CVPR 2019:微软最新提出ObjGAN,输入一句话秒生成图片

新智元报道
新智元报道
来源:microsoft
编辑:金磊
【新智元导读】微软和京东最近出了一个黑科技:说一句话就能生成图片!在这项研究中,研究人员提出了一种新的机器学习框架——ObjGAN,可以通过关注文本描述中最相关的单词和预先生成的语义布局(semantic layout)来合成显著对象。
不会PS还想做图?可以的!
近期,由纽约州立大学奥尔巴尼分校、微软研究院和京东AI研究院合作的一篇文章就可以实现这个需求:只需要输入一句话,就可以生成图片!
输入:
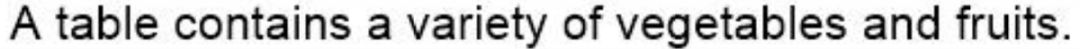
输出:

在这项研究中,研究人员提出了一种新的机器学习框架——ObjGAN,可以通过关注文本描述中最相关的单词和预先生成的语义布局(semantic layout)来合成显著对象。
此外,他们还提出了一种新的基于Fast R-CNN的关于对象(object-wise)鉴别器,用来提供关于合成对象是否与文本描述和预先生成的布局匹配的对象识别信号。

论文地址:
https://www.microsoft.com/en-us/research/uploads/prod/2019/06/1902.10740.pdf
这项工作已经发表在计算机视觉和模式识别领域顶会CVPR 2019。
这篇论文的合著作者表示,与之前最先进的技术相比,他们的方法大大提高了图像质量:
我们的生成器能够利用细粒度的单词和对象级(object-level)信息逐步细化合成图像。
大量的实验证明了ObjGAN在复杂场景的文本到图像生成方面的有效性和泛化能力。
根据文本的描述来生成图像,可以说是机器学习中一项非常重要的任务。
这项任务需要处理自然语言描述中模糊和不完整的信息,并且还需要跨视觉和语言模式来进行学习。
自从GAN提出后,这项任务在结果上取得了较好的成绩,但是目前这些基于GAN的方法有一个缺点:
大多数图像合成方法都是基于全局句子向量来合成图像,而全局句子向量可能会丢失单词级别(word-level)的重要细粒度信息,从而阻碍高质量图像的生成。
大多数方法都没有在图像中明确地建模对象及其关系,因此难以生成复杂的场景。
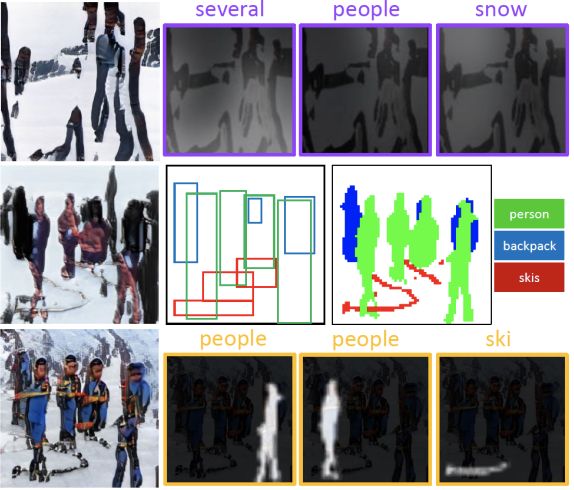
图1 顶部:AttnGAN及其网格注意力可视化;中部:修改前人工作的结果;底部:ObjGAN及其对象驱动的注意力可视化
举个例子,如果要根据“几个人穿滑雪服的人在雪地里”这句话生成一张图片,那么需要对不同的对象(人、滑雪服)及其交互(穿滑雪服的人)进行建模,还需要填充缺失的信息(例如背景中的岩石)。
图1的第一行是由AttnGAN生成的图像,虽然图像中包含了人和雪的纹理,但是人的形状是扭曲的,图像布局在语义上是没有意义的。
为了解决这个问题,首先从文本构造语义布局,然后通过反卷积图像生成器合成图像。
