[CVPR 2020]BEDSR-Net:单张文档图像的阴影去除深度网络

本文简要介绍CVPR 2020收录论文“BEDSR-Net: A Deep Shadow Removal Network from a Single Document Image”的主要工作,该论文针对移动设备拍摄的文档图像的去阴影任务提出了一种基于深度学习的SOTA解决方法。

移动设备(如手机)内置摄像头拍摄得到的文档图像上通常具有因物体遮挡以及不均匀光照造成的阴影,这种阴影严重影响了文档图像的可视化质量以及内容的可阅读性,同时也会影响后续的计算机视觉处理算法。目前关于去阴影的研究大都关注于自然场景,而关注于文档图像去阴影的研究又大都基于一些启发式手工设计的特征,这使得这些方法的鲁棒性和泛化性都不理想。
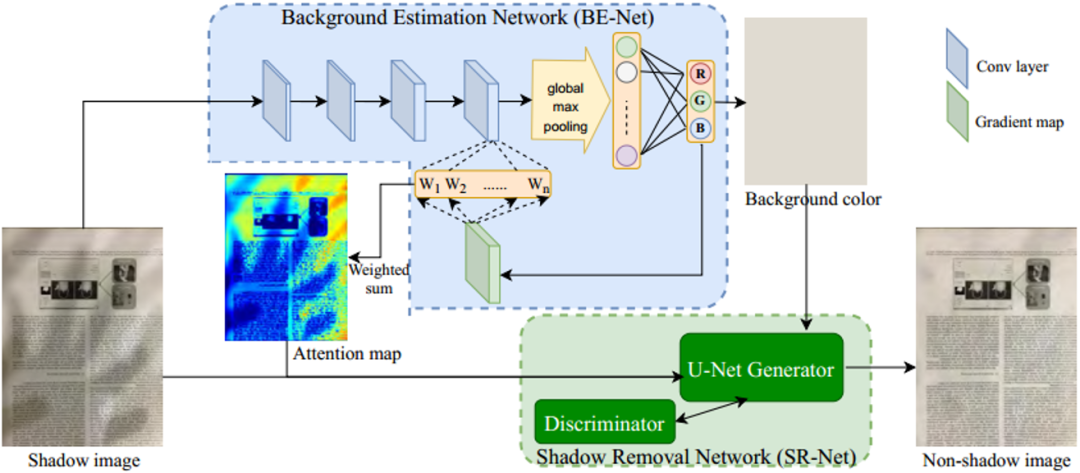
背景估计网络(Background Estimation Network, BE-net):背景估计网络以带有阴影的文档图像(Shadow Image)作为输入,经过几层卷积网络之后通过全局最大池化(Global Max Pooling)得到一维的特征向量(全局最大池化处理的好处是可以使得网络处理不同大小的输入),通过几层全连接之后,最后输出得到(R,G,B)三个值,并以此得到和输入的阴影文档图像具有相同尺寸的背景颜色图(Background Color)。其中(R,G,B)有相应的标签进行监督,损失函数采用L1损失。作者借鉴[1]中的思路,认为得到的背景颜色Background Color反映输入阴影文档图像纸张的颜色。同时,作者借鉴[2]中的方法,提取出输出(R,G,B)在最后一层卷积层输出中梯度,通过全局池化后得到一个一维的权重向量,利用这一权重向量将最后一层卷积层在通道方向上加权求和得到注意力热图(Attention Map),作者认为这个注意力热图(Attention Map)反映输入阴影文档图像(Shadow Image)上的阴影分布。
阴影去除网络(Shadow Removal Network,SR-net):阴影去除网络以带阴影的文档图像、BE-net输出的注意力热图(Attention Map)以及背景颜色图(Background Color)在通道方向上拼接在一起之后作为输入。通过一个U-net网络之后得到去掉阴影后的文档图(Non-shadow Image),去阴影图(Non-shadow Image)同样有响应标签进行监督,损失函数采用L1损失。此外,还通过一个判别器判断输出去阴影图(Non-shadow Image)的真实性,构成了一个GAN的网络,引入了GAN Loss。
数据集构建,作者分别构建了用于训练的合成数据集以及用于测试的真实数据集:
训练用合成数据:作者采集了970 张干净的文档图像(多数是直接从已有的公开数据集中采集的),然后通过Blender和Python脚本,在采集到的文档图像基础上添加阴影,并在此基础上得到Shadow Mask(本文方法不需要用到,主要用于对比其他方法)一共合成了8,309个训练样例。

测试用真实数据:作者先在良好的光照环境(光源均匀、无遮挡)下用相机拍摄得到无阴影图(Non-shadow Image),然后通过增加遮挡物来添加阴影,再次拍摄得到含有阴影的文档图像(Shadow Image),并以此为基础获得Shadow Mask。总共获得了540个测试样例。

