

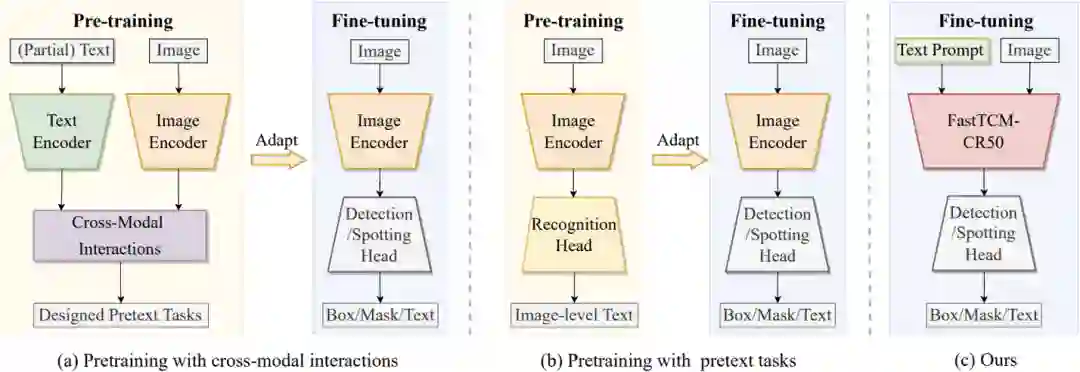
一、研究背景****
大规模对比语言-图像预训练CLIP模型[1]通过利用预训练的视觉和语言知识在各种下游任务中展现了巨大的潜力。场景文本包含丰富的文本和视觉信息,与像 CLIP 这样的视觉语言大模型有着固有的联系。现有利用视觉语言预训练的工作[2-4]通常包含两个阶段:第一个阶段需要设计合适的代理任务进行预训练,充分挖掘文本知识,使得视觉编码器能够较好地感知到文本;第二个阶段再对第一个阶段预训练好的视觉编码器进行微调,使其能够较好地执行下游的文本检测或者端到端文本识别任务。这篇文章介绍了一种新方法FastTCM,专注于直接将CLIP 模型用于文本检测和端到端文本识别,无需设计特殊的预训练代理任务。
二、方法原理简述****
FastTCM整体框架如图2所示,包含CLIP的图像编码器、文本编码器、视觉提示模块、文本提示单元和下游的文本检测或端到端文本识别头。其中,文本提示单元包含文本提示模块和双模态相似匹配机制。首先视觉编码器对图像进行编码,得到全局视觉特征;其次,文本提示模块通过可学习的元查询和预定义的提示构造有利于下游任务的提示,并送入文本编码器编码得到文本嵌入;接着,双模态相似匹配机制计算当前图像特征和文本嵌入的相似度,并将该相似度和图像特征相乘叠加到文本嵌入生成新的文本嵌入,该机制可以根据输入的视觉图像特征动态的调整文本编码器的输出,充分挖掘CLIP中预训练的文本知识,有利于后续提取细粒度的视觉图像特征。之后的流程和会议版本的工作[5]一致。在训练时文本提示模块的参数需要参与训练优化,当训练完成时该模块参数被固定,在推理时可以将文本编码器部分的输出离线计算,以此来减少推理时间。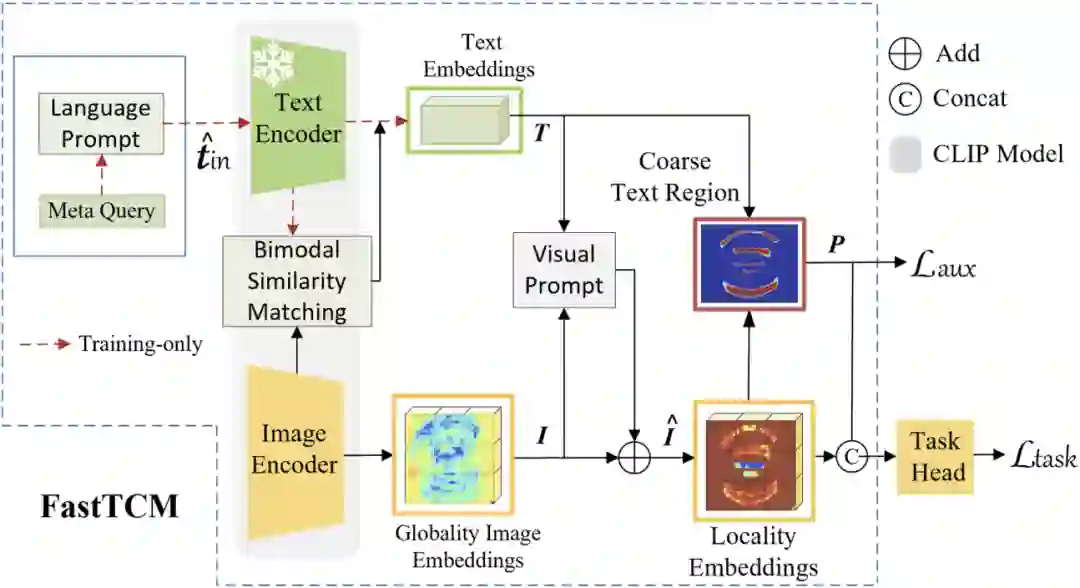
作者将FastTCM应用于现有的文本检测方法和端到端文本识别方法上进行了实验验证,发现FastTCM可以应用于改进现有的场景文本检测方法和端到端文本识别方法,并且速度有所提升,同时可以提升现有方法的小样本学习能力和泛化能力。表1 分别提升现有的文本检测方法和端到端文本识别方法的性能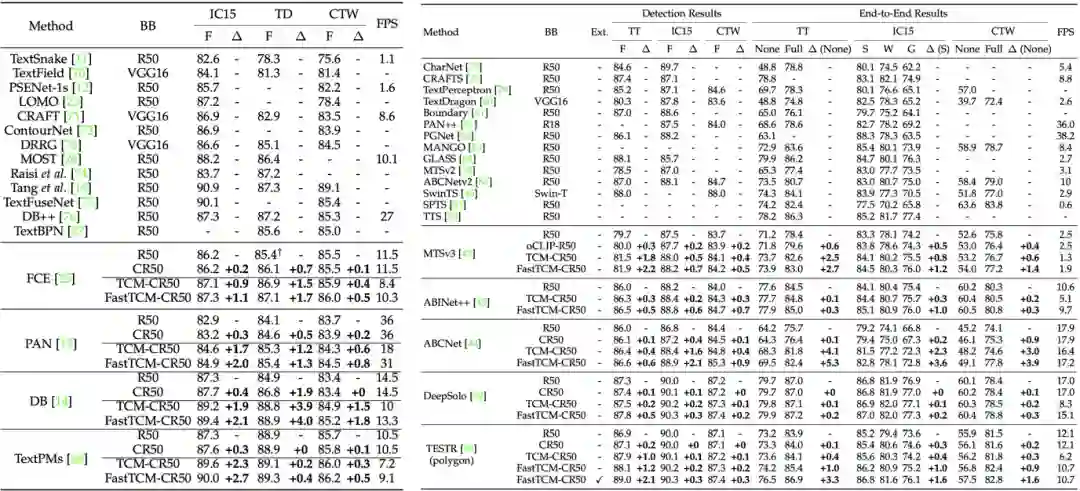
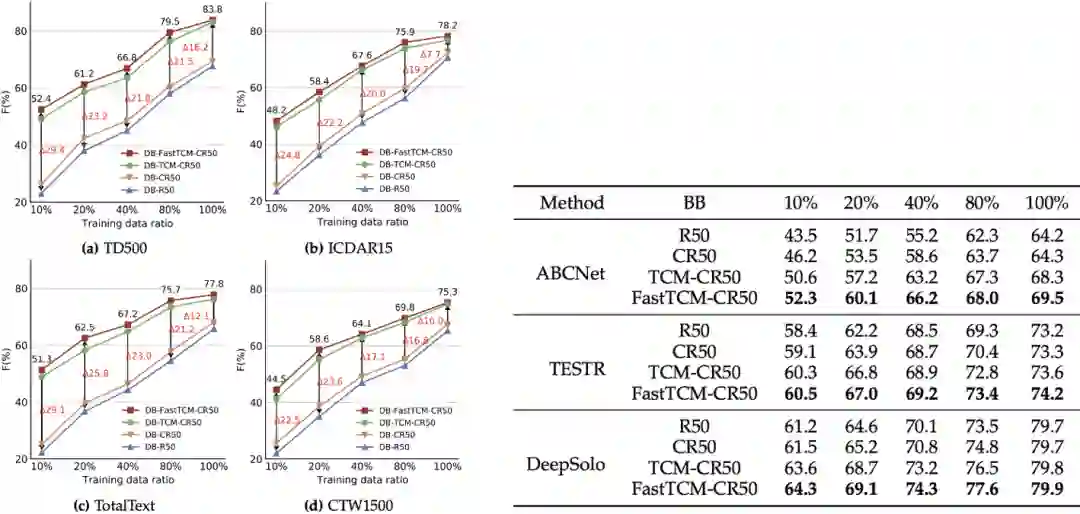

