学界 | 海康威视联合提出注意力聚焦网络FAN:提升场景文本识别精确度
选自arXiv
机器之心编译
参与:路雪、黄小天
鉴于目前注意力机制方法在场景文本识别中表现欠佳,近日,海康威视、复旦大学与上海交通大学等在 arXiv 上联合发表了一篇题为《Focusing Attention: Towards Accurate Text Recognition in Natural Images》的论文,其中提出了一种称为注意力聚焦网络(FAN)的新方法,可有效对齐注意力与图像中的目标区域,调整偏移注意力,成功解决了注意力漂移问题,从而显著提升场景文本识别精确度。在不同基准(包括 IIIT5k、SVT 和 ICDAR 数据集)上进行的大量实验表明 FAN 方法明显优于现有方法。
场景文本识别(Scene text recognition)已引起计算机视觉领域人士的很大兴趣。识别场景文本对场景理解意义重大。尽管光学字符识别(OCR)的研究已经进行了数十年,但是识别自然图像中的文本仍然是一个挑战。顶尖技术通过注意力机制识别字符,取得了显著的性能提升。
通常情况下,基于注意力的文本识别器是编码器-解码器框架。在编码阶段,图像通过 CNN/LSTM 转换成特征向量序列,每个特征向量对应输入图像上的一个区域。本文中,我们将这类区域称作注意力区域。在解码阶段,注意力网络(AN)首先通过参照目标字符的历史和用于生成合成向量(又叫 glimpse 向量)的编码特征向量计算对齐因子,这种方式可以使注意力区域与对应的真值标签对齐。然后,使用循环神经网络(RNN)根据 glimpse 向量和目标字符历史生成目标字符。

图 1. 复杂/低质量图像的实例。子图像 (a) 至 (f) 分别代表正常、复杂背景、模糊、不完整、字符大小不同和字体不正常的图像。
动机。我们都知道真实的场景文本识别任务中存在很多复杂图像(比如扭曲或重叠的字符,不同字体、大小、颜色的字符,以及复杂背景图像等)或低质量图像。图 1 展示了复杂/低质量图像的实例。对于这类图像,现有的基于注意力的方法通常表现不佳。我们在真实数据上仔细分析了基于注意力方法的很多中间结果和最终结果,发现表现不佳的一个主要原因是注意力模型评估的对齐很容易因为图像的复杂性和/或低质量而受到损坏。换言之,注意力模型无法将每一个特征向量和输入图像中对应的目标区域准确对齐。我们将这种现象叫作注意力漂移(attention drift),即 AN 的注意力区域一定程度上偏离图像中目标字符的确切位置。这促使我们开发一种机制,调整 AN 的注意力,使之集中在输入图像中目标字符的正确位置。
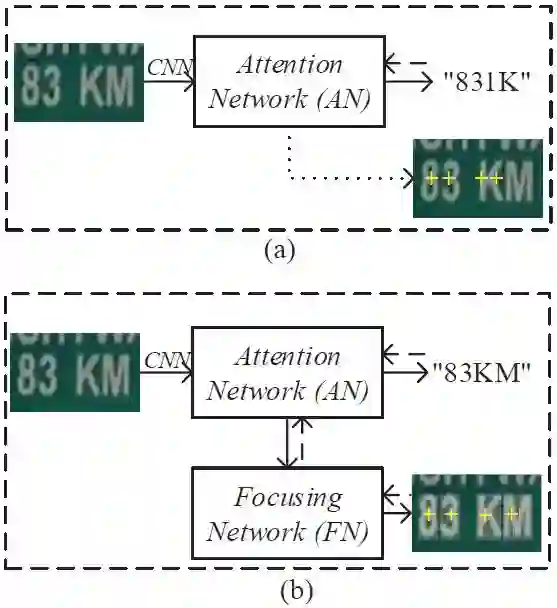
图 2. AN 模型中的注意力漂移和 FAN 方法中的聚焦机制(focusing mechanism)。
在子图像(a)中,带有文本「83KM」的真实图像作为输入,并输出「831K」。最后两个字符「K」和「M」没有识别出,因为 AN 的这两个字符的注意力区域与图像中的位置偏离太多。在子图像(b)中,在 FN 模块的帮助下,最后两个字符的 AN 注意力中心得到调整,与字符的位置恰好对齐,使得 FAN 输出正确的文本字符串「83KM」。这里,虚线箭头和黄色的「+」分别代表注意力区域的计算和中心;图像右下角的白色矩形掩模代表字符的真值区域。
