

大型语言模型(LLMs)在自然语言处理的一般领域已经取得了巨大的成功。在本文中,我们将LLMs引入地球科学领域,目标是推进这个领域的研究和应用。为此,我们展示了地球科学领域首个LLM,K2,并开发了一套资源以进一步推动地球科学中的LLM研究。例如,我们精心创建了首个地球科学指导调整数据集,GeoSignal,目的是使LLM的回应与地球科学相关的用户查询保持一致。此外,我们还建立了首个地球科学基准测试,GeoBenchmark,用以评估LLMs在地球科学背景下的性能。在这项工作中,我们尝试了一整套配方,将预训练的通用领域LLM适应到地球科学领域。具体来说,我们对LLaMA-7B模型进行了进一步的训练,使用了超过200万份地球科学文献(39亿个令牌),并利用GeoSignal的监督数据进行微调。此外,我们还分享了一种协议,即使在人力资源稀缺的情况下,也可以高效地收集特定领域的数据和构建特定领域的监督数据。在GeoBenchmark上进行的实验显示了我们的方法和数据集的有效性。
https://www.zhuanzhi.ai/paper/4557ccfc577308f66826157731829378
地球科学家长期以来一直面临着整合来自各种来源和学科的数据的挑战,由于术语、格式和数据结构的差异,导致了地球科学中许多自然语言任务,如地质和地理命名实体识别[10],空间和时间关系提取[27]构建地球科学知识图谱[7],地质报告和文献摘要[26],以及通过地球科学语言模型进行表示学习[33]。然而,地球科学中的语言模型稀缺,且规模有限[8]。这种情况与大型语言模型(LLMs),如ChatGPT [31] 和 GPT-4 [32] 在一般自然语言处理(NLP)中的繁荣形成鲜明对比,后者已取得了显著的成功。尽管这些模型在一般领域中的效果良好,但现有的LLMs往往无法满足地球科学家的需求。这种不足主要归因于缺乏关于地球科学问题的可靠知识,因为相关的地球科学数据很少存在于常用的预训练文本语料库中,如C4 [35]和 Pile [12]。此外,像ChatGPT这样表现优秀的LLMs只通过APIs提供服务,这为外部领域的研究和进步设置了障碍。为了解决这些问题,促进地球科学领域的研究和应用,我们介绍了首个面向地球科学的开源LLM,名为K2(世界第二高峰,我们相信未来将会创建出更大更强大的地球科学语言模型)。K2是一个GPT-like的语言模型,包含70亿个参数,基于预训练的LLaMA[42]模型,但专注于地球科学领域。伴随着K2的引入,本文还探讨了收集地球科学文本语料、构建地球科学指令监督数据、建立地球科学NLP任务基准的道路,这与Deep-time Digital Earth (DDE, [44])2大科学计划保持一致。
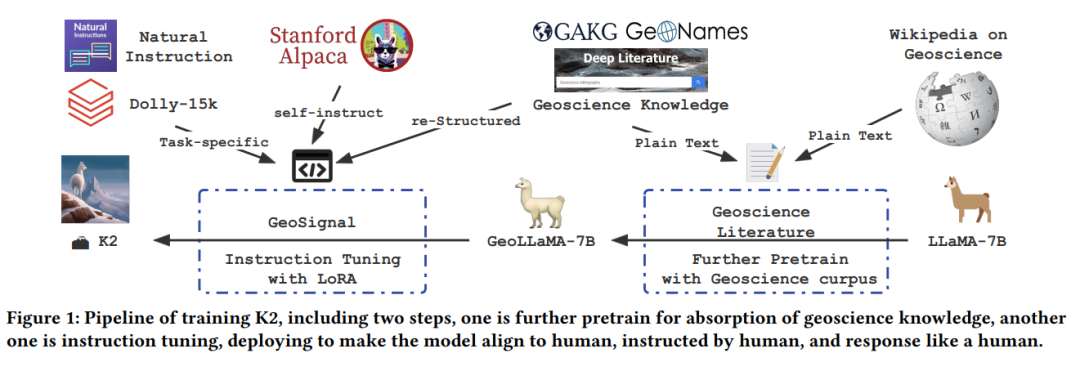
K2的训练分为两个阶段,预训练阶段和指令调整阶段,如图1所示。在预训练阶段,我们在我们从地球科学论文中预处理的地球科学文本语料库上继续训练LLaMA-7B模型。然后我们进行指令调整[4, 23, 36],在这里我们进一步训练模型来遵循人类的指令。为此,我们已经策划了GeoSignal,这是一个通过统一8个不同的地球科学NLP任务数据和提示(如关系提取、实体识别、分类和总结)创建的指令调整数据集。我们还构建了GeoBenchmark,这是一个由国家研究生入学考试(NPEE)中的地球科学和AP测试地质学、地理学和环境科学收集的1500多个客观问题和939个主观问题组成的评估数据集。GeoBenchmark用于跟踪地球科学语言模型的进度并推动其发展。通过我们在数据收集和训练方面的共同努力,最终的K2模型是一个可以用来设计多个地球科学应用的基础语言模型,使地球科学研究者和实践者受益[28]。
我们的贡献可以列举如下: • 我们引入了K2,这是地球科学领域的一种基础语言模型。K2可以回答地球科学问题,并通过合适的提示按照地球科学家的指示进行操作,显示出其在地球科学方面的专业性。 • 我们构建了GeoSignal,这是首个地球科学监督指令数据。为了评估K2在地球科学任务上的表现以及后续的地球科学语言模型,我们构建了GeoBenchmark,这是地球科学领域的第一个NLP任务基准。 • 我们以地球科学为例,建立了一个构建领域文本语料库和领域监督指令数据的范例,并探讨了训练领域特定语言模型的配方。 • 与类似大小的基线模型相比,K2在主观和客观的地球科学任务上表现得更好。最后,我们在Github上发布了代码,K2的权重,GeoSignal,和GeoBenchmark。 本文的其余部分安排如下:第2节将介绍K2的相关工作。在第3节,我们将详细说明数据收集和监督指令数据构建的过程。进一步地,我们将在第4节分享我们的进一步预训练的细节和高效的指令调整过程,而在第5节,我们将评估K2并进行消融研究。最后,我们将讨论所提出的话题,所学到的经验教训,潜在的应用,以及与K2相关的未来工作。

