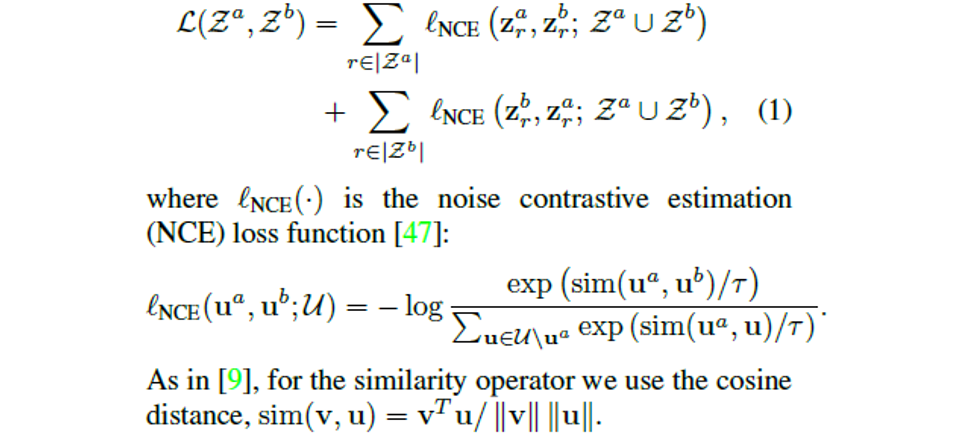![]()
本文简要介绍CVPR2021录用论文“Sequence-to-Sequence Contrastive Learning for Text Recognition”的主要工作。该论文提出了一种针对文本识别,序列到序列对比学习的无监督方法SeqCLR。
无监督的对比学习方法在图像分类、目标检测和图像分割
[1,2,3,4]
中都取得不错的成果。但是无监督和半监督的方法在文本识别中还有待进一步探索。
对于已有的无监督方法SimCLR[1],它将整张图像作为对比学习中的输入元素,这种整图、非序列化的无监督方法从后文的实验中证明对文本识别的效果很差。所以本文提出了一个序列化的无监督方法SeqCLR,它从整张图片中映射出一定数量的实例来作为对比学习中的输入元素。
![]()
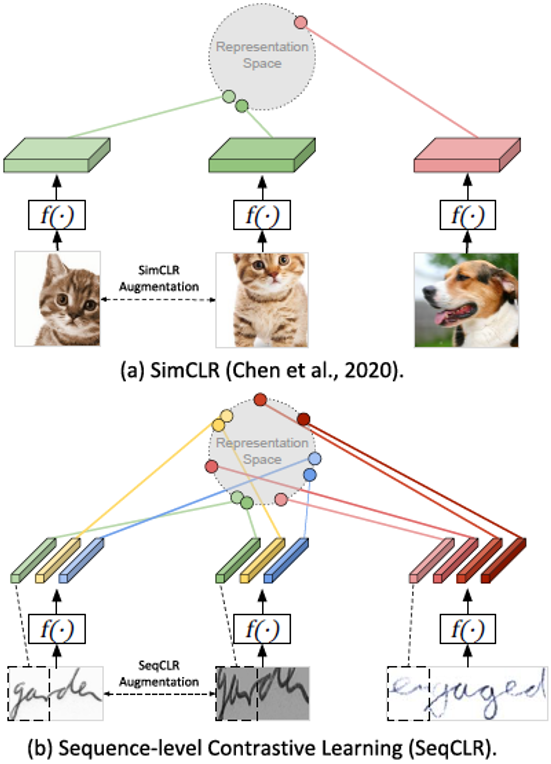
图1(a)目前的对比方法比较从整个图像中计算出的单个表示。
(
b
)
SeqCLR
的对比方法比较从整个图像中计算出的多个表示。
SeqCLR
由数据增强、编码器、投影头、实例映射四大模块构成。如图
2
所示,为
SeqCLR
的框架。
![]()
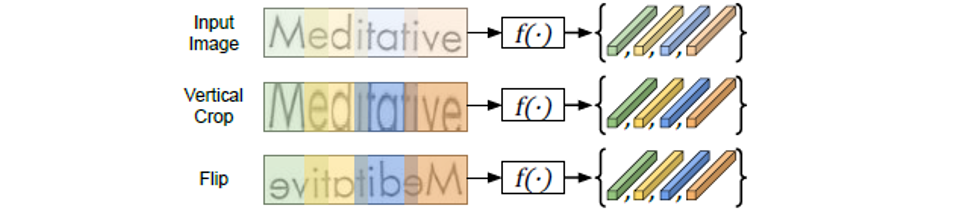
数据增强(Data Augmentation)
:这里的数据增强要避免会产生序列不对齐的增强方式。如图3所示,垂直裁剪保持序列对齐,而水平翻转会产生序列不对齐。
![]()
编码器(Base Encoder)
:编码器由CNN和BiLSTM构成。图片经过编码器后会得到带有上下文信息的序列。
投影头(Projection Head)
:由于多层感知器MLP只能处理定长的序列,而这里的输入图片是不定长的。所以投影头会根据后面的实例映射方式来决定。对于Frame-to-instance的实例映射方式,投影头采用多层感知器MLP;对于Window-to-instance和All-to-instance的实例映射方式,投影头采用BiLSTM。
实例映射(Instance Mapping)
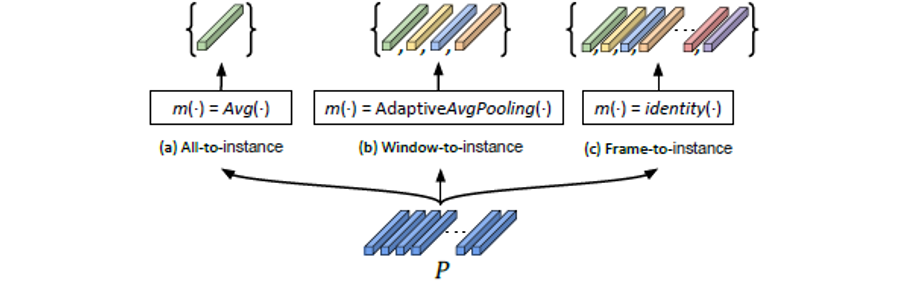
:实例映射有三种方式,分别是All-to-instance、Window-to-instance和Frame-to-instance。All-to-instance表示取每一张特征图的平均值,然后形成一个具有通道数长度的实例向量;Window-to-instance表示每一张特征图自适应平均池化T(文中T=5)个值,然后形成T个实例向量;Frame-to-instance表示特征图进行恒等映射,然后形成特征图宽度数量的实例向量。如图4所示,为三种实例映射方式的图解。
