

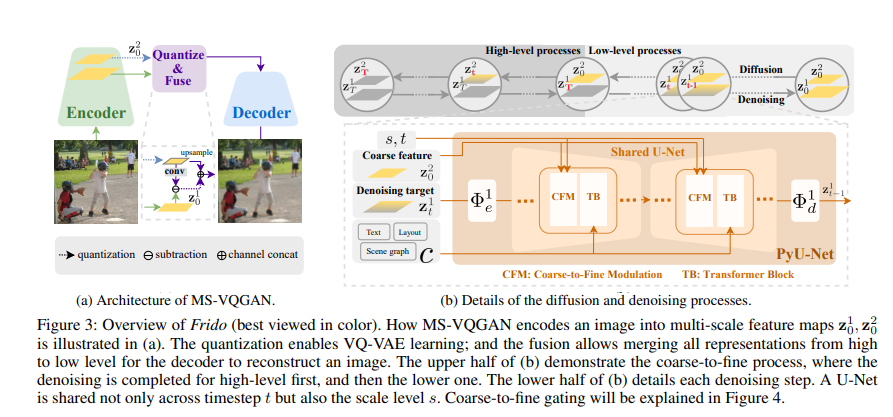
扩散模型(DMs)在高质量图像合成中显示出巨大的潜力。然而,在制作复杂场景的图像时,如何正确地描述图像的全局结构和对象细节仍然是一个具有挑战性的任务。在这篇论文中,我们提出了Frido,一个特征金字塔扩散模型执行多尺度粗-细去噪过程的图像合成。我们的模型将输入图像分解为尺度相关的矢量量化特征,然后进行从粗到细的调制生成图像输出。在上述多尺度表示学习阶段,可以进一步利用文本、场景图或图像布局等附加输入条件。因此,Frido也可以用于条件或交叉模态图像合成。我们在各种无条件和有条件的图像生成任务上进行了广泛的实验,从文本到图像合成,从布局到图像,从场景到图像,到标签到图像。更具体地说,我们在五个基准上获得了最先进的FID得分,分别是COCO和OpenImages上的布局到图像,COCO和Visual Genome上的场景到图像,以及COCO上的标签到图像。
https://www.zhuanzhi.ai/paper/d6197fd1315f12b3d3cd40944d4d9272
成为VIP会员查看完整内容
相关内容
Arxiv
10+阅读 · 2021年1月24日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日

相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2021年1月24日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日