
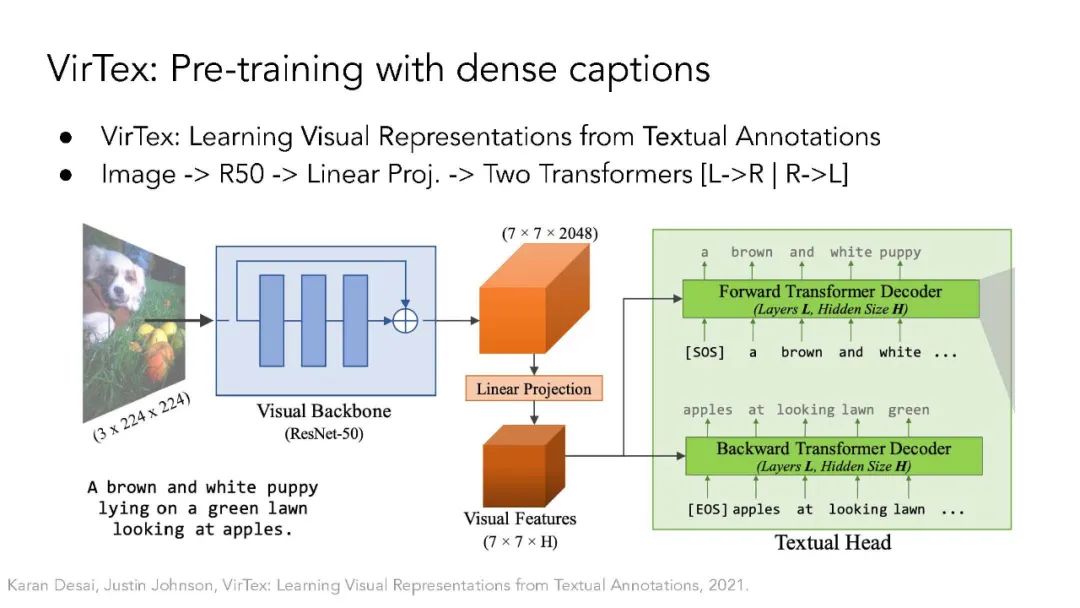
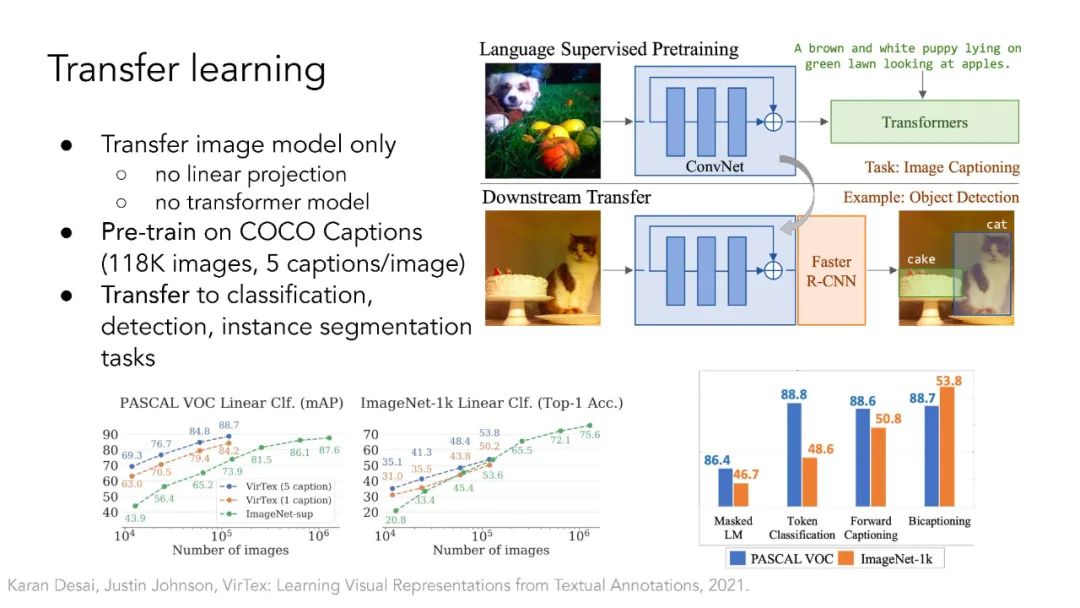
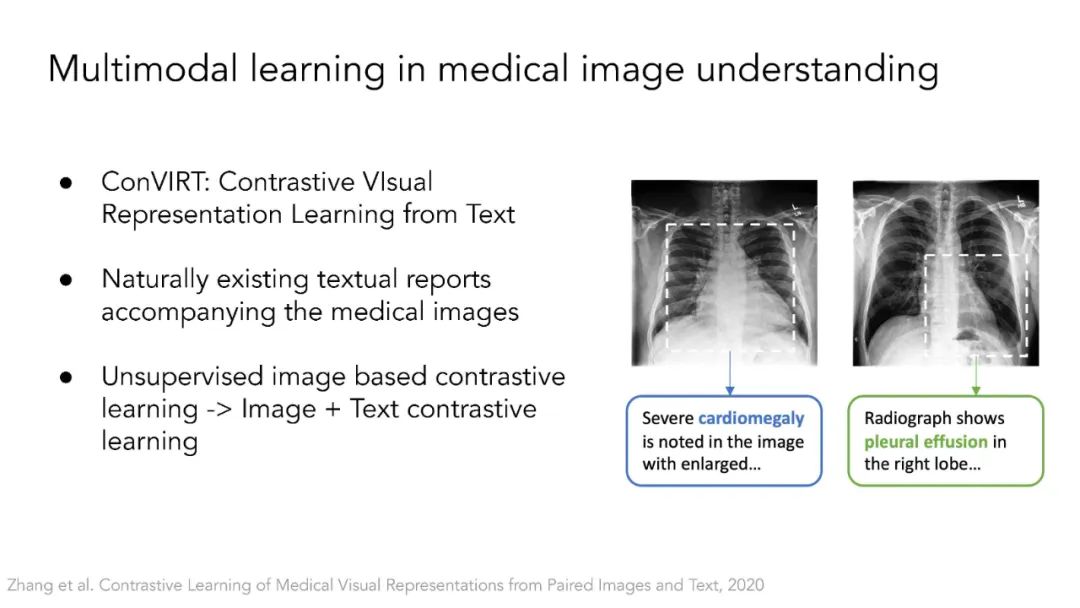
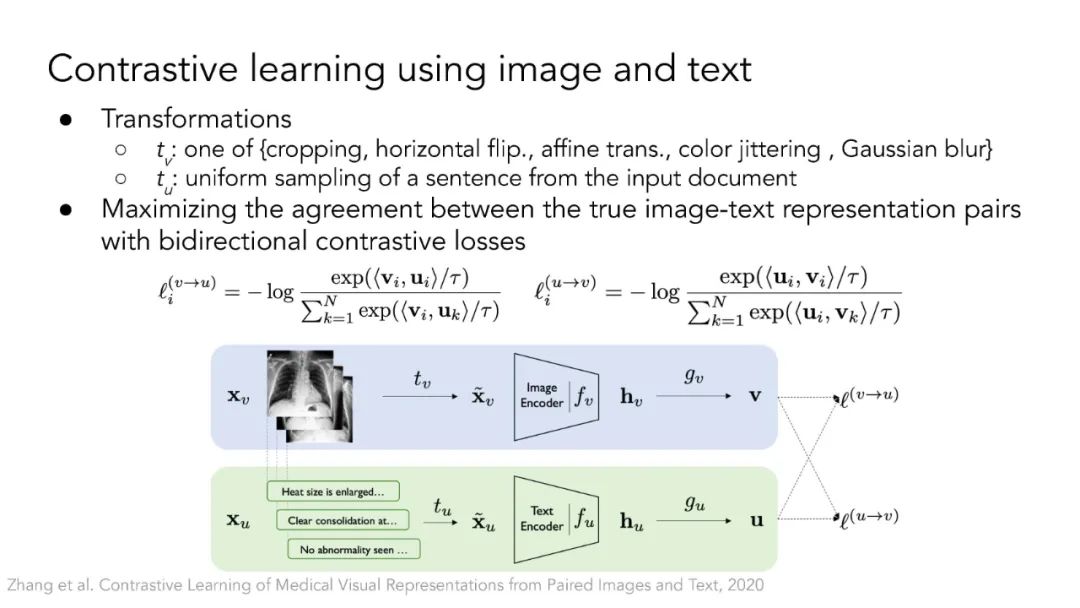
