mask Decoder,使用文字检测结果
来进行基于检测的图像分割得到多粒度的文字分割结果
。
2.1 多粒度检测框架和混合粒度学习 为了实现多粒度文字检测的并行训练和推理,我们为每种粒度的文字实例分别初始化一组可学习的查询向量,组成 作为Transformer Decoder的输入。每一层Transformer Decoder网络由3个部分组成:1)用于学习每种粒度的查询向量的组内自注意力模块,其参数不共享;2)用于关联不同粒度查询向量之间的结构信息的跨粒度特征交互模块(在下个小节具体介绍);3)用于全局推理的参数共享的交叉注意力模块和前馈网络(FFN)。用于优化多粒度文字检测任务的损失函数如下所示:
其中下标t表示单词、文字行、段落、页面四种不同粒度的任务。本文采用一种混合粒度学习策略来定义多任务的损失权重 :
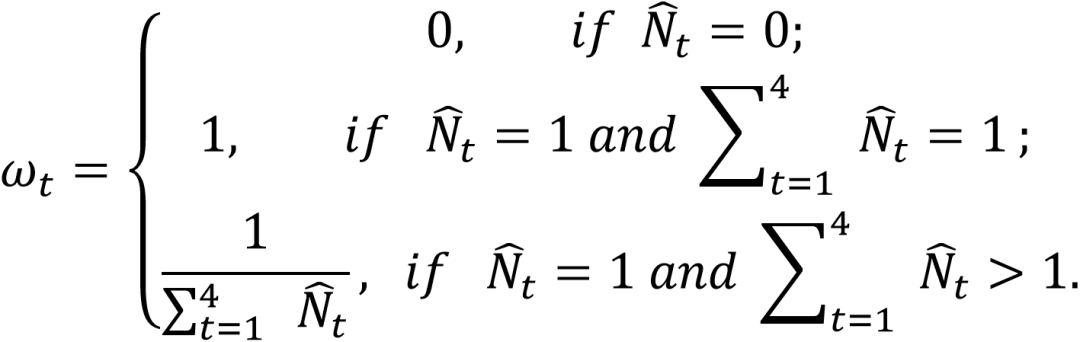
这里 是一个0或1的标志符,表示粒度t的标签是否在真值中。值得一提的是,每个文本粒度的损失权重
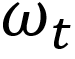
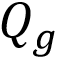
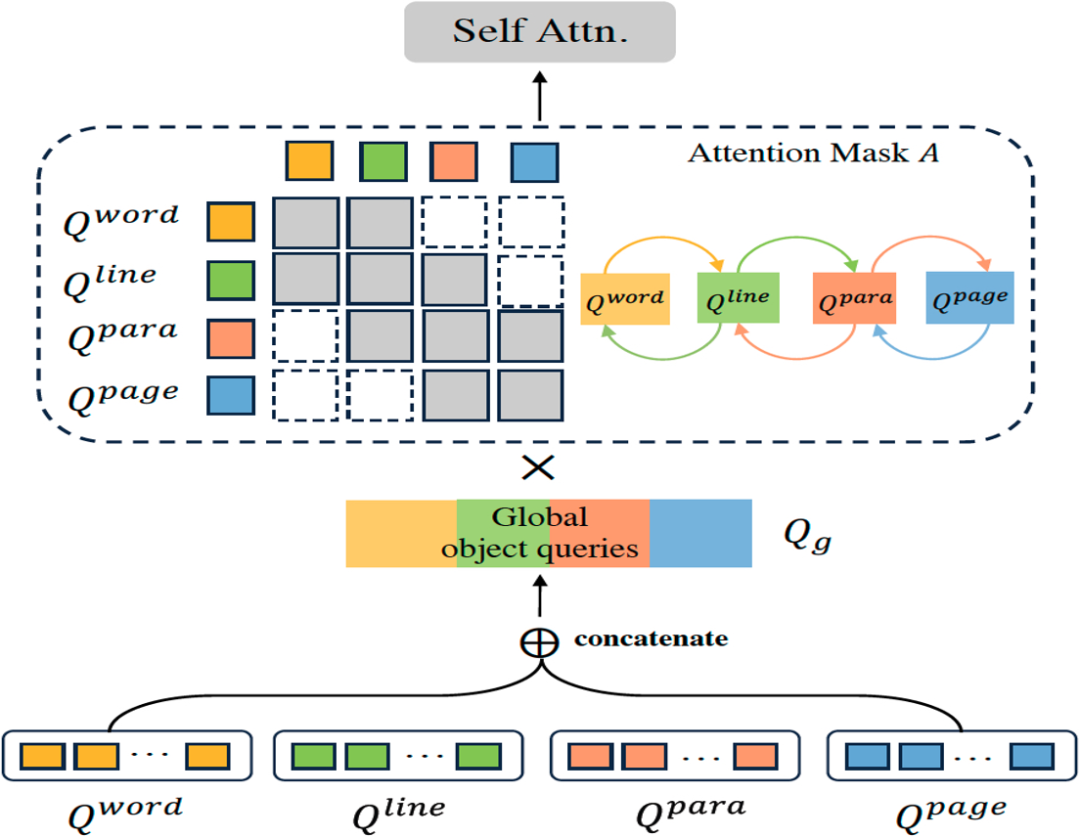
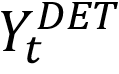
。Prompt Encoder通过将一组可学习的特征向量与每个多边形坐标的位置编码相加来表征多粒度的多边形检测结果。Mask Decoder包括自注意力模块、双向的交叉注意力模块、上采样和MLP模块。使用这些多粒度检测结果作为提示,Mask Decoder能够对文本轮廓进行更精细的分割,从而显著提升对弯曲和任意形状文本的检测效果,以及支持复杂布局和页面主体的分割。
三、主要实验结果及可视化结果****
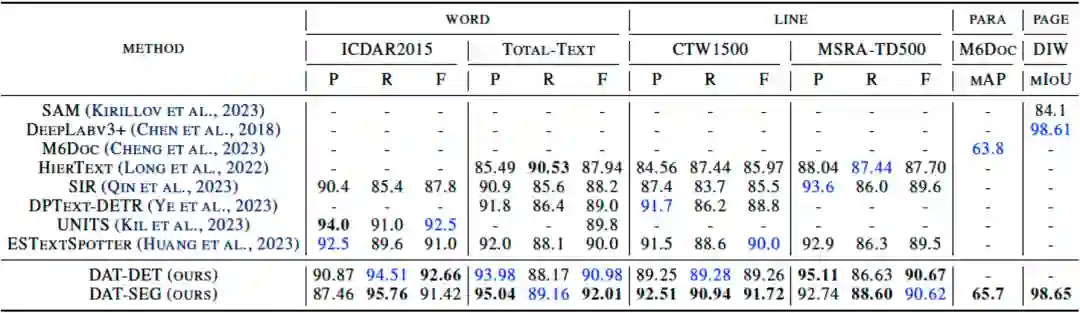
本文对多粒度检测算法DAT的各个模块(包括检测、分割模块、特征交互模块、不同文字粒度的影响等)进行了详细的消融实验,并在4种粒度的多个公开数据集上进行了效果验证,包括单词粒度的ICDAR2015和Total-Text、文字行粒度的CTW1500和MSRA-TD500、段落粒度的M6Doc、页面粒度的DIW数据集,在4种粒度上均取得了SOTA的结果。同时,通过引入级联的文字分割模块SEG,DAT能够在弯曲文字数据集Total-Text和CTW1500上实现更进一步的效果提升。此外,本文还通过消融实验证明,在特征交互模块中进行自下而上和自上而下的双向跨粒度交互能够为每一种粒度的文字检测任务均带来效果上的增益。Table 1 DAT和其他SOTA方法在单词、文字行、段落、页面4种粒度公开benchmark上的检测结果对比。“P,R,F”分别代表精度(Precision)、召回率(Recall)和F1分数(Fscore)指标。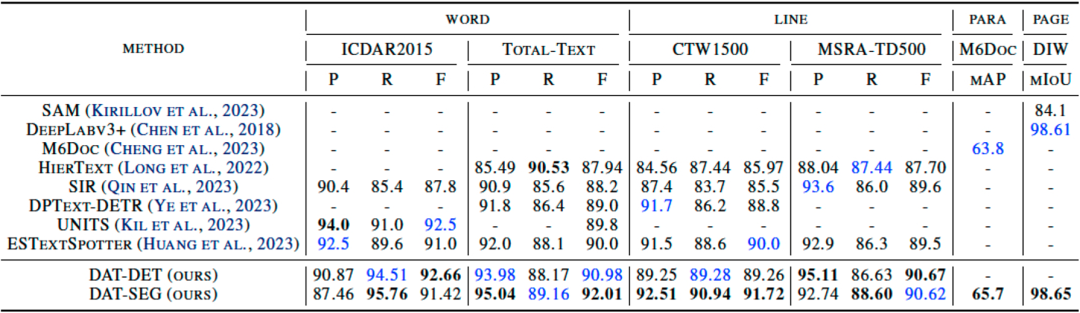