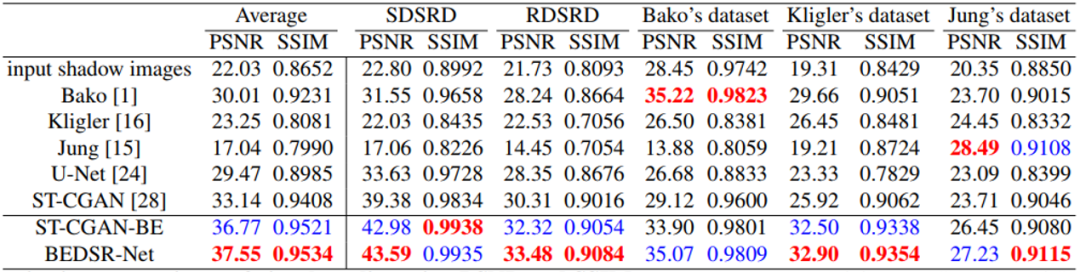



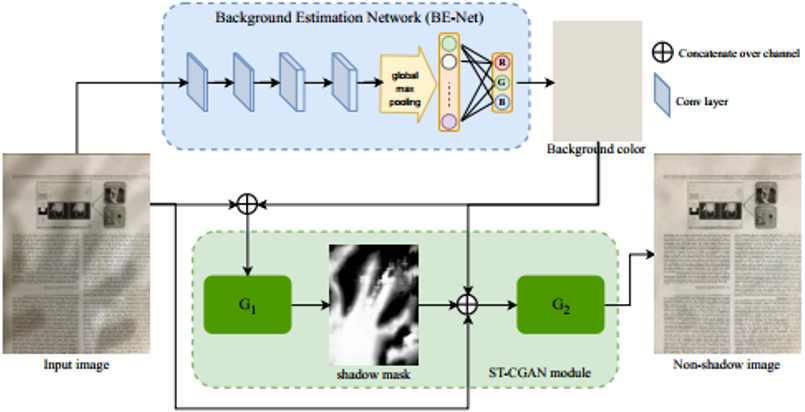
作者主要对比了文档图像去阴影的几个传统方法(Bako[1], Kligler[3],Jung[4]),以及一篇自然场景图像去阴影的深度学习方法ST-CGAN[5]。作者还将BE-net模块集成到ST-CGAN中,以此来证明其有效性,表示为ST-CGAN-BE,网络结构如图7所示。此外,U-net也作为Baseline加入了对比。定量指标的比较如表1所示,从表中ST-CGAN[5]和ST-CGAN-BE的比较可以看出BE-net模块的有效性,在增加了BE-net模块之后指标有了很大的提升。在大多数数据集上本文方法都取得了相比传统方法更好的结果。
从图5展示的可视化比较可以看出,本文提出的方法相比于其他方法都更接近于GT,而且ST-CGAN-BE相比于ST-CGAN在可视化质量上也有了很大的提升。图6是在真实数据上的测试结果,可以看出输出的背景颜色图(Background Color)和注意力热图(Attention Map)与作者前文的分析都是相符的。表2表示不同方法在OCR结果上与GT的OCR结果差别,数值越小表明越接近GT,可以看出本文方法与GT的OCR结果是最接近的。
本文针对拍摄文档图像去阴影问题提出了BEDSR-Net网络,该网络由背景估计网络(Background Estimation Network, BE-net)以及阴影去除网络(Shadow Removal Network, SR-net)这两个子网络构成,BE-net以阴影文档图作为输入,预测输出该文档图的纸张颜色(R,G,B)三个值,以及反映阴影分布情况的注意力热图(Attention Map)。将这两个输出与原始的阴影文档图一起输入给SR-net(包含判别器,引用了GAN Loss),最终输出得到阴影去除后的文档图像。
作者还利用Blender+python脚本的方式合成了一个包含8309个样例的数据集,每个样例都包含文档背景颜色、阴影图文档图、去掉阴影的文档图以及Shadow Mask。以及提出了一个包含540个真实样例的测试集。
定量和定性比较都证明了本文方法的有效性以及优越性,超过了目前SOTA的方法,通过将BE-net整合到ST-CGAN上也很好的证明BE-net的有效性。
代码和数据都将开源。
不足之处:对于没有统一纸张背景的文档图像不能很好处理、对于阴影布满整个文档区域的情况不能很好处理、对于多光源多阴影的复杂情况不能很好处理。
-
BEDSR-Net论文地址:
[1] Bako, S.,Darabi, S., Shechtman, E., Wang, J., Sunkavalli, K., & Sen, P. (2016,November). Removing shadows from images of documents. In Asian Conference on Computer Vision (pp. 173-183). Springer, Cham.
[2] Selvaraju, R. R., Cogswell, M., Das,A., Vedantam, R., Parikh, D., & Batra, D. (2017). Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision (pp. 618-626).
[3] Kligler, N., Katz, S., & Tal, A.(2018). Document enhancement using visibility detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2374-2382).
[4] Jung, S., Hasan,M. A., & Kim, C. (2018, December). Water-filling: An efficient algorithm for digitized document shadow removal. In Asian Conference on Computer Vision (pp. 398-414). Springer, Cham.
[5] Wang, J., Li,X., & Yang, J. (2018). Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp.1788-1797).
原文作者:Yun-Hsuan, Lin. Wen-Chin, Chen. Yung-Yu, Chuang*
审校:殷 飞
发布:金连文
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“BEDSR” 可以获取《[CVPR 2020]BEDSR-Net:单张文档图像的阴影去除深度网络》专知下载链接索引





