

一、研究背景****
场景文字编辑旨在修改场景文字图像上的文本内容,同时保持文字和背景的风格和纹理不变。以Wu et al. [1]和Qu et al. [2]为代表的早期方法利用生成对抗网络(GANs)将场景文字编辑任务拆分为前景文本风格迁移、背景恢复和融合三个子任务。然而,由于GANs模型的容量受限,这类方法的泛化能力往往有限,并且分治的设计容易导致背景恢复质量不稳定带来混乱的融合伪影。相对而言,近期基于扩散模型的方法显示出强大的图像合成和处理能力。Chen et al. [3]和Tuo et al. [4] 等工作尝试通过Inpainting方法基于整图实现场景文字编辑,然而其风格样式信息主要来源于图像的未遮蔽区域,这在现实场景中可能出现风格样式不一致的情况。此外,由于文本提示和字形结构之间的弱相关性,基于扩散模型的方法容易生成错误字符而降低文本编辑的准确性。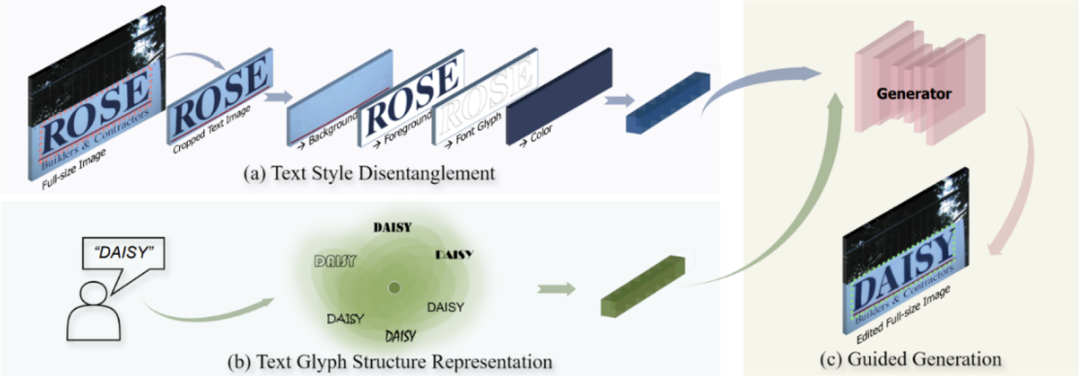
1. Glyph Structure Representation:字形表征
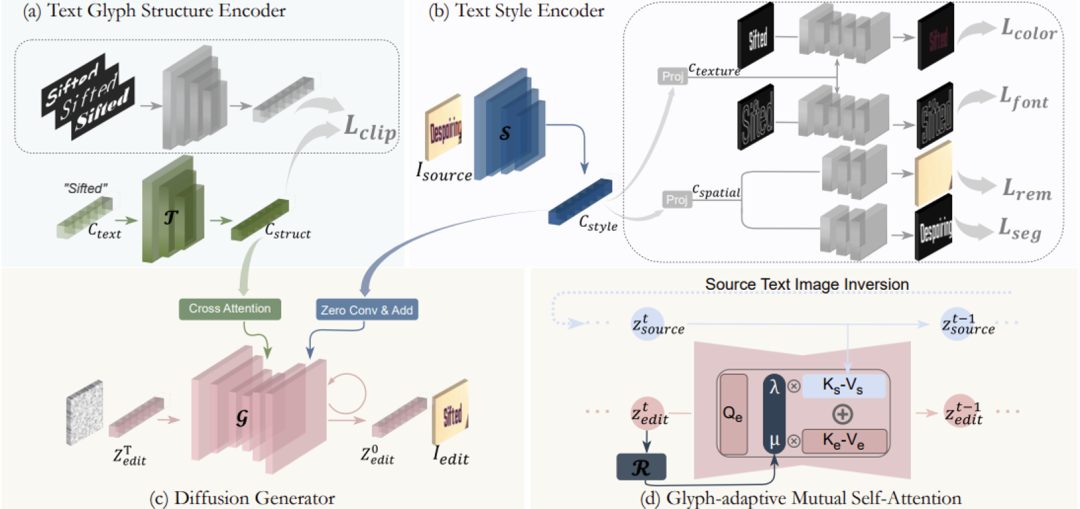
与自然物体不同,文字具有复杂的几何结构,即使是微小的笔画差异也会显著改变视觉感知并带来误解,因此对文字编辑准确性提出了独特的挑战。受Zhao et al. [5]启发,该论文采用了一个字符级别的文本编码器,将目标文本特征与其视觉字形结构对齐,并在此基础上引入随机字体增强策略,以摆脱模板偏置从而捕获更鲁棒的字形表征。如图2(a)所示,在字形表征预训练中,文本嵌入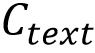
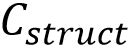
2. Text Style Disentanglement:风格解耦
文本风格样式包括字体、颜色、空间变换和立体效果等多方面,它们在视觉上相互杂糅,为模型提取风格特征带来了障碍。为了实现文本风格的细粒度解耦,该论文提出了一种针对文本风格的多任务预训练范式,如图2(b)所示,其中包括颜色迁移、字体迁移、文本擦除和文本分割。具体来说,在风格解耦预训练中,风格编码器S将输入图像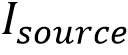
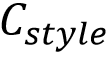
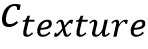
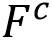
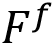
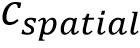
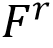
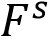

