

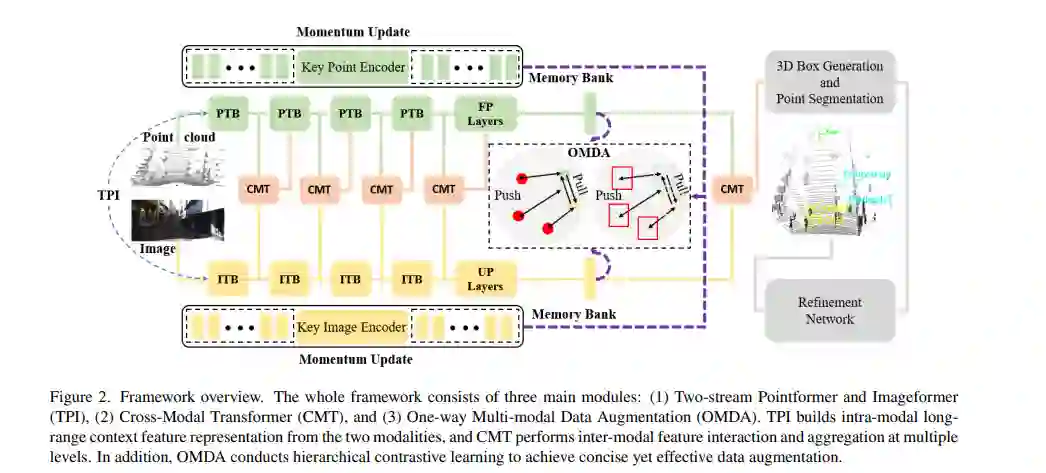
在自动驾驶中,激光雷达点云和RGB图像是两种主要的具有互补线索的三维目标检测数据模式。然而,由于模态内之间存在很大的差异,很难充分利用它们。为了解决这个问题,我们提出了一个新的框架,即用于多模态三维物体检测(CAT-Det)的对比增强Transformer(contrast Augmented Transformer)。具体来说,CAT-Det采用双流结构,由点前(PT)分支、图像前(IT)分支和交叉模态转换器(CMT)模块组成。PT、IT和CMT共同编码内模态和跨模态的长程上下文来表示一个对象,从而充分挖掘多模态信息进行检测。此外,我们提出了一种有效的单向多模态数据增强(OMDA)方法,通过在点和对象层面上进行层次对比学习,仅通过增强点云就可以显著提高精度,而无需复杂地生成两种模式的成对样本。在KITTI基准上的大量实验表明,CAT-Det达到了最新的技术水平,凸显了其有效性。
https://www.zhuanzhi.ai/paper/cdc9f14be76be206c2dfa2c11871e4d7
成为VIP会员查看完整内容
相关内容

相关主题



相关VIP内容
相关资讯
相关论文