

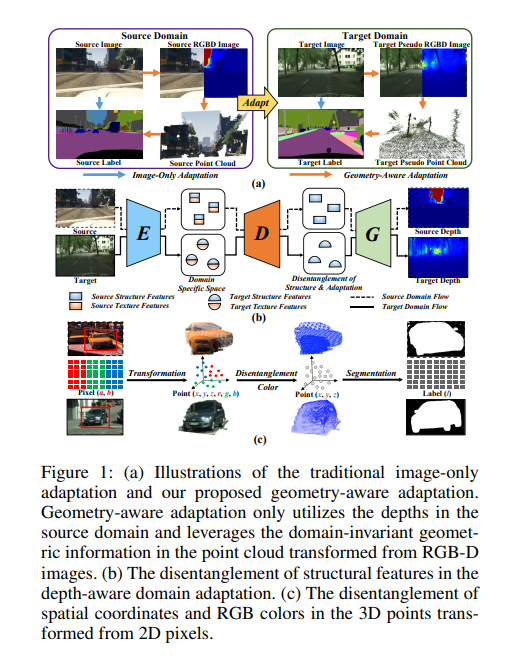
度量和缓解合成(源)数据与真实场景(目标)数据之间的差异是领域自适应语义分割的核心问题。近年来,已有工作通过在源域引入深度信息来增强几何和语义知识迁移,但仅基于二维估计深度无法提取物体的位置和形状等内在三维信息。本文提出一种新的几何感知域适应网络(GANDA),利用更紧凑的3D几何点云表示来缩小域差距。首先,利用源域的辅助深度监督获取目标域的深度预测,实现结构-纹理解缠;除了深度估计,显式利用RGB-D图像生成的点云上的3D拓扑结构,以进一步在目标域中进行坐标颜色解缠和伪标签细化。此外,为了改进目标域上的二维分类器,我们进行了源域到目标域的域不变几何自适应,统一了两个域上的二维语义和三维几何分割结果。请注意,我们的GANDA在任何现有UDA框架中都是即插即用的。定性和定量的实验结果表明,该模型在GTA5→Cityscapes和SYNTHIA→Cityscapes数据集上的性能均优于目前的先进水平。
https://www.zhuanzhi.ai/paper/e213cce10ef9b5c4515fa8924aa8fd44
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文