作者进一步在旋转目标检测任务上进行了验证,并在遥感图像数据集DOTA-v1.0[6]上进行了实验,本文提出的方法依旧可以适用于遥感目标检测,下图展示了可视化结果。

四、未来展望
本文提出了一种利用大规模对比语言-图像预训练 CLIP 模型来提升文本检测和端到端文本识别下游任务,对迈向通用场景的文本感知任务更近了一步,未来可以继续探索借助更强大的多模态大模型[7]的能力来实现更通用的文本感知和理解任务。 五、相关资源****
论文链接:https://ieeexplore.ieee.org/document/10476714代码:https://github.com/wenwenyu/TCM 参考文献****
[1] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” in ICML, 2021. [2] Q. Wan, H. Ji, and L. Shen, “Self-attention based text knowledge mining for text detection,” in CVPR, 2021. [3] S. Song, J. Wan, Z. Yang, J. Tang, W. Cheng, X. Bai, and C. Yao, “Vision-language pre-training for boosting scene text detectors,” in CVPR, 2022. [4] C. Xue, W. Zhang, Y. Hao, S. Lu, P. H. S. Torr, and S. Bai, “Language matters: A weakly supervised vision-language pretraining approach for scene text detection and spotting,” in ECCV, 2022. [5] W. Yu, Y. Liu, W. Hua, D. Jiang, B. Ren, and X. Bai, “Turning a clip model into a scene text detector,” in CVPR, 2023. [6] G.-S. Xia, X. Bai, J. Ding, Z. Zhu, S. J. Belongie, J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “Dota: A large-scale dataset for object detection in aerial images,” in CVPR, 2017.[7] Z. Li, , B. Yang, Q. Liu, Z. Ma, S. Zhang, J. Yang, Y. Sun, Y. Liu, and X. Bai,“Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models,”in CVPR 2024.
原文作者:Wenwen Yu, Yuliang Liu*, Xingkui Zhu, Haoyu Cao,Xing Sun, Xiang Bai 撰稿:余文文编排:高 学审校:连宙辉发布:金连文