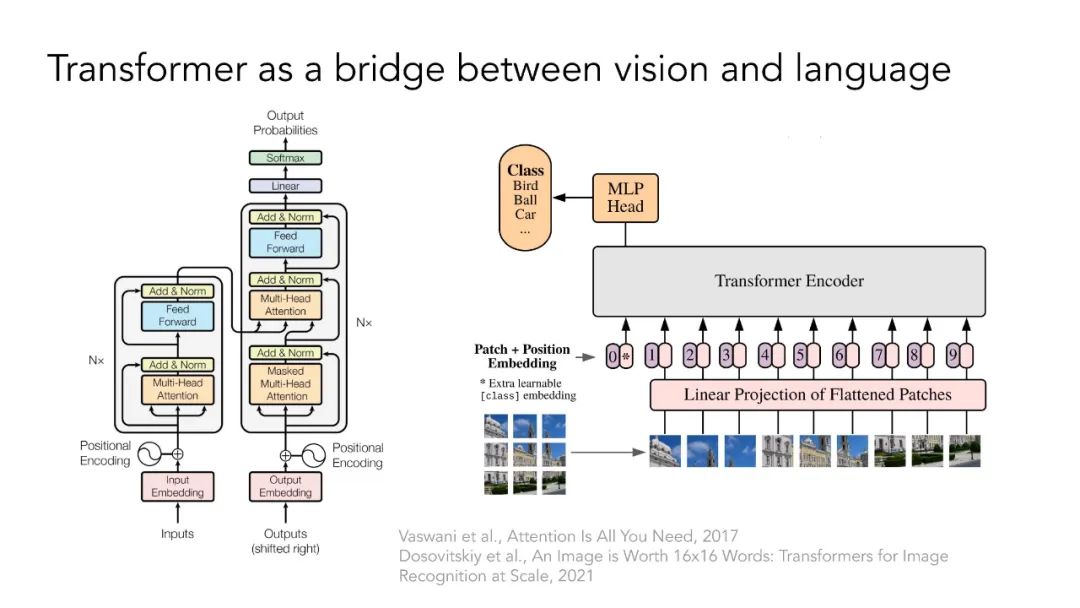
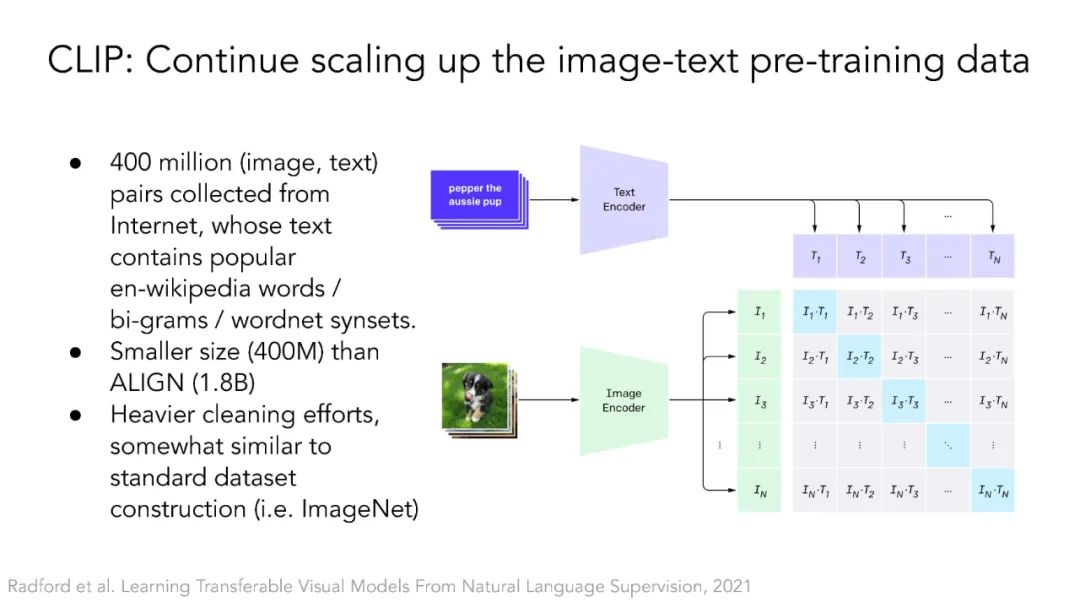
多模态自监督学习。本节将讨论Transformer架构如何弥合视觉领域和自然语言处理领域之间的差距。ViT架构允许使用Transformer基座对不同模态进行多模态学习,如CLIP、LiT、VATT。它还开启了基于NLP领域掩模语言建模思想的自监督视觉表示学习,如BEIT和MAE。







成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
Arxiv
0+阅读 · 2023年4月13日
Arxiv
10+阅读 · 2022年7月30日
相关主题


相关VIP内容
相关资讯