元学习—Meta Learning的兴起
【导读】元学习描述了训练深度神经网络相关的更高级别的元素。在深度学习文献中,“元学习”一词经常表示神经网络架构的自动化设计,经常引用“ AutoML”,“少量学习”或“神经架构搜索”。OpenAI的魔方机器人手的成功源于诸如“通过梯度下降学习如何通过梯度下降学习”之类的可笑标题的论文,证明了该想法的成熟。元学习是推动深度学习和人工智能技术发展的最有希望的范例。
OpenAI通过展示经过强化学习训练的机器人手的突破性功能,使AI世界变得火热了。该成功基于2018年7月提出的一项非常类似的研究,该研究要求机械手将块定位在与视觉提示匹配的配置中。元数据学习算法控制模拟中的训练数据分布,即自动域随机化(ADR),从而推动了从块定向到解决魔方的演变。

域随机化—数据增强
域随机化是一种用于解决Sim2Real传输的数据扩充问题的算法。函数逼近(和深度学习)的核心功能是将其从训练中学到的知识推广到前所未有的测试数据。深度卷积神经网络在进行模拟图像训练(显左下方图)到真实视觉数据(右下方图)时,无需进行特殊修改就不会泛化。

当然,有两种方法可以使模拟数据分布与实际数据分布保持一致。苹果研究人员开发的一种这样的方法称为SimGAN。SimGAN使用对抗损失来训练生成对抗网络的生成器,以使模拟图像看起来尽可能逼真,而鉴别器则将图像归类为真实或模拟数据集。该研究报告在眼睛注视估计和手势姿势估计方面取得了积极成果。另一种方法是使模拟数据尽可能多样化,而与真实性相反。
后一种方法称为域随机化。下图来自Tobin等人在2017年的论文中很好地说明了这一想法:

