本文深入探讨了当前顶尖的人工智能技术,即生成式人工智能(Generative AI)和大型语言模型(LLMs),如何重塑视频技术领域,包括视频生成、理解和流媒体。文章强调了这些技术在制作高度逼真视频中的创新应用,这是在现实世界动态和数字创造之间架起桥梁的一大飞跃。研究还深入探讨了LLMs在视频理解方面的高级能力,展示了它们在从视觉内容中提取有意义信息方面的有效性,从而增强了我们与视频的互动。在视频流媒体领域,本文讨论了LLMs如何有助于更高效和以用户为中心的流媒体体验,适应内容交付以满足个别观众偏好。这篇全面的综述贯穿了当前的成就、持续的挑战和将生成式AI和LLMs应用于视频相关任务的未来可能性,强调了这些技术为推动视频技术领域的进步——包括多媒体、网络和人工智能社区——所持有的巨大潜力。
影响声明—本文通过研究生成式人工智能和大型语言模型(LLMs)在视频生成、理解和流媒体中的集成,为视频技术领域做出了贡献。对这些技术的探索提供了它们在增强视频内容的真实性和互动性方面的潜力和局限性的基础理解。LLMs在视频理解方面的探索为可访问性和互动的进步奠定了基础,有望提高教育工具的效能、改进用户界面和推进视频分析应用。此外,文章强调了LLMs在优化视频流媒体服务中的作用,导致更个性化和带宽高效的平台。这可能会显著惠及娱乐行业,提供适应个人偏好的自适应流媒体解决方案。通过识别关键挑战和未来研究方向,文章指导了将AI与视频技术融合的持续努力,同时提高了人们对潜在伦理问题的认识。其影响力超越了学术界,鼓励在视频技术中负责任地发展AI和制定政策,平衡技术进步与伦理考量。
近年来,由于视频相关技术的激动人心的进步,视频内容的创建、分析和传递都经历了重大突破。学术界和工业界已共同推动视频处理领域可能性的极限,从创建逼真的视频到理解复杂的视觉环境以及优化视频流媒体以改善用户体验。整合生成式AI和大型语言模型(LLM)可以在视频相关领域开辟激动人心的可能性。 随着创造逼真且上下文一致的视频的能力,视频创作已成为一个引人入胜的研究领域。研究人员已在利用深度学习方法如生成对抗网络(GANs)制作揭示细节且捕捉现实世界动态本质的电影剪辑方面取得了重大进展。然而,如长期视频合成一致性和对生成内容的精细控制等挑战仍在探索中。
视频理解方面也有类似的发展,该领域涉及从视频剪辑中提取重要信息。传统技术依赖于手工创建的特征和视频动态的显式建模。最近在语言和视觉方面的进步取得了显著进展。像OpenAI的GPT等预训练的基于变换器的架构在处理和生成文本数据方面展示了令人印象深刻的才能。这些LLM对于视频理解任务,如字幕、动作识别和时间定位,具有巨大的潜力。
此外,由****于对高质量、高分辨率和低延迟视频服务的需求日益增加,改善视频传递已变得越来越重要且具有挑战性。带宽限制、网络抖动和不同用户偏好显著阻碍了无缝和沉浸式的流媒体体验。通过提供感知上下文的视频分发、实时视频质量改进和根据用户偏好的自适应流媒体,LLM提供了一个克服这些困难的激动人心的方法。
鉴于这些进展,本研究彻底分析了生成式AI和LLM在生成、理解和流式传输视频方面的潜力。我们回顾了现有工作,试图回答以下问题: • 提出了哪些技术,并正在彻底改变上述视频研究领域? • 为了推动上述视频服务中生成式AI和LLM方法的使用,还有哪些技术挑战需要解决? • 由于采用生成式AI和LLM方法,引发了哪些独特的关注? 我们希望吸引多媒体、网络和人工智能社区的关注,以鼓励对这一迷人且迅速发展的领域的未来研究。