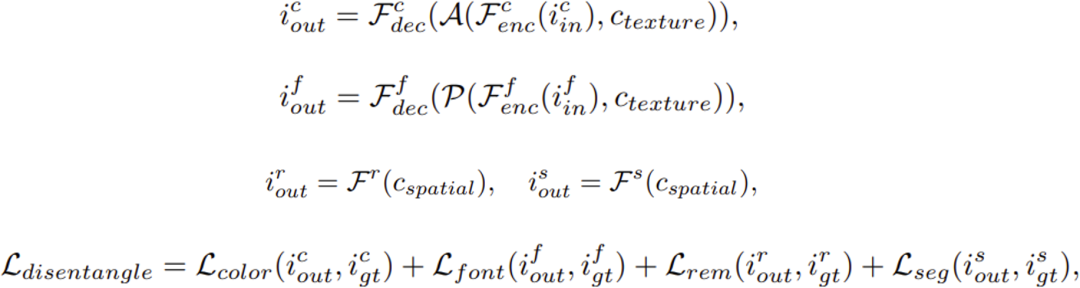
3. Prior Guided Generation:引导生成
通过上述预训练编码器得到字形表示 和风格特征
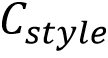
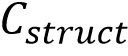
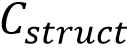
,论文参考Zhang et al. [6]范式将多尺度风格特
4. Inference Control:推理控制
在现实场景的推理过程中,场景文字编辑往往会出现颜色偏差和纹理退化,这种风格不一致的现象主要归因于去噪过程中的误差积累以及训练推理之间的域差异。为了进一步控制视觉风格质量,该论文尝试通过将源图像中的风格先验注入编辑过程中来改善生成结果。受Cao et al. [7]启发,该论文提出了字形自适应的互注意力机制(Glyph-adaptive Mutual Self-attention)实现源图像风格特征的整合。如图2(d)所示,模型设立了源图像重建分支,首先通过DDIM Inversion [8]方法确定一个初始向量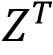
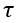
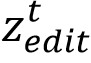
进行余弦相似度计算表示当前编辑图像字形完成度并作为强度参数
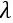

三、ScenePair数据集****
图 3 ScenePair数据集的观察与收集流程 场景文字编辑任务缺乏真实数据集进行评测是一个不容忽视的问题。早期评测主要依赖于合成数据,这与实际应用中存在显著的差异。近期评测采用了真实图像,但由于缺乏配对的编辑图像,只能用于测试渲染准确性,无法充分评估视觉质量。ScenePair数据集的构建灵感来自于这样的观察:在现实世界场景中,场景文本常常组合出现在具有相同风格和背景的招牌短语中,如图3(a)所示,它们可以被收集作为评估编辑质量的配对样本。值得注意的是,图像编辑不存在完全“正确”的结果,但所收集的配对数据可作为风格质量的一种参考基准。 如图3(b)所示,论文设计了一种半自动采集方式,通过现有的场景文字数据集及标注,对每张整图裁剪出各个文本框图片,根据文本框图片间的文本长度、长宽比、距离和结构相似性等指标计算整体相似度,设置阈值进行收集并人工过滤,最终得到1280个文本框图像对作为评测数据集如图4所示。