![]()
通过实例映射后得到实例向量集,然后将实例集放入对比损失函数中计算损失值。文中的对比损失函数为NCE[5],如下所示为NCE的计算公式。
![]()
SeqCLR
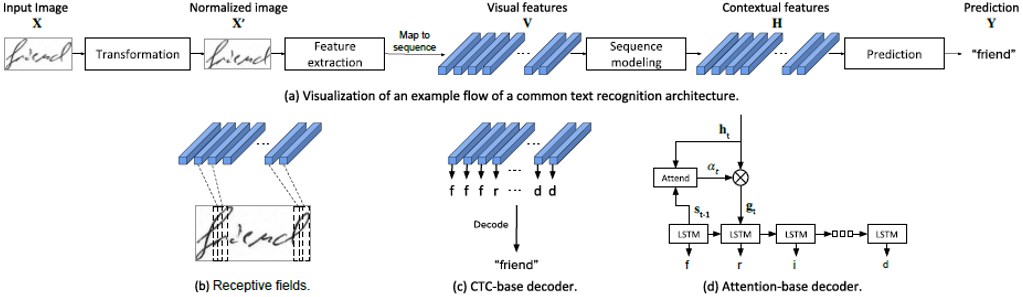
方法训练出编码器,然后为了评价该方法的性能,需要将编码器放入一般的文本识别方法中进行测试。如图
5
所示为通用的文本识别框架。
![]()
文本识别方法首先对输入图片进行变换,然后放入特征提取器、序列建模模块,最后进行预测,其中预测即解码过程,这里考虑两种解码方式,分别是CTC解码和Attention解码。
本文使用的数据集是手写英文数据集
IAM
[6]
、
CVL
[7]
,手写法文数据集
RIMES
[8]
,合成的场景文本数据集
SyntText
[9]
,真实世界场景文本数据集
IIT5K
[10]
、
IC03
[11]
、
IC13
[12]
。
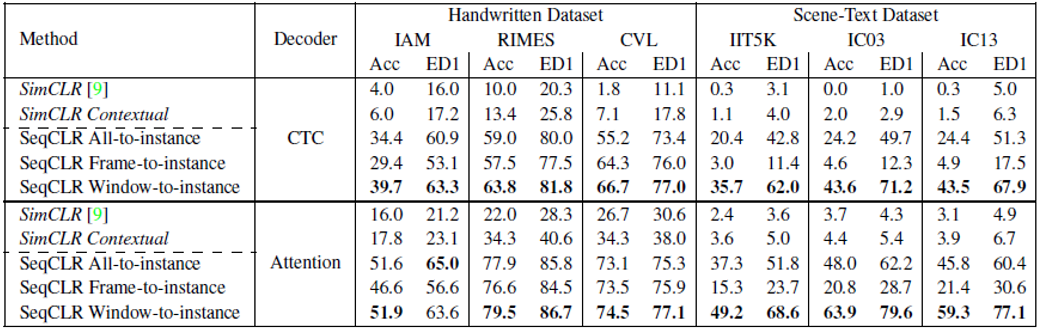
表1为不同模型的表示质量结果,其中SimCLR Contextual方法表示在SimCLR的编码器中加入序列化的表示,Acc表示单词级别准确率,ED1表示编辑距离。该实验将无监督方法训练出来的编码器作为文本识别框架中的编码器,然后对编码器部分进行冻结后训练,只更新预测模块。可以看到本文提出的方法在文本识别中更有效。
表1. 为不同模型的表示质量结果
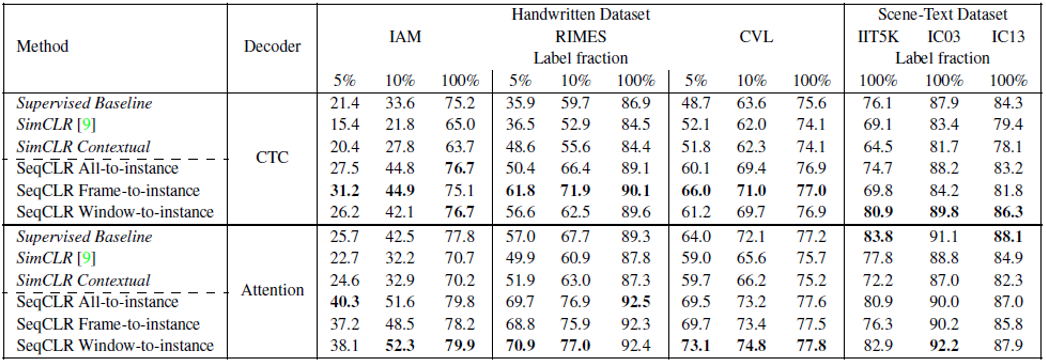
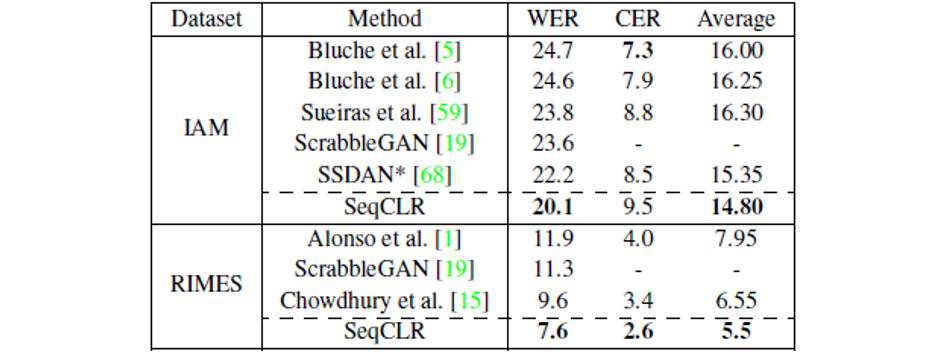
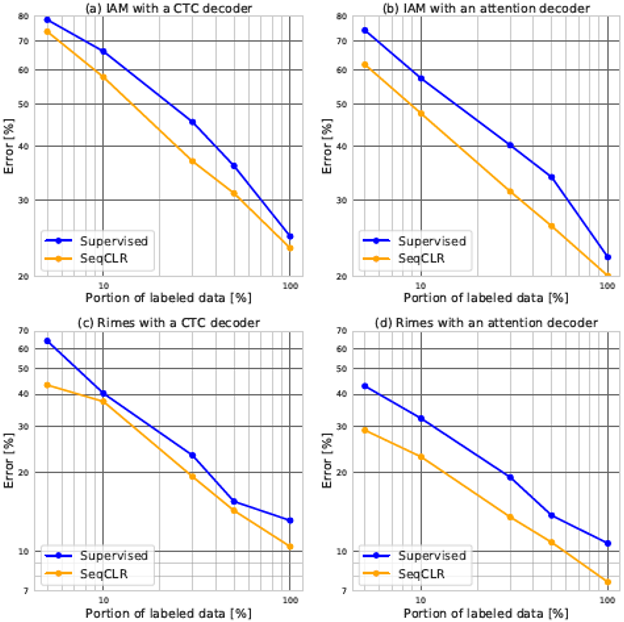
表2为半监督设置下的模型结果。这里的实验不再冻结任何模块,通过不同的数据量输入来测试模型的效果。其中输入100%的数据时,SeqCLR的方法在IAM和RIMES数据集上达到SOTA结果。表3为本文方法与其他模型在IAM和RIMES数据集上的错误率对比。图6为IAM和RIMES数据集上不同设置下有监督方法与SeqCLR方法的WER对比。
表2. 半监督结果
表3. IAM和RIMES数据集上的错误率对比
![]()
![]()
图6 不同设置下有监督方法与SeqCLR方法的WER对比
本文的方法是第一个提出用于文本识别的自我监督表示学习的工作。通过在特征图中加窗产生正负样本来将文本图片序列化,这种方法在一些手写文本和场景文本数据集中取得不错的效果。