我们设想生成式AI和大型语言模型(LLM)在视频的整个生命周期中发挥关键作用,从生成、理解到流媒体。该框架跨越了三个主要的计算机科学社区,即人工智能、多媒体和网络。人工智能社区正在见证前所未有的发展速度,从2021年到2022年仅用了大约一年的时间就从能够进行文本到图像生成的模型发展到能够进行文本到视频生成的模型。现在甚至有演示展示了仅使用提示就能创建3D视频的能力。因此,我们可以想象生成式AI将对视频生成行业变得更为重要,超越甚至完全替代传统的生成方法。视频理解在许多情况下都很有用,例如场景分割、活动监控、事件检测和视频字幕,这是一个获得越来越多关注的新兴方向。自2023年以来,像GPT-4和Video-ChatGPT [8]这样的最先进产品也显著提升了LLM理解图像和视频等多模态输入的能力。就视频流媒体而言,LLM还有改进流媒体管道几个关键步骤的有趣潜力。例如,一个理解能力改进的模型可以把握视频场景的语义意义,并通过相应地改变编码率来优化传输。此外,如点云这样在XR游戏中广泛使用的3D视频流媒体,可以从LLM对周围环境的理解中受益,预测用户下一刻的视野范围(FoV)来进行内容预取。
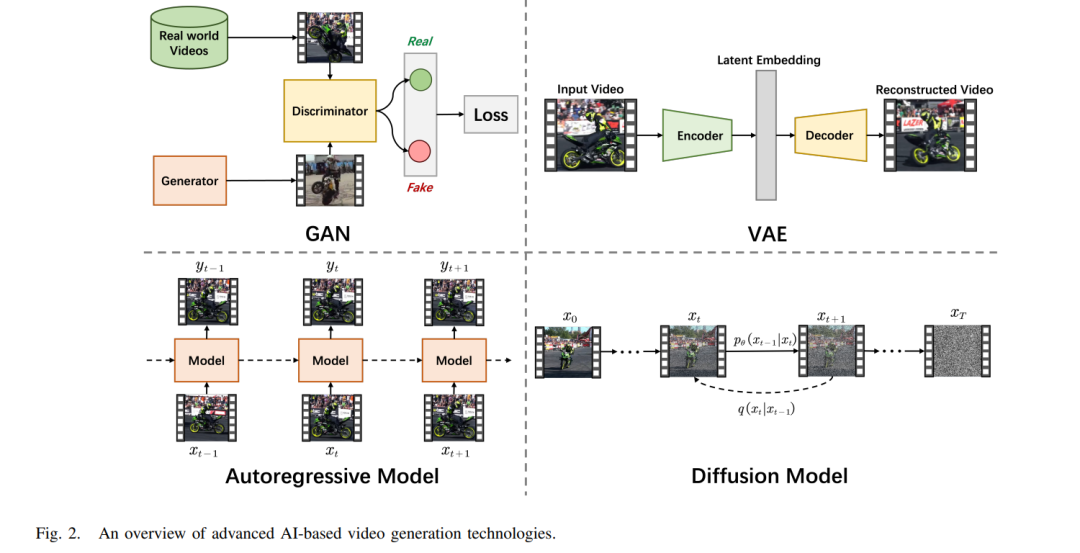
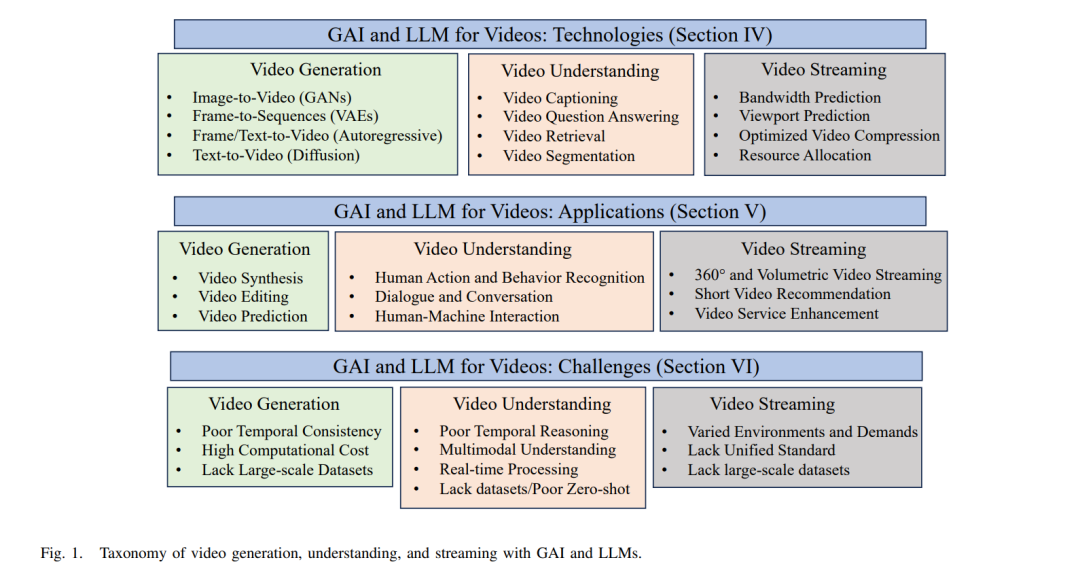
A. 主要组成部分 生成式AI和LLM之间的协同作用已在视频生成领域开辟了新的前沿,打造与现实几乎无法区分的视觉效果。这些技术共同丰富了数字景观,创造了创新内容如下(第IV-A节): • 生成对抗网络(GANs)利用生成网络和判别网络之间的创造性对抗过程来理解和复制复杂模式,产生逼真的视频样本。 • 变分自编码器(VAEs)生成连贯的视频序列,提供了一个结构化的概率框架,用于无缝地融合叙事上合理的帧。 • 自回归模型创建的序列中,每个视频帧都逻辑上从上一个帧继承,确保叙事和视觉的连续性,吸引观众。 • 扩散模型将复杂的文本叙述转换为详细和高分辨率的视频,推动文本到视频合成的界限。 接下来,LLM通过提供富有情境的解释和描述来增强视频理解,促进更深入的视频内容参与(第IV-B节): • 视频字幕使用LLM生成富有洞察力和准确的描述,以自然语言捕捉视觉内容的本质,使视频更易于搜索和访问。 • 视频问答利用LLM的情境理解能力处理复杂的观众询问,提供增值且深入的观看体验的回应。 • 视频检索和分割由LLM革新,它们解析和分类视频内容为可理解的段落,简化了庞大视频库的可搜索性和导航性。 最后,LLM可以通过优化带宽使用、个性化内容交付和增强观众互动等方式重新定义流媒体景观(第IV-C节): • 带宽预测通过分析过去和现在的网络数据的LLM进行改进,预测未来需求以主动分配资源,从而确保流畅的流媒体。 • 视点预测通过LLM对内容和用户行为的理解增强,预测视频中的下一个焦点区域,提供量身定制且沉浸式的观看体验。 • 视频推荐和资源分配通过LLM的分析能力得到提升,将观众偏好与内容匹配并管理网络资源,提供定制化且高效的流媒体服务。