
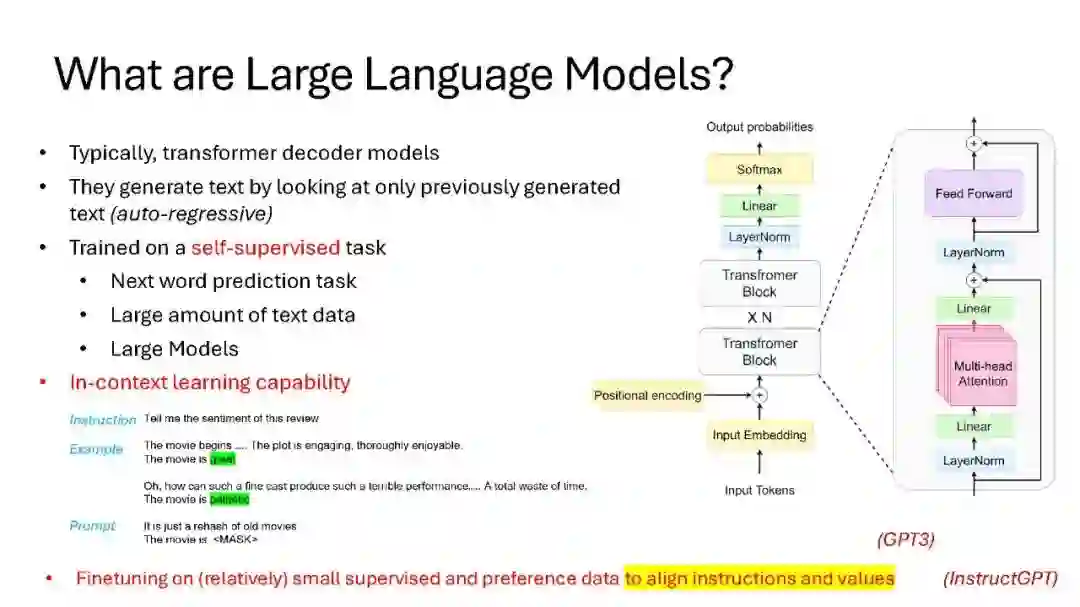
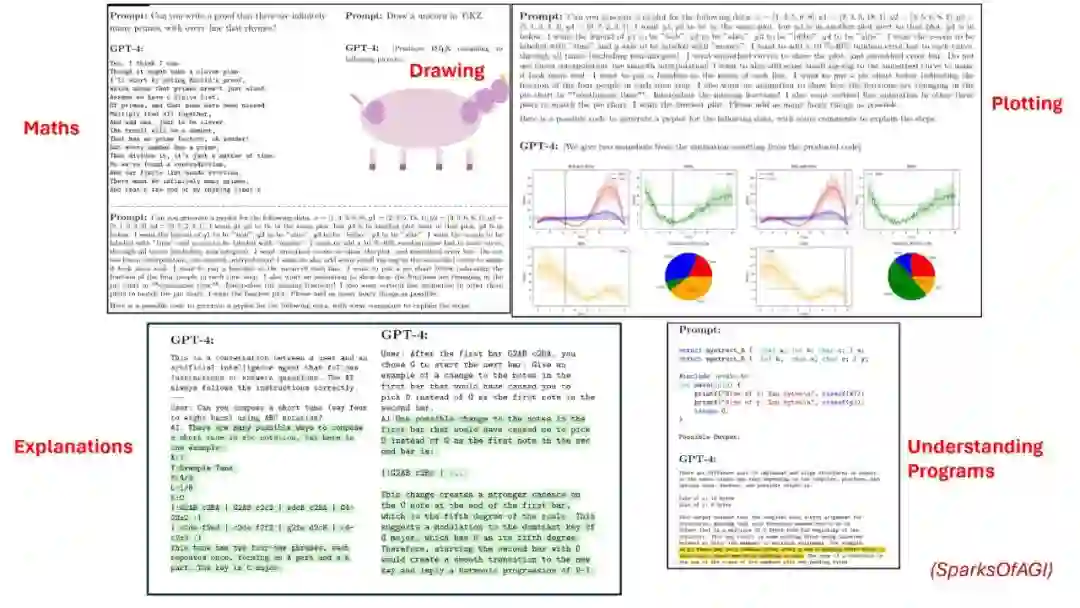
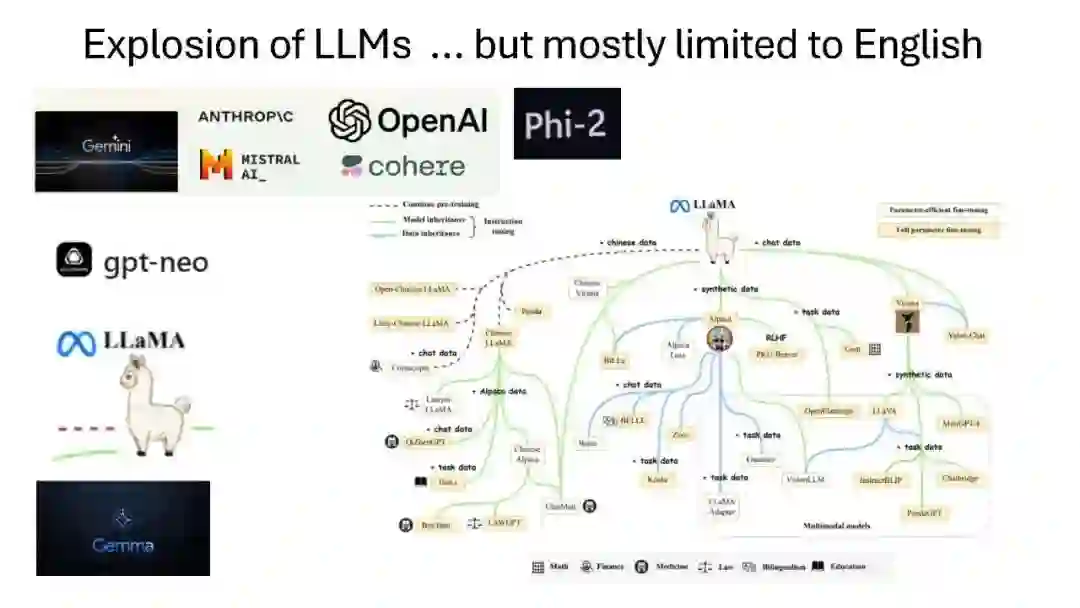
大语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展示了卓越的能力,表现出知识、常识和推理技能。虽然这些LLMs在处理英语时表现出色,但在非英语语言,特别是资源匮乏的语言上的表现显著较低。这凸显了将其优势扩展到非英语语言的重大挑战。在本次讲座中,我将讨论涉及的技术挑战以及最近研究中为将英语LLMs扩展到其他语言并缩小与英语语言性能差距所采用的各种方法。讲座将涵盖从整个LLM技术栈的广泛主题——从分词器到指令调优——这些都与使LLMs具备多语言能力相关。此外,讲座还将介绍我们在这一领域的最新努力,以及如何赋予印度语言以LLMs提供的能力。 GitHub页面:https://github.com/anoopkunchukuttan/...






成为VIP会员查看完整内容
相关内容
Arxiv
153+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
153+阅读 · 2023年3月29日