

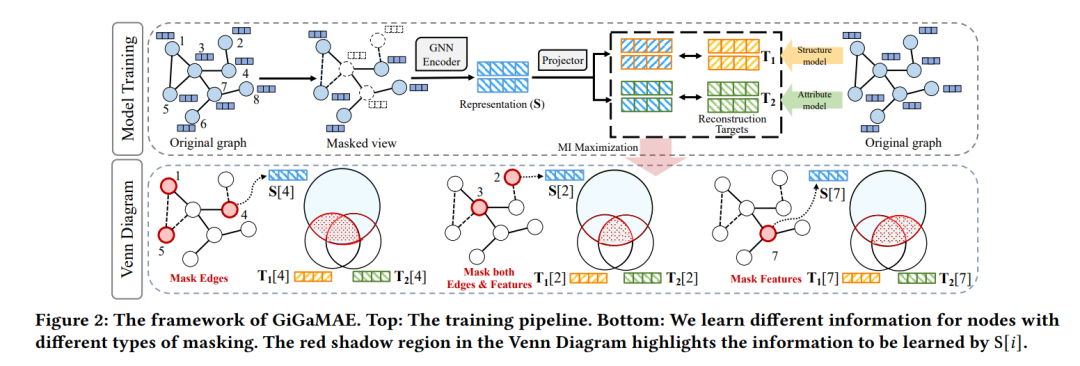
近期,使用掩码自编码器的自监督学习因其能有效产生图像或文本表示而日益受到欢迎,这些表示可以应用于多种下游任务,无需重新训练。然而,我们观察到当前的掩码自编码器模型在图数据上缺乏良好的泛化能力。为了解决这一问题,我们提出了一个名为GiGaMAE的新型图掩码自编码器框架。与现有的掩码自编码器不同,这些编码器通过显式重构原始图组件(例如,特征或边)来学习节点表示,在本文中,我们提议协同重构有信息性和整合性的潜在嵌入。通过考虑 encompassing 图的拓扑结构和属性信息的嵌入作为重建目标,我们的模型可以捕获更为泛化和全面的知识。此外,我们引入了一个基于互信息的重建损失,该损失可以有效地重建多个目标。这个学习目标使我们能够区分从单一目标中学到的独有知识和多个目标共享的常见知识。我们在三个下游任务上评估了我们的方法,使用了七个数据集作为基准。大量实验显示,GiGaMAE相对于最先进的基线表现出色。我们希望我们的结果将为图结构数据上的基础模型设计提供启示。我们的代码可在以下网址找到: https://github.com/sycny/GiGaMAE。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日


相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日