

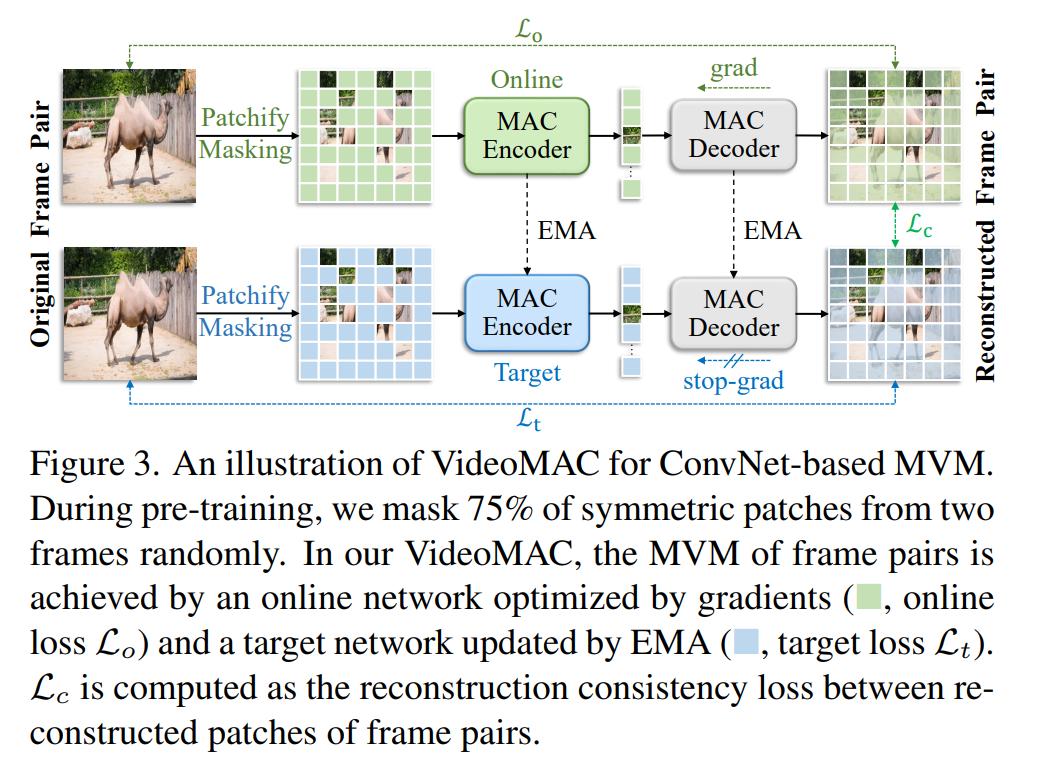
近期,自监督学习技术的进步,如遮罩自编码器(MAE),极大地影响了图像和视频的视觉表示学习。然而,值得注意的是,现有的遮罩图像/视频建模方法过度依赖于资源密集型的视觉变换器(ViTs)作为特征编码器。在本文中,我们提出了一种新的方法,称为VideoMAC,它将视频遮罩自编码器与资源友好的卷积神经网络(ConvNets)结合起来。具体来说,VideoMAC采用对随机采样的视频帧对进行对称遮罩。为了防止遮罩模式的消散问题,我们使用了采用稀疏卷积操作符实现的ConvNets作为编码器。同时,我们提出了一种简单而有效的遮罩视频建模(MVM)方法,这是一种双编码器架构,包括一个在线编码器和一个指数移动平均目标编码器,旨在促进视频中帧间重建的一致性。此外,我们展示了VideoMAC通过赋予经典(ResNet)/现代(ConvNeXt)卷积编码器利用MVM的优势,比基于ViT的方法在下游任务上表现更佳,包括视频对象分割(+5.2% / 6.4% J&F)、身体部位传播(+6.3% / 3.1% mIoU)和人体姿态跟踪(+10.2% / 11.1% PCK@0.1)。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日