域随机化似乎是弥合Sim2Real差距的关键,在进行模拟训练时,允许深度神经网络将其推广到真实数据。与大多数算法不同,域随机化带有许多要调整的参数。下图显示了块的颜色,环境的光照和阴影的大小的随机性,仅举几例。这些随机环境特征中的每一个都具有一个从下到上的区间以及某种采样分布。例如,在对随机环境进行采样时,该环境具有非常明亮的照明的概率是多少?
在OpenAI 最初的研究中,使用机械手实现了块定位,在实验之前,对域随机数据课程进行了手动编码。这种域随机化超越了视觉世界,使物理模拟器中的组件随机化,从而产生了使机械手能够灵活灵巧地移动的策略。与视觉随机化的想法类似,这些物理随机化包括诸如立方体的大小/质量和手指在机器人手中的摩擦之类的尺寸。
从Dactyl到Rubik's Cube解算器的关键是,定义随机化的强度是自动的,而不是手动设计的,这在ADR算法的以下几行中明确定义:
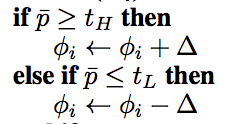
设计自己的数据的AI
由Uber AI Labs的研究人员开发的配对开放式开拓者(POET)算法是设计自己的数据的AI最好的例子之一。
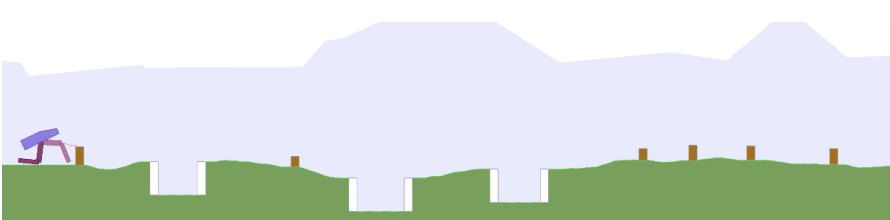
POET通过同时优化代理和步行学习环境来训练双足步行代理。POET与OpenAI的rubik多维数据集求解器不同,它使用进化算法来维护步行者和环境。具有主体和环境的种群的结构是构建本研究复杂性演变的关键。尽管与使用基于群体的学习来适应一组智能体相比,使用强化学习来训练单个智能体,但是POET和自动域随机化非常相似。他们都以自动化的方式开发了挑战性不断增长的训练数据集。Bipedal的步行环境不会作为手动编码的功能发生变化,而是由于步行者在不同环境中的表演数量众多而产生的结果,表明何时该是时候应对地形挑战了。
数据还是模型?
元学习的研究通常集中在数据和模型架构上,但元学习优化器之类的例外似乎仍属于模型优化的范畴。诸如自动域随机化之类的数据空间中的元学习已经以数据增强的形式进行了大量研究。
尽管我们已经看到了物理数据也可以进行扩充和随机化,但在图像数据的上下文中最容易理解数据增强。这些图像增强通常包括水平翻转和小幅度的旋转或平移。这种增强在任何计算机视觉管道(例如图像分类,对象检测或超分辨率)中都是典型的。
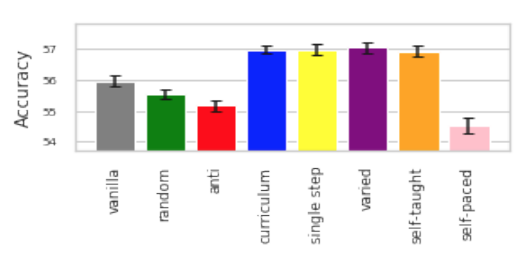
Curriculum Learning是另一个数据级别的优化,它涉及将数据呈现给学习模型的顺序。例如,从一个简单的例子(例如2 + 2 = 4)开始教一个学生,然后再引入更困难的想法(例如2³= 8)。Curriculum Learning的元学习控制器研究如何根据感知到的困难和Hacohen和Weinshall的最新研究在ICML 2019大会上展示了这一点(如下所示)。
神经架构搜索或元学习模型通常比数据级优化受到更多关注。深度学习研究的趋势极大地激发了这一动机。将基础AlexNet架构扩展到ResNet架构,可以明显地提高性能,该基础架构将在大型GPU计算的大型数据集上训练的深度卷积网络的使用率先开创了。ResNet通过DenseNet等手动设计得到进一步扩展,然后被诸如AmoebaNet和EfficientNet之类的元学习技术所超越。图像分类基准测试进展的时间表可以在paperswithcode.com上找到。
元学习神经体系结构试图描述一种可能的体系结构,然后根据一个或多个客观指标来寻找最佳的体系结构。
高级元学习者
神经体系结构搜索采用了广泛的算法来搜索体系结构,随机搜索,网格搜索,贝叶斯优化,神经进化,强化学习和差异搜索。与OpenAI的自动域随机化技术相比,这些搜索算法都相对复杂。似乎可以通过高级搜索算法来改进自动域随机化的想法,例如,基于人口的搜索在UC Berkeley的研究人员的数据增强或Google的AutoAugment中被证明是有用的。
元学习表现力如何?
神经体系结构搜索中经常提到的元学习的局限性之一是搜索空间的限制。神经体系结构搜索从对可能的体系结构的手动设计编码开始。这种手动编码自然限制了搜索可能的发现。但是,需要进行权衡以使搜索完全可计算。
当前的架构搜索将神经架构视为有向无环图(DAG),并尝试优化节点之间的连接。诸如Gaier和Ha的“Weight Agnostic Neural Networks”以及Xie等人的“Exploring Randomly Wired Neural Networks for Image Recognition”等论文。表明构建DAG神经体系结构是复杂的,尚未得到很好的理解。
有趣的问题是,神经体系结构搜索何时能够优化节点上的操作,它们之间的连接,然后能够自由发现诸如新颖的激活函数,优化器或诸如批处理规范化之类的规范化技术。
考虑元学习控制器的抽象程度是很有趣的。例如,OpenAI的Rubik立方体求解器本质上具有3个“智能”组件,一个象征性的Rubik立方体求解器,一个视觉模型和一个用于操纵机器人手的控制器网络。元学习控制器是否足够聪明,可以理解这种模块化并设计由Gary Marcus最近推广的符号和深度学习系统之间的混合系统?
元学习数据扩充也受到很大限制。大多数数据扩充搜索(甚至是自动域随机化)都被约束为元学习控制器可用的一组转换。这些转换可能包括模拟中图像的亮度或阴影的强度。增加数据增强自由度的一个有趣机会是将这些控制器与能够探索非常独特的数据点的生成模型相结合。这些生成模型可以设计狗和猫的新图像,而不是旋转现有的图像或使图像变暗/变亮。尽管非常有趣,但似乎像BigGAN或VQ-VAE-2这样的最新生成模型无法用于ImageNet分类中的数据增强。
迁移与元学习
“元学习”通常用于描述传输和少量学习的功能,与“ AutoML”用于描述模型或数据集的优化方法不同。这种定义与通过自动域随机化解决的Sim2Real的域自适应任务非常吻合。但是,此定义还描述了学习过程,例如从ImageNet分类转换到识别钢缺陷。
魔方解算器的一个有趣结果是能够适应扰动。例如,尽管将橡胶手套戴在手上,手指绑在一起并完全遮盖立方体,但求解器仍能够继续操作(视觉模型必须完全受损,因此必须由Giiker立方体的传感器来进行感测)。这种迁移元学习是策略网络中用于训练机械手控制的LSTM层的结果。我认为,与AutoML优化相比,这种“元学习”的使用更具有记忆增强网络的特性。我认为,这表明了统一元学习和确定该术语单一定义的难度。
结论
由于机器人手协调性的出色显示,Rubik的多维数据集求解器的成功显然令人信服。然而,这项研究中更有趣的部分是引擎盖下的元学习数据随机化。这是一种在学习的同时设计其训练数据的算法。在Jeff Clune的AI-GA中描述的这种范式包含了元学习体系结构,元学习学习算法本身以及生成有效的学习环境的算法,对于深度学习和人工智能的发展是巨大的机会。
原文链接:
https://towardsdatascience.com/the-rise-of-meta-learning-9c61ffac8564





