

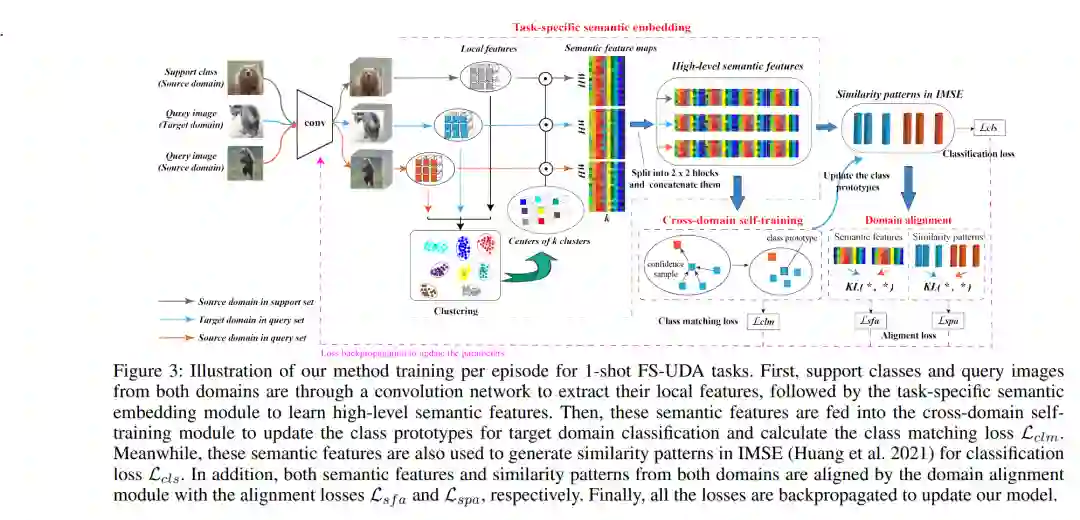
在小样本无监督域适应(FS-UDA)中,大多数现有方法遵循小样本学习(FSL)方法来利用低级局部特征(从传统卷积模型(如ResNet)中学习)进行分类。然而,FS-UDA和FSL的目标是相关但不同的,因为FS-UDA旨在对目标域的样本进行分类,而不是源域的样本。局部特征对FS-UDA来说是不够的,可能会引入对分类的噪声或偏差,不能用来有效地对齐域。**为了解决上述问题,本文旨在改进局部特征,使其更具判别力并与分类相关。本文为FS-UDA提出一种新的特定于任务的语义特征学习方法(TSECS)。**TSECS学习高层次语义特征,用于图像到类的相似性度量。在此基础上,设计了一种跨域自训练策略,利用源域少量标记样本构建目标域分类器。此外,通过最小化源域和目标域高层特征分布的KL散度来缩短两域样本之间的距离。在DomainNet上的广泛实验表明,所提出的方法明显优于FS-UDA中的SOTA方法(即~ 10%)。
https://www.zhuanzhi.ai/paper/2bfd4a8bb479a4dca8cca6b711c91af5
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年3月2日
Arxiv
0+阅读 · 2023年3月1日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年3月2日
Arxiv
0+阅读 · 2023年3月1日