表 1 场景文字编辑方法的编辑风格一致性对比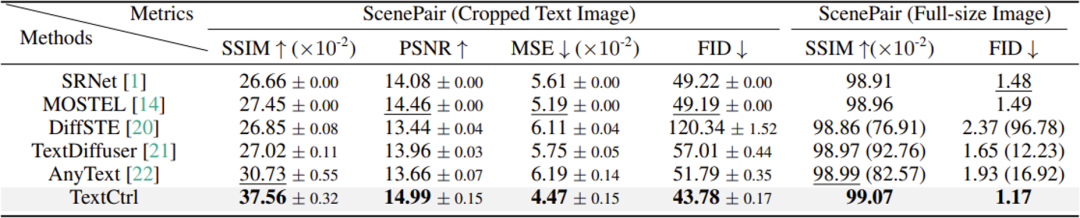
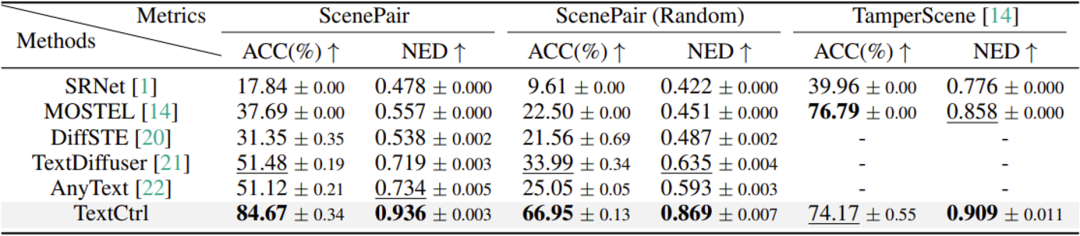
实验中,该论文对比了基于GANs的场景文字编辑方法SRNet[1]和MOSTEL[2]以及基于扩散模型的DiffSTE[9],TextDiffuser[3]和AnyText[4]。对于编辑风格一致性,实验采用了结构相似性SSIM,峰值信噪比PSNR,均方误差MSE以及FID分数作为评测指标,分别在ScenePair数据集的文本框级别和整图级别进行性能评测,表1的结果显示出该论文方法在局部文字风格一致性以及整图和谐程度的优势。值得注意的是,基于GANs的方法[1,2]尽管指标不俗,但图5的定性对比反映出其编辑结果往往由于背景恢复模块的不稳定性而呈现出较多的伪影。基于扩散模型的方法[3,4,9]由于采用对遮蔽图像Inpainting的策略,其风格信息主要来源于文本框周围区域,这给字体风格一致性带来了不确定性,如图6所示。对于渲染字符准确率,实验采用了字段准确率ACC和标准编辑距离NED作为评测指标,分别在ScenePair数据集和TamperScene[2]数据集上进行评测。由于该论文方法聚焦于文本框图像级别的编辑,这给模型在不同尺寸上的文字编辑带来优势,而其余基于扩散模型方法[3,4,9]由于模型输入尺寸的限制,无法完成小文字编辑,从而带来渲染准确率的明显差异。

此外论文中展示了现实场景推理时字形自适应的互注意力机制带来的风格先验增强效果,如图7所示。由于文字编辑预训练和训练依赖于生成数据,这种域差异往往会导致面对现实场景时模型的文字风格捕获能力的有限,通过引入源图像的并行重建分支和互注意力机制,模型能对图像中的背景纹理,字体风格和字形结构有更好的一致性控制。
针对场景文字编辑任务,该论文聚焦于文本图像区域,提出了一种基于扩散模型的方法 TextCtrl。该方法利用显式解耦的风格特征和字形结构引导来实现文本编辑。为了在推理过程中增强风格一致性,论文中提出了字形自适应的互注意力机制以及并行采样过程。此外,该论文收集了一个图像对数据集ScenePair,以助于实现真实场景下包括风格一致性和渲染准确率的双重评估,为后续在场景文字编辑领域的研究提供有力的支持。论文最后关注到了方法存在的一些局限性。首先,对于任意形状文本的编辑(如弯曲文本),论文方法无法提供精准的排版控制,这主要是源于缺乏显式排版位置信息。注意到早期基于GANs的方法可以通过薄板样条插值(TPS)的方式对模板文字图像进行形状控制,如何在扩散模型中引入这样的先验信息值得进一步探索。此外,论文实验对于编辑风格一致性的评测选取了若干常用图像编辑指标,然而这些指标主要关注于像素或特征空间的差异,而对于文字编辑任务,一个更聚焦于字体字形相似性的量化指标亟待构建。 六、相关资源****
论文链接:https://arxiv.org/pdf/2410.10133代码即将开源:https://github.com/weichaozeng/TextCtrl 参考文献****
[1] Liang Wu, Chengquan Zhang, Jiaming Liu, Junyu Han, Jingtuo Liu, Errui Ding, and Xiang Bai. Editing Text in the Wild. In Proceedings of the ACM International Conference on Multimedia, 2019. [2] Yadong Qu, Qingfeng Tan, Hongtao Xie, Jianjun Xu, Yuxin Wang, and Yongdong Zhang. Exploring Stroke-Level Modifications for Scene Text Editing. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 2119–2127, 2023. [3] Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, and Furu Wei. TextDiffuser: Diffusion Models as Text Painters. Advances in Neural Information Processing Systems, 36, 2024. [4] Yuxiang Tuo, Wangmeng Xiang, Jun-Yan He, Yifeng Geng, and Xuansong Xie. AnyText: Multilingual Visual Text Generation And Editing. In Proceedings of the International Conference on Learning Representations, 2024. [5] Yiming Zhao and Zhouhui Lian. UDiffText: A Unified Framework for High-quality Text Synthesis in Arbitrary Images via Character-aware Diffusion Models. arXiv preprint arXiv:2312.04884, 2023. [6] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding Conditional Control to Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3813–3824, 2023. [7] Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22560–22570, 2023. [8] Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text Inversion for Editing Real Images using Guided Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6038–6047, 2023.[9] Jiabao Ji, Guanhua Zhang, Zhaowen Wang, Bairu Hou, Zhifei Zhang, Brian L Price, and Shiyu Chang. Improving Diffusion Models for Scene Text Editing with Dual Encoders. Transactions on Machine Learning Research, 2023.
原文作者:Weichao Zeng, Yan Shu, Zhenhang Li, Dongbao Yang, Yu Zhou