从图1的中间一行可知,虽然细粒度的word/objectlevel信息仍然没有很好的用于生成。因此,合成的图像没有包含足够的细节让它们看起来更加真实。
本研究的目标就是生成具有语义意义(semantically meaningful)的布局和现实对象的高质量复杂图像。
为此,研究人员提出了一种新颖的对象驱动的注意力生成对抗网络(Object-driven Attentive Generative Adversarial Networks,Obj-GAN),该网络能够有效地捕获和利用细粒度的word/objectlevel信息进行文本到图像的合成。
ObjGAN由一对儿对象驱动的注意力图像生成器和object-wise判别器组成,并采用了一种新的对象驱动注意机制。
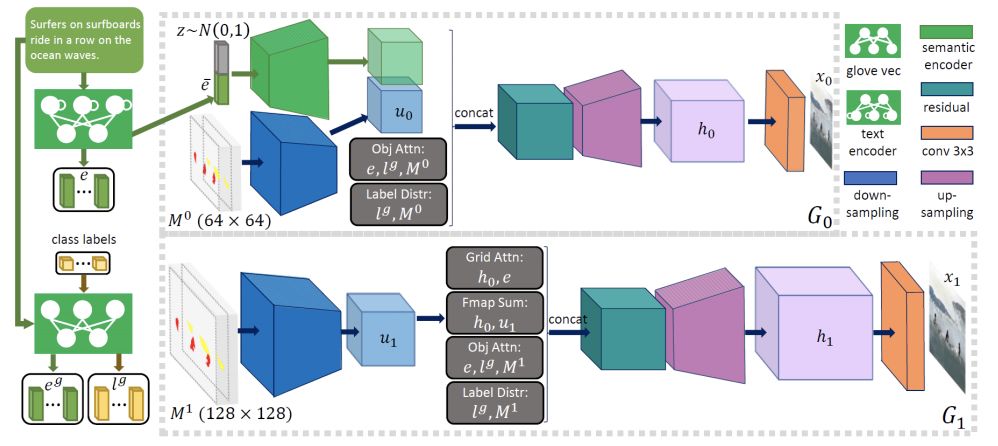
图2 对象驱动的注意力图像生成器
图3 Object-wise判别器
该图像生成器以文本描述和预先生成的语义布局为输入,通过多阶段由粗到精的过程合成高分辨率图像。
在每个阶段,生成器通过关注与该边界框中的对象最相关的单词来合成边界框内的图像区域,如图1的底部行所示。
更具体地说,它使用一个新的对象驱动的注意层,使用类标签查询句子中的单词,形成一个单词上下文向量,如图4所示,然后根据类标签和单词上下文向量条件合成图像区域。
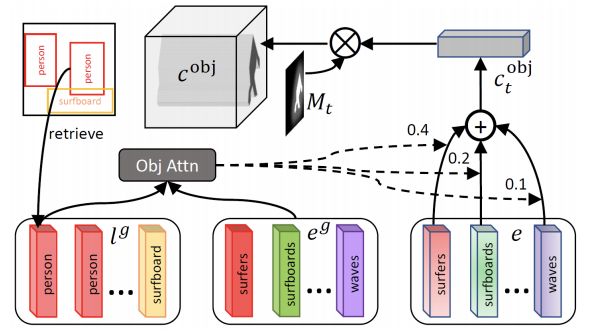
图4 对象驱动的注意力
Object-wise判别器会对每个边界框进行检查,确保生成的对象确实与预先生成的语义布局是匹配的。
同时,为了有效地计算所有边界框的识别损失,object-wise判别器基于一个Fast-RNN,并且每个边界框都有一个二院交叉熵损失。
研究人员在实验过程中采用的数据集是COCO数据集。它包含80个对象类,其中每个图像与对象注释(即,边界框和形状)和5个文本描述相关联。
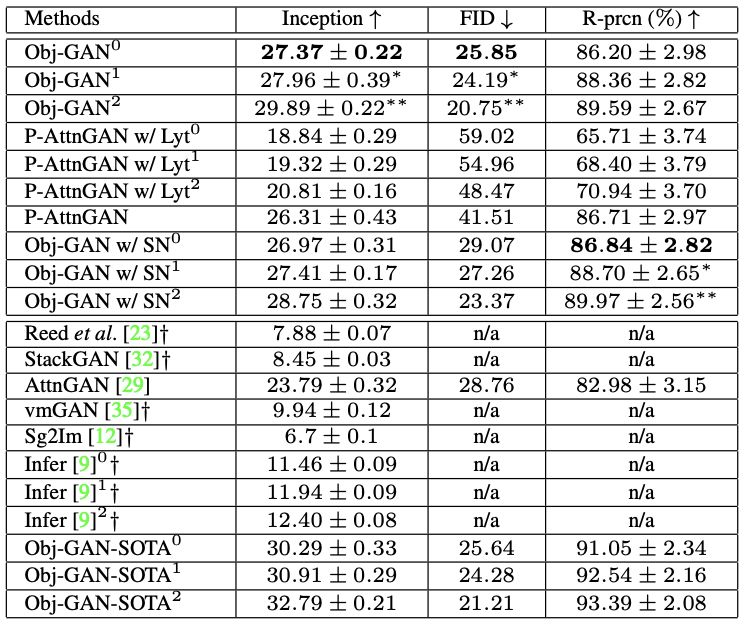
在评价指标方面,研究人员采用 Inception score(IS)和Frechet Inception distance(FID) score作为定量评价指标。结果如下表所示:
表1
接下来,是采用不同方法生成图像的结果与实际图像的对比结果:


图5 整体定性比较。所有图像都是在不使用任何ground-truth的情况下生成的。

图6 与P-AttnGAN w/ Lyt进行定性比较

图7 与P-AttnGAN的定性比较。 每个方法的注意力图显示在生成的图像旁边。
参考链接:
论文地址:
https://www.microsoft.com/en-us/research/uploads/prod/2019/06/1902.10740.pdf
VB博客地址:
https://venturebeat.com/2019/06/17/microsoft-researchers-use-gans-to-generate-images-and-storyboards-from-captions/