图 2(a)描述了 AN 模型中的注意力漂移现象。输入左侧图像之后,我们期待 AN 模型可以输出文本串「83KM」,但是它输出的是「831K」。注意,这不是一个虚构案例,它是从我们的实验中选出来的真实案例。在实践中,还有很多这样的案例。很明显,最后两个字符「K」和「M」没有得到准确识别。为什么?通过对图像中四个字符的注意力区域进行计算,我们得到了它们的注意力中心,即右下角原始图像中的黄色「+」。我们可以看到「8」和「3」的注意力中心就在它们上方,而第三个注意力中心覆盖在「K」的左半边,第四个注意力区域覆盖「K」的右半边。由于「K」的左半边看起来像「1」,AN 模型输出了「1」。第四个注意力区域覆盖了「K」的大部分,所以 AN 模型输出了「K」。
我们的工作。为了解决以上问题,本文我们提出了一种新方法 FAN(Focusing Attention Network)来准确识别自然图像中的文本。图 2(b)展示了 FAN 方法的架构。FAN 由两个主要子网络构成:用于识别目标字符的注意力网络(与现有方法一样);聚焦网络(focusing network/FN),首先检测 AN 的注意力区域是否与图像中目标字符的确切位置准确对齐,然后自动调整 AN 的注意力中心。在图 2(b)中,使用 FN 模块后,最后两个字符的 AN 注意力区域得到调整,FAN 输出了正确的文本字符串「83KM」。
本论文的贡献有:
1)我们提出注意力漂移的概念,解释了现有注意力方法在复杂/低质量自然图像上性能较差的原因。
2)我们开发了一种 FAN 新方法来解决注意力漂移问题,这种方法在大多数现有方法都有的注意力模块之外,还引入了一个全新的模块——聚焦网络(FN),该网络可以使 AN 偏离的注意力重新聚焦在目标区域上。
3)我们采用强大的基于 ResNet 的卷积神经网络,以丰富场景文本图像的深度表征。
4)我们在多个基准上实施大量实验,展示了我们的方法与现有方法相比的性能优越性。
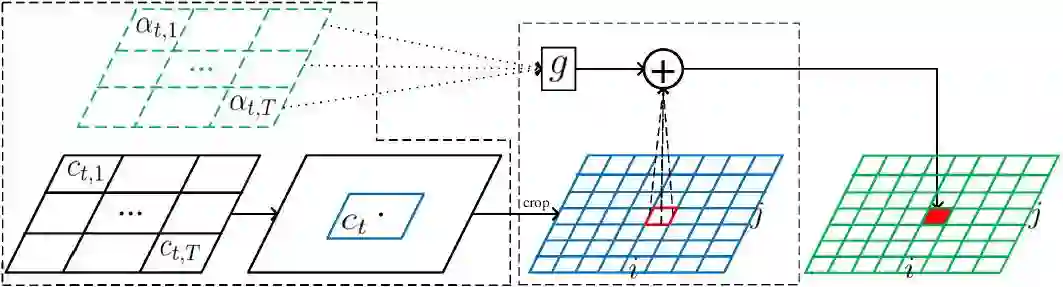
图 3. FAN 的注意力机制。
这里,α、c、g 和+分别代表对齐因子、输入图像中每个特征的中心、glimpse 向量和聚焦操作。蓝色网格和绿色网格分别代表每个像素的裁剪特征和预测结果。为了预测第 t 个目标,我们首先为每个由 CNN-LSTM 获得的特征向量 h_j 评估中心位置 c_t,j,并计算所有中心的总权重获取权重位置 c_t,然后从输入图像或卷积输出中裁剪一组特征,针对注意力区域进行聚焦操作。
论文:Focusing Attention: Towards Accurate Text Recognition in Natural Images

论文链接:https://arxiv.org/abs/1709.02054
摘要:
由于应用范围广泛,场景文本识别一直是计算机视觉中的热门研究领域。目前最先进的技术是基于注意力机制的编码器-解码器框架,该技术以纯数据驱动的方式学习输入图像和输出序列的映射关系。然而,我们发现目前基于注意力机制的方法在复杂和低质量图像中表现不佳。其主要原因是现有的方法无法获取特征区域和目标字符的准确对齐。我们称之为「注意力漂移」。为了解决该问题,我们提出了 FAN 方法,该方法使用聚焦注意力机制来自动拉回漂移的注意力。FAN 包括两个主要模块:用于识别目标字符的注意力网络(与现有方法一样);聚焦网络(FN),评估 AN 的注意力是否与图像中的目标区域对齐,然后调整偏离的注意力。此外,与现有方法不同,我们还采用了基于 ResNet 的网络来丰富场景文本图像的深度表征。在不同基准(包括 IIIT5k、SVT 和 ICDAR 数据集)上进行的大量实验表明 FAN 方法明显优于现有方法。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


