论文浅尝 - ICML2020 | 通过关系图上的贝叶斯元学习进行少样本关系提取
论文笔记整理:申时荣,东南大学博士生。

来源:ICML 2020
链接:http://arxiv.org/abs/2007.02387
一、介绍
本文研究了少样本关系提取,旨在通过训练每个关系少量带有标记示例的句子来预测句子中一对实体的关系。为了更有效地推广到新的关系,在本文中,我们研究了不同关系之间的相关性,并提出利用全局关系图。我们提出一种新颖的贝叶斯元学习方法,以有效地学习关系原型向量的后验分布,其中原型向量的初始先验是通过全局关系图上的图神经网络进行参数化的。此外,为了有效地优化原型向量的后验分布,我们建议使用与MAML算法有关但能够处理原型向量不确定性的随机梯度Langevin动力学。可以以端到端的方式有效,高效地优化整个框架。在两个基准数据集上进行的实验证明了我们提出的方法在少样本和零样本设置下针对竞争基准的有效性。
二、问题定义
少样本关系抽取是许多研究领域的重要任务,其目的在于只给定少量标注样本的前提下预测给定句子的两个实体之间的关系。但是,由于标注数据中的信息有限,结果仍然不能令人满意。为了进一步改善结果,应考虑增加另一个数据源。在本文中,我们建议使用全局关系图研究少数关系提取,其中描述所有可能关系的全局图假定为额外的数据源。更正式地说,我们将全局关系图表示为G =(R; L),其中R是所有可能关系的集合,而L是不同关系之间的链接的集合。链接的关系可能具有更多相似的语义。每个类别有支撑的标注样本集记做S={Xs},对应的用于测试的样本集为查询集记做Q={Xq}。
三、模型
首先模型的整体目标是优化一下目标函数:
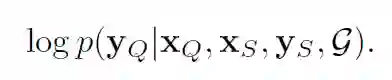
上式可以变化为
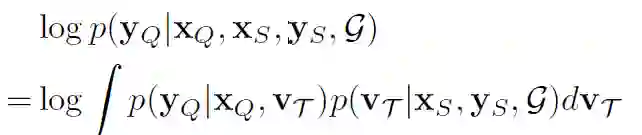
其中VT是关系类别的原型向量。
其中有XQ和VT得到yQ的概率通过如下的式子得到
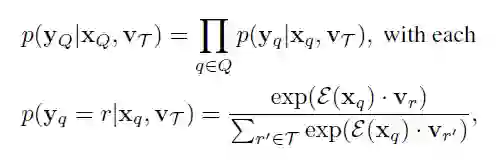
通过计算余弦相似度的归一化得到。(每个V均进行了模长归一化,ε表示除以模长操作)。
我们还有
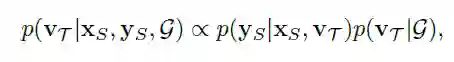
其中
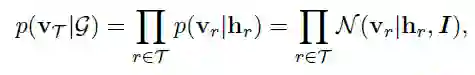
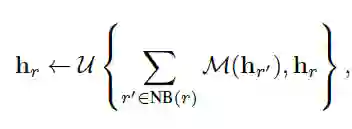
hr是通过图卷积对关系图编码得到的
另外
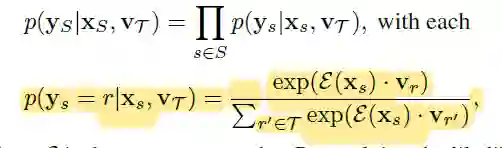
四、训练优化
训练过程的目标函数为
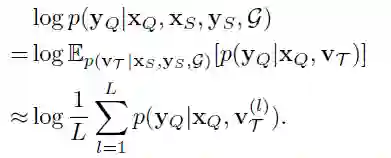
但是求期望的过程中需要对v进行采样,所以我们采用了如下的方法,首先初始化v
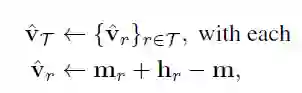
mr是support set中的关系编码的均值,m是所有关系样本编码的均值,hr是图卷积的输出。之后更新原型向量v
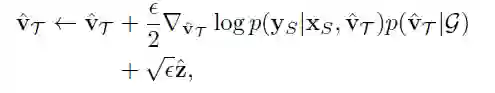
随后在query集合上更新。
五、实验结果
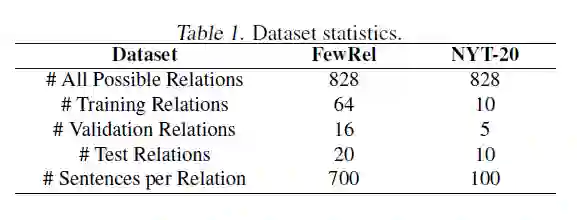
实验数据
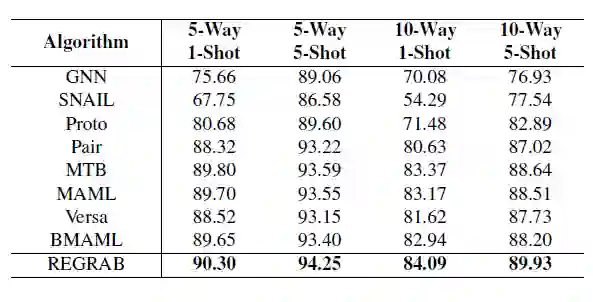
实验结果
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。


