

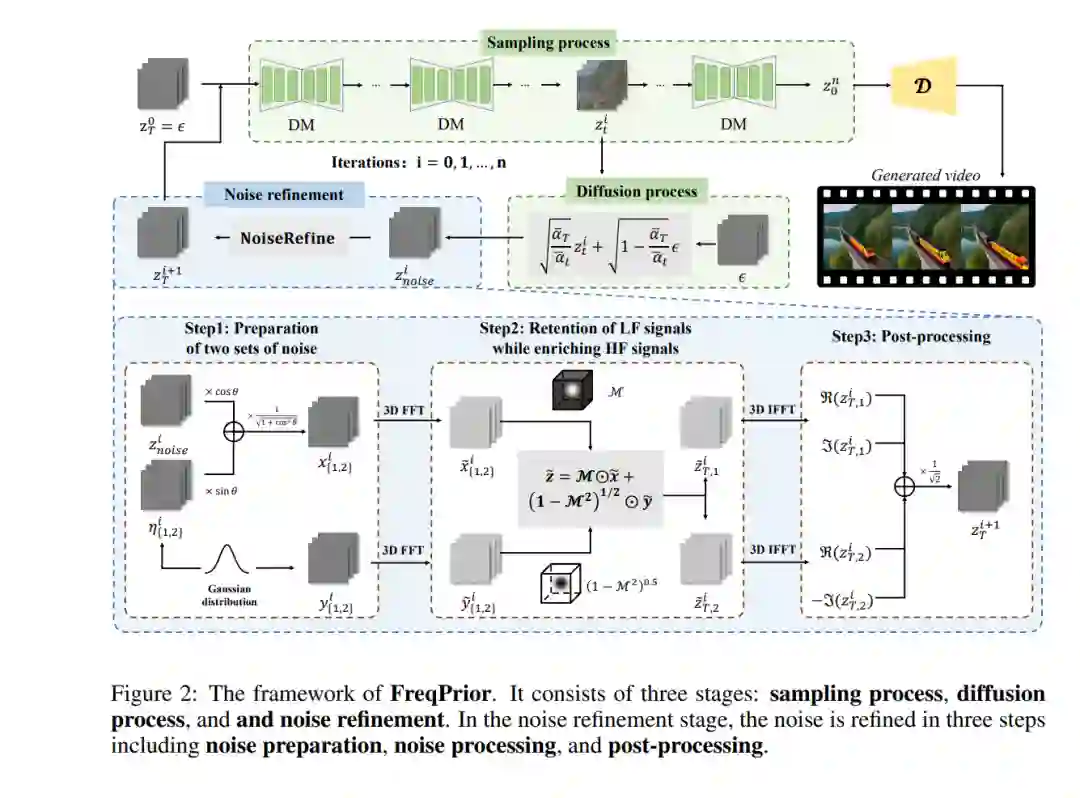
文本驱动的视频生成已经取得了显著进展,这得益于扩散模型的发展。在训练和采样阶段之外,近期的研究已经探讨了扩散模型的噪声先验,因为改进的噪声先验能够产生更好的生成结果。一种最近的方法利用傅里叶变换来操控噪声,标志着在这一领域中对频率操作的初步探索。然而,这种方法常常生成缺乏运动动态和图像细节的视频。在本研究中,我们提供了对现有方法中存在的方差衰减问题的全面理论分析,阐明了该问题如何导致细节和运动动态的丧失。我们认识到噪声分布对生成质量的关键影响,因此提出了FreqPrior,一种新颖的噪声初始化策略,通过在频域中细化噪声来改进生成效果。我们的方法采用了一种新颖的滤波技术,旨在处理不同频率的信号,同时保持噪声先验分布接近标准高斯分布。此外,我们提出了一种部分采样过程,通过在寻找噪声先验时对潜在变量在中间时间步进行扰动,显著减少了推理时间,同时不影响生成质量。在VBench上的大量实验表明,我们的方法在质量和语义评估中均获得了最高分,从而取得了最佳的总评分。这些结果凸显了我们提出的噪声先验的优越性。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日