Keras新增TextVectorization层,可直接将文本字符串作为模型输入
【导读】Keras作者François Chollet在Twitter上展示了Keras的一个新特性—TextVectorization层。借助该特性,我们可以构建包含文本预处理功能且可直接以字符串作为输入的Keras模型。
在构建NLP深度模型时,我们一般会使用额外的代码对文本进行预处理,将其处理为能够作为深度网络输入的数值型Tensor。虽然对于科研人员来说这并不是什么太大的问题,但对于工程人员来说这是一个较为棘手的问题。在实际工程中,很多情况下我们需要用TensorFlow和Keras等框架生成可被C++ SDK或TensorFlow Serving等调用的模型。并不是整个深度学习流程都可以被保存到这个模型中,尤其是一些用Python写的文本、图像等预处理操作。往往,只有那些与Tensor计算相关的常量、操作等才能被保存到模型中,工程师需要用使用模型的语言(C++、Swift等)重新实现数据预处理等操作。
NLP任务中,将文本预处理问数值Tensor是非常繁琐的过程,你需要额外保存词表、编写转换代码等。工程师需要花费大量的时间精力来理解算法工程师的文本预处理逻辑,才能够准确复现他们的文本预处理流程。
Keras新增的TextVectorization层可以完成文本预处理的逻辑(标准化、词语切分和单词索引),更重要的是,它是可以被序列化和部署的,也就是说,算法工程师可以直接在模型中封装文本预处理的逻辑,而不需要工程师额外的实现。
Keras作者François Chollet在Twitter上展示了该特性:
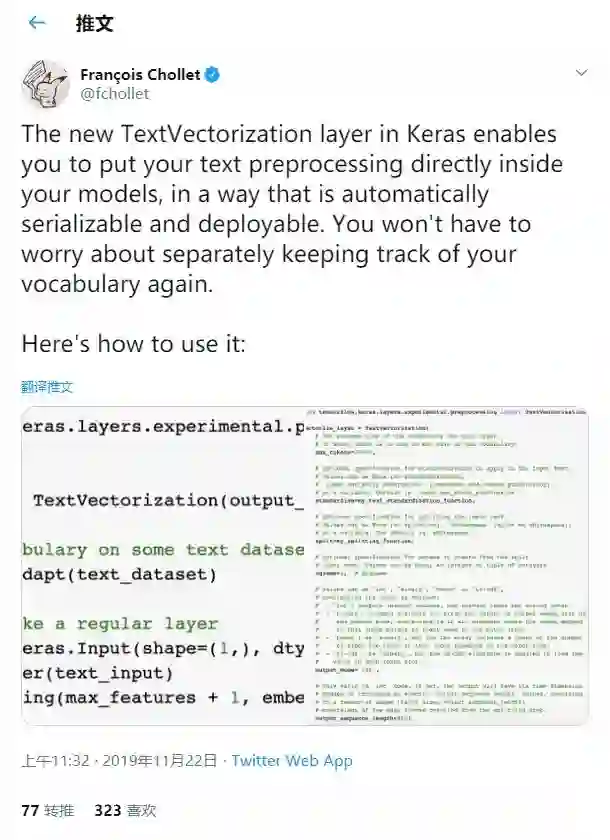


下面是示例代码链接:
https://colab.research.google.com/drive/1RvCnR7h0_l4Ekn5vINWToI9TNJdpUZB3



登录查看更多
相关内容

Arxiv
6+阅读 · 2019年7月17日
Arxiv
3+阅读 · 2018年1月23日




相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2019年7月17日
Arxiv
3+阅读 · 2018年1月23日