
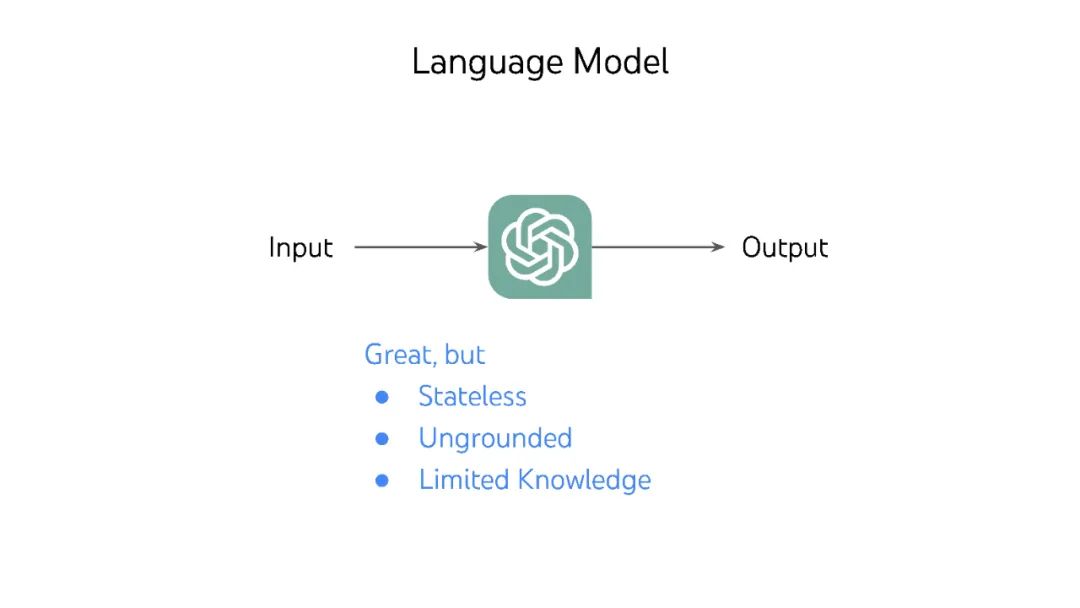
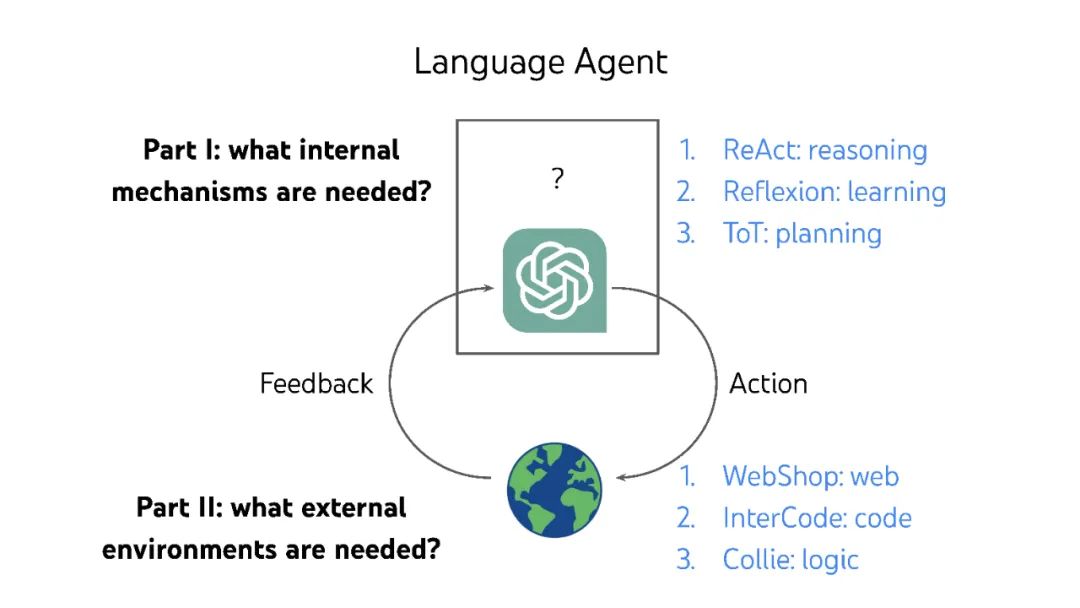
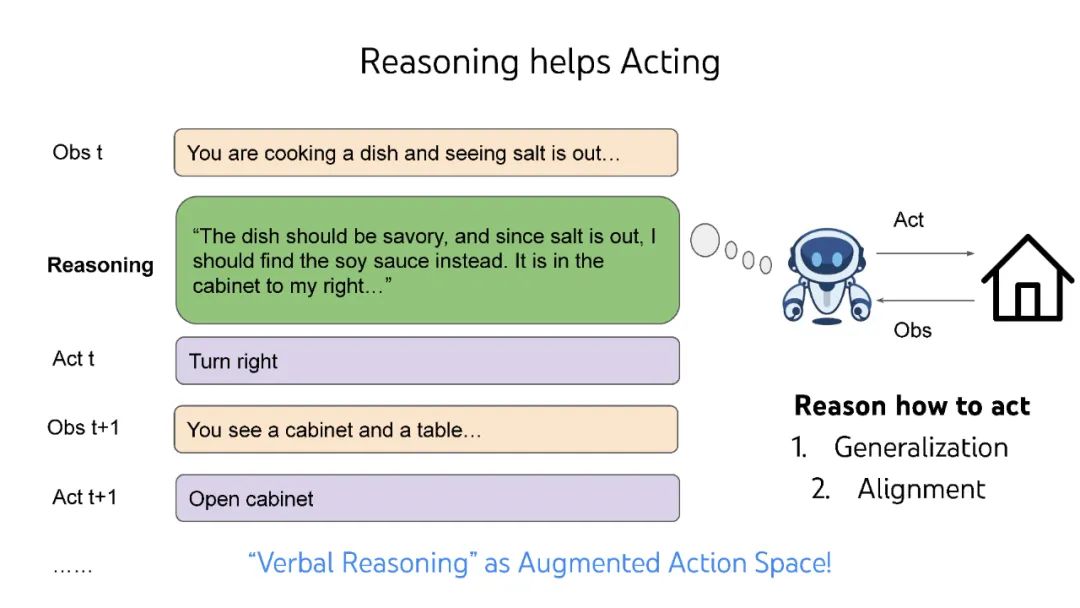
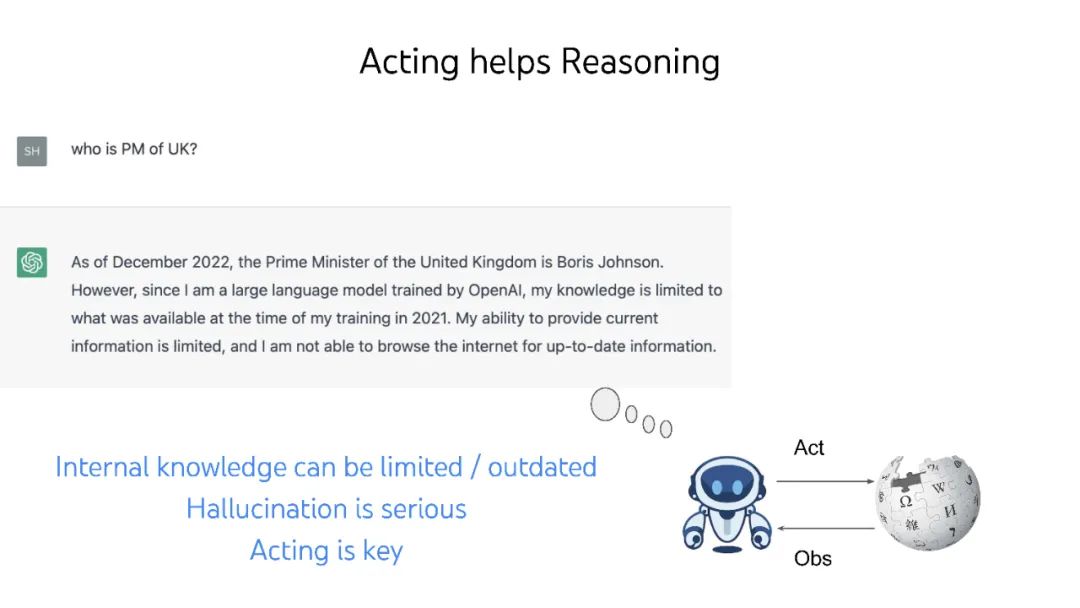
大型语言模型(LLM)彻底改变了自然语言处理,但它们被训练为编写,而不是行动或决策。本文提出了几种想法(ReAct、Reflexion、思想树),以将它们转换为与世界自主交互的语言代理,以及几个新的基准(WebShop、InterCode、Collie),以开发和评估这种代理,而不依赖人类偏好标记或LLM评分。 视频: https://www.bilibili.com/video/BV1ju4y1e7Em/ 作者个人主页: 个人主页:https://ysymyth.github.io/



成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日