https://www.amazon.science/publications/sequence-to-sequence-contrastive-learning-for-text-recognition
[1] Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607.
[2] He K, Fan H, Wu Y, et al. Momentum contrast for unsupervised visual representation learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9729-9738.
[3] Falcon W, Cho K. A framework for contrastive self-supervised learning and designing a new approach[J]. arXiv preprint arXiv:2009.00104, 2020.
[4] Caron M, Misra I, Mairal J, et al. Unsupervised learning of visual features by contrasting cluster assignments[J]. arXiv preprint arXiv:2006.09882, 2020.
[5] Oord A, Li Y, Vinyals O. Representation learning with contrastive predictive coding[J]. arXiv preprint arXiv:1807.03748, 2018.
[6] Marti U V, Bunke H. The IAM-database: an English sentence database for offline handwriting recognition[J]. International Journal on Document Analysis and Recognition, 2002, 5(1): 39-46.
[7] Kleber F, Fiel S, Diem M, et al. Cvl-database: An off-line database for writer retrieval, writer identification and word spotting[C]//2013 12th international conference on document analysis and recognition. IEEE, 2013: 560-564.
[8] Grosicki E, El Abed H. ICDAR 2009 handwriting recognition competition[C]//2009 10th International Conference on Document Analysis and Recognition. IEEE, 2009: 1398-1402.
[9] Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2315-2324.
[10] Mishra A, Alahari K, Jawahar C V. Scene text recognition using higher order language priors[C]//BMVC-British Machine Vision Conference. BMVA, 2012.
[11] Lucas S M, Panaretos A, Sosa L, et al. ICDAR 2003 robust reading competitions: entries, results, and future directions[J]. International Journal of Document Analysis and Recognition (IJDAR), 2005, 7(2-3): 105-122.
[12] Karatzas D, Shafait F, Uchida S, et al. ICDAR 2013 robust reading competition[C]//2013 12th International Conference on Document Analysis and Recognition. IEEE, 2013: 1484-1493.
原文作者
:
Aviad Aberdam*, Ron Litman*, Shahar Tsiper, Oron Anschel, Ron Slossberg, Shai Mazor, R. Manmatha, Pietro Perona
审校:连宙辉
发布:金连文
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
![]()
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源