本文提出了一种全新的多粒度文字检测范式,称为“DAT”。受到在自然场景中不同文字粒度之间固有结构关系的启发,我们在文字检测解码器中设计了一个双向特征交互模块用来增强模型对于所有粒度的表征学习能力。值得强调的是,我们的方法不需要所有粒度上的完整标注数据,能够在一个统一的检测框架内并行训练以同时进行单词、文字行、段落和页面粒度的文字检测任务。在公开数据集上的广泛实验表明,DAT显著提升了所有粒度的文字检测效果,建立了新的多粒度文字检测算法的SOTA基准。此外,我们还集成了一个基于提示的分割模块用于准确定位任意形状的文本以及分割文档页面。这些创新的设计使得DAT在包括场景文字检测、版式分析[4]、页面分割[5]任务在内的多个基准上超过了其他的SOTA的单任务模型。 五、相关资源****
论文链接:https://arxiv.org/abs/2405.19765 参考文献****
[1] Huang, M., Zhang, J., Peng, D., Lu, H., Huang, C., Liu, Y., Bai, X., and Jin, L. Estextspotter: Towards better scene text spotting with explicit synergy in transformer. In ICCV, pp. 19495–19505, 2023. [2] Long, S., Qin, S., Panteleev, D., Bissacco, A., Fujii, Y., and Raptis, M. Towards end-to-end unified scene text detection and layout analysis. In CVPR, pp. 1049–1059, 2022. [3] Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., et al. Segment anything. In ICCV, pp. 4015–4026, 2023. [4]Cheng, H., Zhang, P., Wu, S., Zhang, J., Zhu, Q., Xie, Z., Li, J., Ding, K., and Jin, L. M6doc: A large-scale multi-format, multi-type, multi-layout, multi-language, multi-annotation category dataset for modern document layout analysis. In CVPR, pp. 15138–15147, 2023.[5]Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., and Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, pp. 801–818, 2018.
原文作者:Xingyu Wan, Chengquan Zhang, Pengyuan Lyu, Sen Fan, Zihan Ni, Kun Yao, Errui Ding, Jingdong Wang